Tutorial Script – Lecture 9: Reward
Date: Wednesday, 17 June 2026
Duration: 90 minutes
Lecture slides: AC_MS_9_PlasticityReward.pdf (old version — verify against new slides)
⚠️ Built from previous year’s lecture PDF — verify against new slides once available
0. Before the Tutorial (prep, not spoken)
What content is in this lecture?
The old PDF (AC_MS_9_PlasticityReward) covers two major topics:
- Plasticity due to training — juggling (Draganski 2004), musicians (Elbert 1995, Schneider 2005), London taxi drivers (Woollett & Maguire 2011), VWFA (Dehaene 2010), Greeble/FFA expertise (Gauthier 1999/2000), learning categories (Kietzmann 2016), cross-modal plasticity (Braille, EyeMusic, rewired ferrets)
- Learning and reward / Temporal Difference Learning — Schultz DA neurons, RPE, Fiorillo uncertainty, actor-critic model, Doya framework (DA = TD error, serotonin = discount, noradrenaline = action sharpness, acetylcholine = learning rate)
⚠️ Note: The lecture PDF title is “PlasticityReward” — it is a combined lecture. The tutorial session is labeled “Reward” for Week 9. Confirm with new slides whether plasticity carries over from Week 7, or whether this session is purely about reward. Focus on the reward half as the novel content for this tutorial.
Likely questions from students:
- “What exactly is the TD error formula and what does each term mean?”
- “What’s the difference between the actor and the critic?”
- “Why does dopamine dip when reward is omitted?”
- “How does Doya map the four neuromodulators to RL parameters?”
- “What does ‘model-free’ vs ‘model-based’ mean for the striatum?”
Known misconceptions:
- Thinking dopamine = pleasure (it codes prediction error, not hedonia directly)
- Confusing CS (conditioned stimulus = cue) with US (unconditioned stimulus = actual reward)
- Thinking dopamine fires more when the reward is bigger — it fires when reward is better than expected
- Assuming the actor-critic are anatomically separate structures with no interaction
- Mixing up dorsomedial (goal-directed) and dorsolateral (habit) striatum
Things to look up again before the tutorial:
- Fiorillo et al. (2003) Science — exact result on uncertainty coding (sustained signal at P=0.5)
- Doya (2002) Neural Networks — the four neuromodulator ↔ RL parameter mappings
- Whether the lecture covers the habit/goal-directed distinction explicitly or only via Doya
1. Opening & Hook (5 min)
You’ve just aced an unexpectedly hard exam. How does that feel — compared to acing an exam you knew was easy? Now flip it: you were expecting an easy A and got a B. Which version of the B feels worse?
What you’re describing is not just about the outcome — it’s about the gap between what you expected and what you got. Your brain has a dedicated circuit that encodes exactly this gap. And it’s dopamine.
Opening question for the group:
“Think of a time you got something you really wanted — but because you’d been waiting for it so long, it felt kind of flat when it arrived. What does that tell you about how the brain processes reward?”
(Goal: build intuition that the dopamine system is not a reward detector but a reward prediction error detector. The anticipation often generates more DA release than the reward itself. Link to Schultz: the DA signal transfers from reward to cue during conditioning.)
2. Link to Last Week (5 min)
Last week: Spatial Navigation — how the brain builds cognitive maps using place cells and grid cells, so we can find our way through environments.
This week: Reward — how the brain evaluates which of those paths and actions are worth taking. Place cells tell you where you are. Reward circuits tell you whether it was worth going there.
More broadly: we’ve covered how the motor system executes actions (spinal cord → cerebellum → BG → motor cortex). Today we ask: why does the system favor some actions over others? The answer is reinforcement learning — and dopamine is the key neuromodulator.
Connection to Lecture 3 (Basal Ganglia): we learned that dopamine from SNc modulates the direct/indirect pathways in the striatum. Today we zoom into what that DA signal actually encodes and how it drives learning.
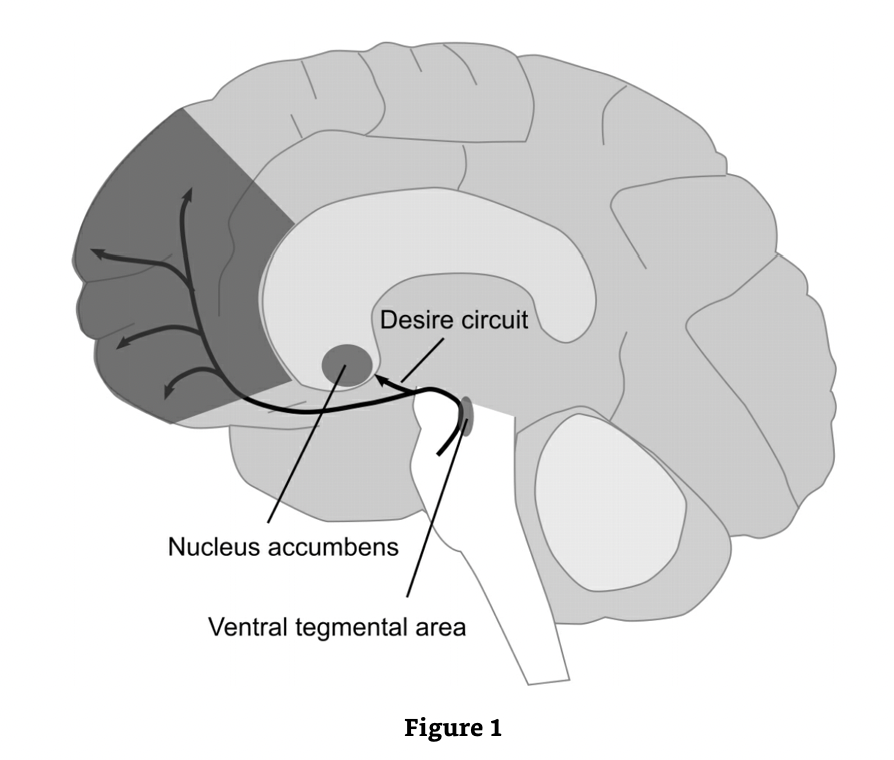
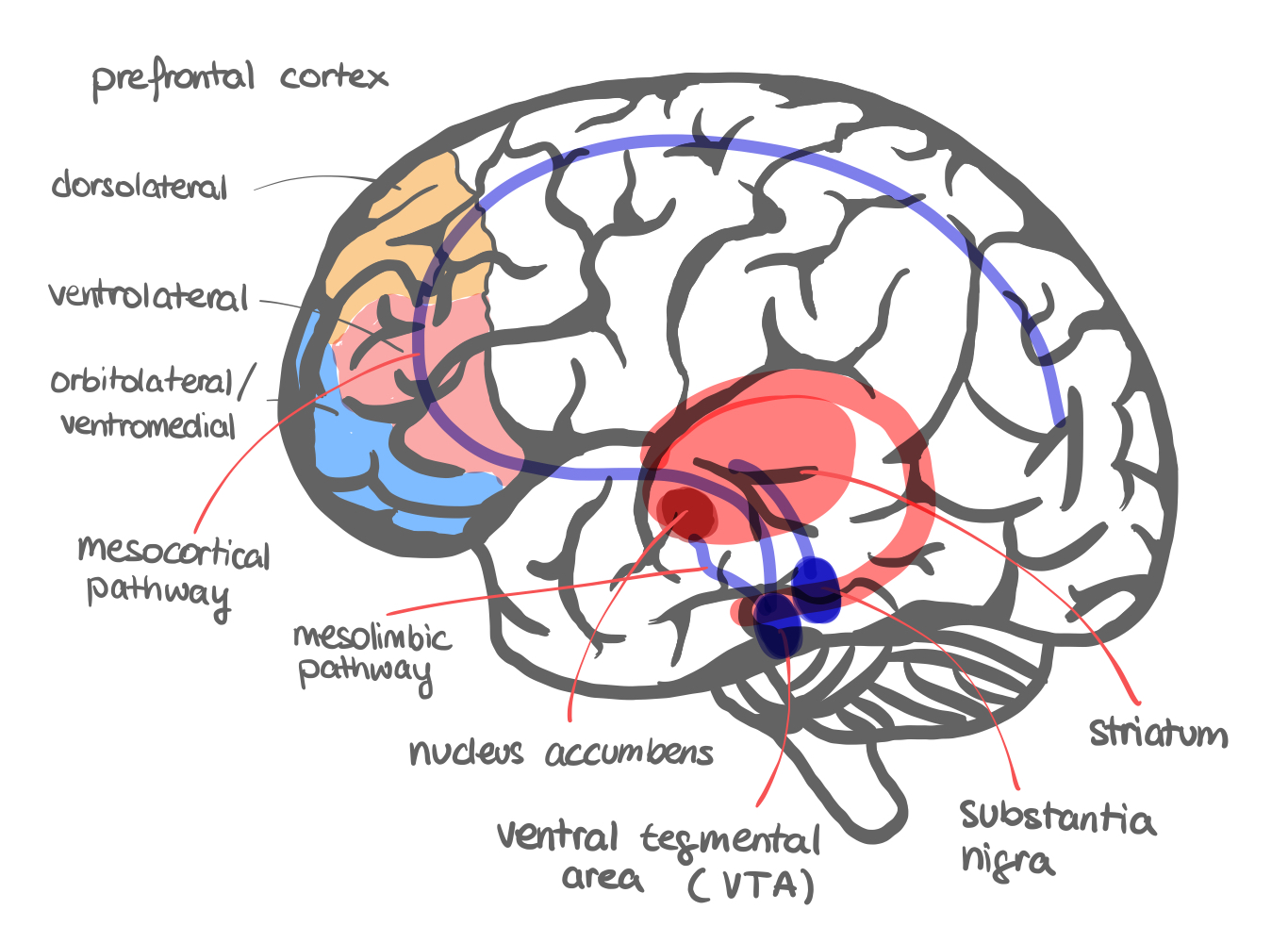
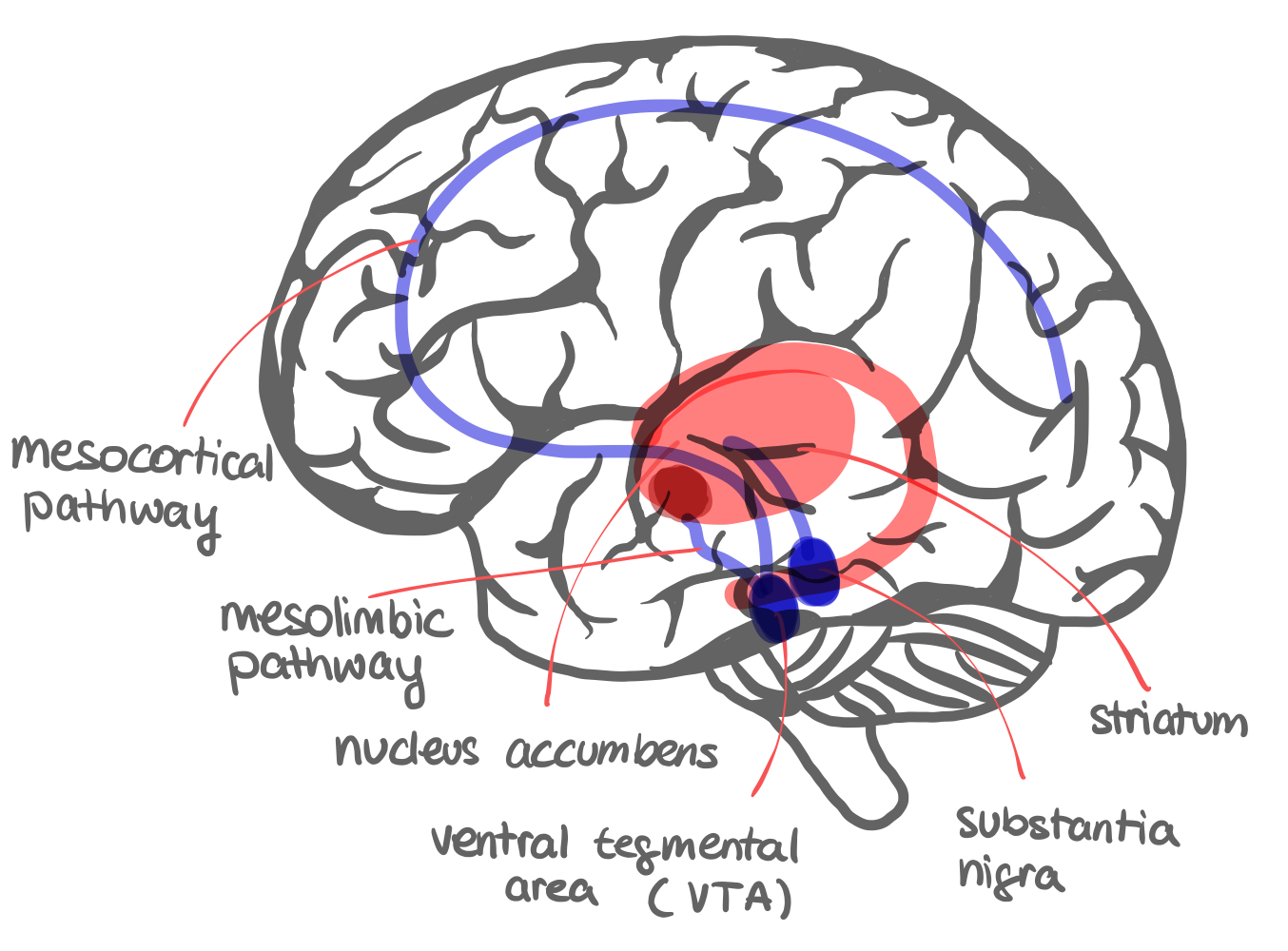
3. The Reward System — Structures (10 min)
Core Message
The reward system is not a new structure — we’ve already met most of it. The key insight is that dopaminergic neurons in VTA and SNc project broadly to the striatum, PFC, and limbic areas, and their firing pattern encodes a learning signal.
Anatomy Quick Map (draw on board)
VTA / SNc (dopamine neurons)
↓ mesolimbic pathway
Nucleus Accumbens (ventral striatum) → motivation, addiction
↓ mesocortical pathway
Prefrontal Cortex → value, cognitive control
↓ nigrostriatal pathway (SNc → dorsal striatum)
Putamen / Caudate → action selection, habit learning
Key facts:
- VTA = ventral tegmental area (A10) → mesolimbic + mesocortical DA
- SNc = substantia nigra pars compacta (A9) → nigrostriatal DA (the pathway lost in Parkinson’s)
- Nucleus accumbens (NAc) = ventral striatum — receives VTA input; critical for motivated behavior and addiction
- Orbitofrontal cortex (OFC) encodes relative motivational value (the raisin vs. apple study from Schultz)
Discussion Questions
- We said the SNc pathway is damaged in Parkinson’s. If DA modulates the direct/indirect pathway, how does reward learning change in Parkinson’s patients?
- The nucleus accumbens receives VTA projections. What does this suggest about why drugs of addiction (cocaine, amphetamine) are so powerful? What do they do to the DA signal?
- The OFC encodes relative value — the same apple was valued differently depending on the alternative. What does this tell you about how the brain represents reward?
Common Misconceptions
- “Dopamine = feeling good” → Dopamine encodes a teaching signal (prediction error), not subjective pleasure (that’s more opioid/endocannabinoid)
- “VTA and SNc do the same thing” → Both release DA, but VTA = mesolimbic/mesocortical (motivation, learning), SNc = nigrostriatal (motor, Parkinson’s relevant)
Exam Relevance
- Exam Q74: “How are rewards processed in the brain?” — Name structures (VTA, SNc, NAc, OFC, striatum), name pathways (mesolimbic, mesocortical, nigrostriatal), explain DA = prediction error signal
- A good answer draws the circuit and labels neurotransmitters
4. Schultz Experiments — Dopamine as Prediction Error (20 min)
Core Message
Wolfram Schultz (1997, and earlier papers back to ~1990) showed that primate DA neurons (VTA/SNc) do NOT simply signal reward — they signal the discrepancy between expected and actual reward. This is the reward prediction error (RPE).
The Three-Stage Story (must be able to draw this!)
Draw on board or have students describe from memory:
Stage 1 — Before conditioning (naive animal):
- Unexpected reward (food) arrives → DA neurons fire
- Cue (CS) → no response
- Reward → big phasic activation
Stage 2 — After conditioning (CS reliably predicts reward):
- CS arrives → DA neurons fire (response transferred to cue!)
- Reward itself → no response (it is now predicted, so no RPE)
Stage 3 — Omission of expected reward:
- CS arrives → DA neurons fire (as expected)
- Reward expected at T+1s but omitted → DA activity dips below baseline at the expected reward time
- This is the negative prediction error
Key formula: δ = r + γV(s') − V(s) — where δ is the TD error (= dopamine signal)
Explanation Approach — Analogies
- The stock market analogy: Dopamine is like your portfolio manager’s alarm. When the stock does exactly as predicted — silence. When it shoots up unexpectedly — alarm (positive RPE). When it drops below expectations — alarm again, but negative. The alarm encodes surprise, not absolute value.
- The timing experiment: DA neurons detect not just whether reward comes but when. If reward is 0.5 s early → burst at 0.5 s, dip at 1 s (expected time). If delayed → dip at 1 s, burst at 1.5 s. The neuron is encoding a prediction in time.
Discussion Questions
- Why is a prediction error signal more useful for learning than a simple reward signal? What would go wrong if DA just fired whenever reward arrived?
- The DA response transfers completely from the US (reward) to the CS (cue) after full conditioning. What would happen if you then present the CS but not the reward multiple times?
- Schultz recorded in VTA/SNc, but the signal is distributed across the striatum and PFC via axonal release. What does it mean that it’s a broadcast signal, not a point-to-point signal?
Common Misconceptions
- “DA fires when you get a reward” → Only if the reward is unexpected. If fully predicted, DA baseline stays flat.
- “The dip below baseline means DA neurons are inhibited” → More precisely: the expected-but-absent reward creates a negative prediction error; tonic DA firing pauses, which is itself informative
- “CS = US in Pavlovian terms” → No: CS = conditioned stimulus (bell/light), US = unconditioned stimulus (food). After conditioning, DA fires to CS, not US.
Exam Relevance
- Exam Q75: “When I expect a reward, is it still a reward when I get it?” — This is the Schultz question. Perfect answer: explain RPE, the transfer of DA firing from US → CS, and what happens at the time the reward was expected if it doesn’t arrive.
- Draw the three-panel figure (naive / conditioned / omission) — König explicitly says a drawing helps
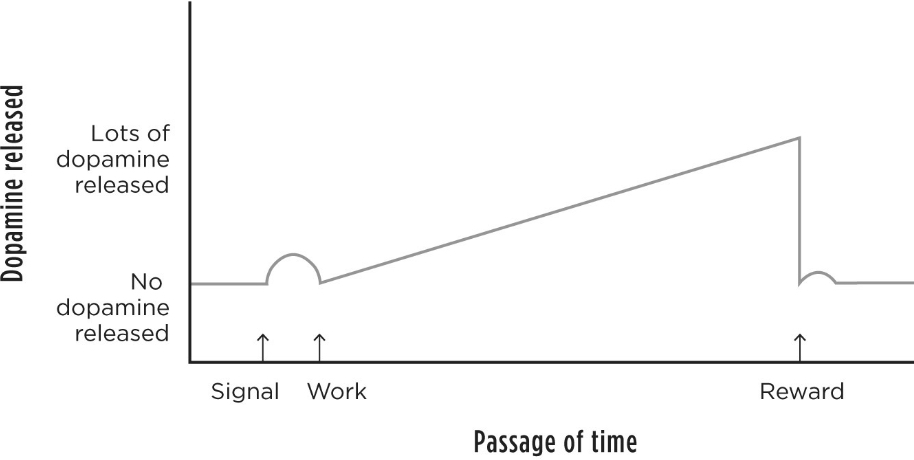
5. Discrete Coding: Probability and Uncertainty (10 min)
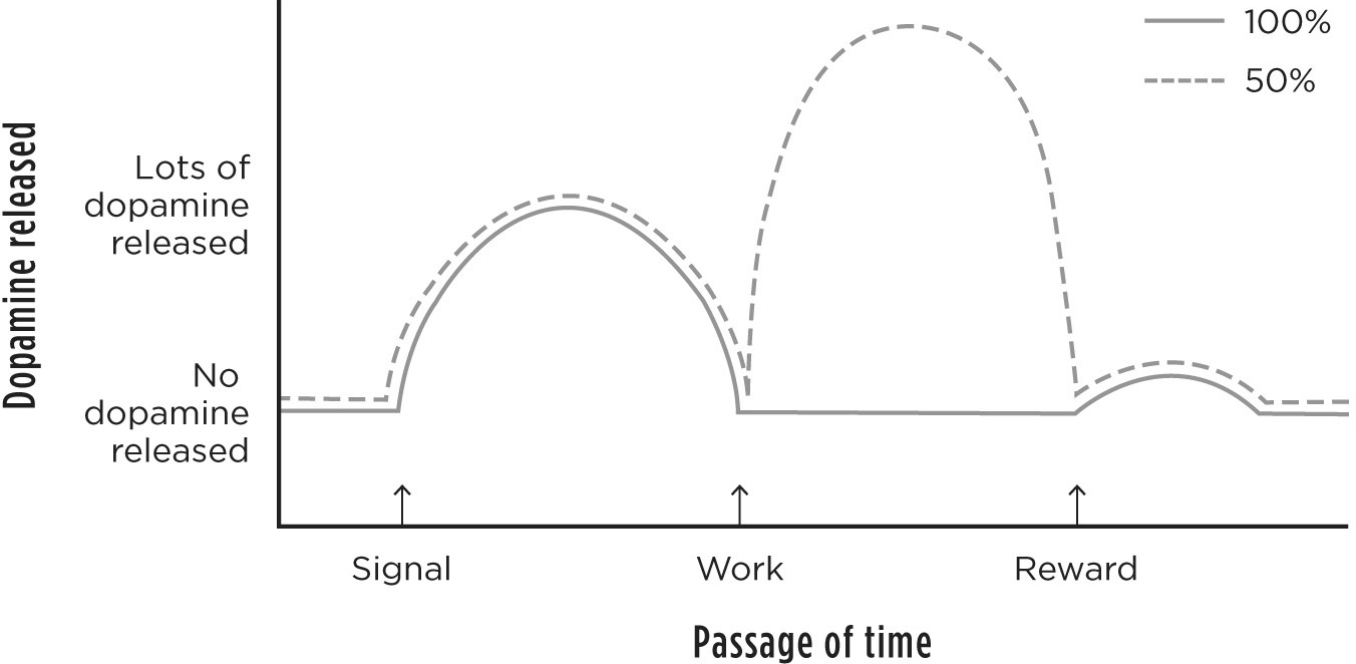
Core Message
Fiorillo et al. (2003, Science) showed that DA neurons encode not just whether reward happens (RPE) but also encode reward probability (phasic signal) and — in a separate component — reward uncertainty (sustained signal maximal at P=0.5).
Key Results
- Phasic DA response (at cue onset) scales monotonically with reward probability: low at P=0.1, high at P=0.9 → codes the expected value and RPE
- Sustained DA activity between cue and reward delivery is maximal at P=0.5 (maximum uncertainty) and decreases toward certainty (P=0 or P=1)
- This sustained component may relate to risk/uncertainty-based learning and attention
Expected value also matters: Tobler et al. (2005) showed that DA population responses track probability × magnitude (expected value). Neurons reflect the combined result of probability and reward size.
Discussion Questions
- Why would the brain want a separate signal for uncertainty, on top of the RPE signal? What behavioral function could the uncertainty signal serve?
- If you give an animal a 50% reward probability, the uncertainty signal is maximal. Is this consistent with the idea of dopamine driving exploration vs. exploitation?
- In the context of addiction — drugs of abuse flood the DA system. How does this interact with the probability and uncertainty coding?
Common Misconceptions
- “Uncertainty coding = prediction error” → They are distinct signals in the same neurons: phasic RPE at cue onset, sustained uncertainty signal during the waiting period
Exam Relevance
- Know the Fiorillo result: phasic DA ~ RPE, sustained DA ~ uncertainty (max at P=0.5)
- If asked about reward coding, mention both components
6. Temporal Difference Learning — The Algorithm (15 min)
Core Message
TD learning (Sutton & Barto) is a reinforcement learning algorithm that formally matches DA neuron firing. The DA signal = TD error δ. This is not just an analogy — it is a quantitative prediction that has held up remarkably well.
The TD Error Formula (write on board slowly)
δ(t) = r(t) + γV(s(t)) − V(s(t−1))
- r(t): reward received at time t
- V(s(t)): estimated future value of current state
- V(s(t−1)): estimated future value of previous state
- γ: discount factor (0 < γ ≤ 1) — future rewards count for less
- δ(t): the TD error = dopamine signal
Intuition: δ is the “surprise” — how much better or worse than expected. If you correctly predicted the future from last step, δ = 0. If something better happened, δ > 0 (burst). If something worse happened, δ < 0 (dip).
Update rule: ΔV(s(t−1)) ∝ δ(t) — update your value estimate in proportion to the error
Actor-Critic Architecture (draw diagram)
Environment → state s(t), reward r(t)
↓
CRITIC: learns V(s) — "how good is this state?"
↓ TD error δ(t)
ACTOR: learns policy P(a|s) — "what should I do?"
↓ action a(t)
Environment
- Critic = striatum (ventral striatum / NAc) + VTA: evaluates current states, computes TD error
- Actor = dorsal striatum + motor cortex: selects actions based on the learned value signal
- DA = TD error signal broadcast from VTA/SNc to both actor and critic
Doya Framework — Neuromodulators as RL Parameters (exam-critical!)
Kenji Doya (2002, Neural Networks) proposed that the four main neuromodulators map onto the key parameters of RL algorithms:
| Neuromodulator | RL Parameter | Interpretation |
|---|---|---|
| Dopamine | TD error δ | Reward prediction error — teaches value |
| Serotonin | Discount factor γ | Time horizon of reward evaluation |
| Noradrenaline | Sharpness β of action | Exploitation vs. exploration trade-off |
| Acetylcholine | Learning rate α | How fast to update from new information |
This is a hypothesis — but one strongly consistent with pharmacological and clinical data. Serotonin drugs affect impulsivity (time horizons), noradrenaline relates to arousal and decision precision, ACh is needed for new learning.
Discussion Questions
- If the discount factor γ → 0, the agent becomes very short-sighted — only cares about immediate reward. Which drug would you expect to shift behavior in this direction based on Doya’s framework?
- In the actor-critic model, if you lesion the critic (ventral striatum), what happens to the actor’s ability to learn new actions?
- Why is it important that the TD error signal is broadcast to both actor and critic simultaneously, rather than being localized to one structure?
Common Misconceptions
- “The discount factor γ means the agent doesn’t care about future rewards” → It means future rewards are discounted, not ignored. γ=1 = equal weight to all future rewards; γ=0 = only immediate reward matters
- “Actor-critic = two separate brains” → They are two functional components that communicate via the TD error signal; they overlap anatomically with striatum
Exam Relevance
- Be able to write the TD error formula and interpret each term
- Name the Doya mapping — this is frequently exam-critical in König’s course
- Draw the actor-critic diagram with the correct brain regions labeled
7. Habit vs. Goal-Directed Behavior (10 min)
Core Message
The striatum is not a uniform structure. Dorsomedial striatum (caudate) supports goal-directed, model-based behavior — flexible, knows the action-outcome contingency. Dorsolateral striatum (putamen) supports habitual, model-free behavior — fast, automatic, but inflexible.
Dopamine from SNc/VTA can shift the balance between these systems.
Explanation Approach
- Goal-directed (model-based): “I press the lever because pressing levers delivers food, and I want food right now.” Sensitive to outcome devaluation.
- Habit (model-free): “I press the lever because I always press the lever here.” No longer sensitive to outcome devaluation. Stimulus → response, bypassing outcome evaluation.
Classic test: Train an animal to press lever for food. Then make the food aversive (pair it with nausea). A goal-directed animal stops pressing. A habitual animal keeps pressing.
Why is this relevant to reward?
- Early learning = goal-directed (dorsomedial, cortical control, model-based TD)
- Extended training = habitual (dorsolateral, subcortical, model-free TD)
- Addiction may represent an extreme form of habit — action no longer under goal-directed control
Discussion Questions
- Addiction is often described as “compulsive behavior despite negative consequences.” How does the habit/goal-directed distinction help explain this?
- Can you think of an everyday example where goal-directed behavior has become habitual? Was the transition useful or did it cause problems?
- How does knowing about the two striatal systems change how you’d think about rehab after a stroke affecting the putamen vs. the caudate?
Common Misconceptions
- “Habit = bad, goal-directed = good” → Habits are highly efficient; the problem is inflexibility. Most skills (typing, driving) are valuable habits.
- “Dorsomedial and dorsolateral are totally separate” → They interact continuously; dopamine modulates the transition between them
Exam Relevance
- Know the anatomical distinction: dorsomedial = goal-directed/model-based, dorsolateral = habit/model-free
- Understand outcome devaluation test as the diagnostic for goal-directed vs. habitual behavior
8. Connection to Basal Ganglia (Lecture 3) — Integration Block (5 min)
This is the synthesis moment — connect back to what students learned earlier.
Draw the big picture on the board:
SNc/VTA → DA signal
↓ (D1 receptors — direct pathway)
Striatum direct pathway → Thalamus disinhibited → Action executed
↓ (D2 receptors — indirect pathway)
Striatum indirect pathway → Thalamus inhibited → Action suppressed
TD error (δ) modulates the strength of direct/indirect pathway synapses
→ Positive RPE: strengthen actions that led to reward (D1)
→ Negative RPE: weaken actions that led to punishment (D2)
The learning interpretation of BG:
- Direct pathway = “do this again” (positive RPE strengthens action)
- Indirect pathway = “don’t do that again” (negative RPE strengthens suppression)
- DA is the teaching signal that tells the BG which side to strengthen
This is TD learning implemented in silicon — or rather, in dopamine.
9. Exam Question Round (15 min)
Question A (from Q74 list)
“How are rewards processed in the brain?”
Expected key points of a good answer:
- Name brain structures: VTA/SNc (DA neurons), nucleus accumbens (ventral striatum), orbitofrontal cortex, dorsal striatum, amygdala
- Dopamine neurons fire to unexpected rewards (Schultz 1997)
- After conditioning: DA transfers from reward (US) to cue (CS)
- Omission of expected reward → DA dips below baseline
- DA = reward prediction error (RPE), not pure reward signal
- Actor-critic framework: critic learns value, actor learns policy; TD error = DA signal
- Optional: Doya framework mapping neuromodulators to RL parameters
Typical mistakes:
- Saying “DA = pleasure/happiness” — this is a common pop-science error
- Forgetting the transfer from US to CS and the omission response
- Drawing structures without labeling pathways or neurotransmitters
- Not mentioning the temporal specificity (timing matters — not just whether but when)
Question B (from Q75 list)
“When I expect a reward, is it still a reward when I get it?”
Expected key points:
- No — in terms of the DA signal, a fully expected reward produces no phasic DA response
- The DA signal encodes the deviation from expectation (RPE)
- The reward still has motivational value (opioid/endocannabinoid hedonic component remains)
- Key: the CS (cue) now generates the phasic DA response instead
- Schultz experiments: after conditioning, DA burst transfers from US to CS
- If expected reward is omitted: DA dips at the expected time — negative RPE
Typical mistakes:
- Saying “no, it’s not a reward” — the reward is still consumed and is still pleasurable; what’s absent is the DA prediction error signal
- Not distinguishing between the hedonic value (wanting/liking) and the learning signal (RPE)
Question C — TD Learning formula
“Write the TD error formula. What does each term represent? What brain signal does it correspond to?”
Expected key points:
δ(t) = r(t) + γV(s(t)) − V(s(t−1))- δ = DA phasic firing
- r(t) = immediate reward at time t
- γV(s(t)) = discounted predicted future value from current state
- V(s(t−1)) = predicted future value from the previous state
- δ > 0: better than expected → DA burst (positive RPE)
- δ = 0: exactly as expected → no change in DA
- δ < 0: worse than expected → DA dip (negative RPE)
- Mention: γ = discount factor (Doya: serotonin)
Typical mistakes:
- Confusing states (s(t) vs. s(t-1)) — the error looks forward, not just backward
- Saying γ is “forgetting rate” — it’s a discount, not forgetting
Closing (3 min)
Take-Home Message:
“Dopamine is not the ‘feel-good’ chemical — it’s the brain’s error signal for learning what to predict and what to do. Every time your predictions are wrong, dopamine teaches your brain to do better next time. This is temporal difference learning in biological hardware.”
Preview of next week — Lecture 10: Social Brain (22 June)
- How do these reward and prediction mechanisms scale to social contexts?
- Mirror neurons (Lecture 5) + reward circuits: how do we learn from observing others?
- Theory of Mind, Sally-Anne test, social decision-making
- Note: 22 June is also the video presentation upload deadline (23:59)
Appendix: Key Papers for This Tutorial
| Paper | Key Finding |
|---|---|
| Schultz et al. (1997) Science | DA neurons in VTA/SNc encode RPE; transfer from US to CS |
| Schultz (2000) Nat Rev Neurosci | Comprehensive review of DA neuron responses |
| Fiorillo et al. (2003) Science | Phasic DA ~ probability (RPE); sustained DA ~ uncertainty |
| Tobler et al. (2005) Science | DA encodes expected value (probability × magnitude) |
| Doya (2002) Neural Networks | Neuromodulators map to RL parameters (DA=δ, 5HT=γ, NE=β, ACh=α) |
| Dayan & Niv (2008) Curr Opin Neurobiol | Actor-critic architecture for RL |
Tags: motorsystem tutor