What is an AI?
How does an AI work? Very simply explained
So let’s explore how an AI works. For this, we are going to make up a problem that the AI should solve:
For the last two weeks, we have left the house and worn the wrong outfit. Either we were freezing, or we were sweating.
We decided to build an AI to predict the correct temperature (in Celsius) outside so we can grab the right jacket for the day.
Sensors we can access:
- air pressure (given in hectopascal hPa)
- humidity sensor (given in percent %)
With these sensors, we get the input data for our AI.
Here is our standard ANN:
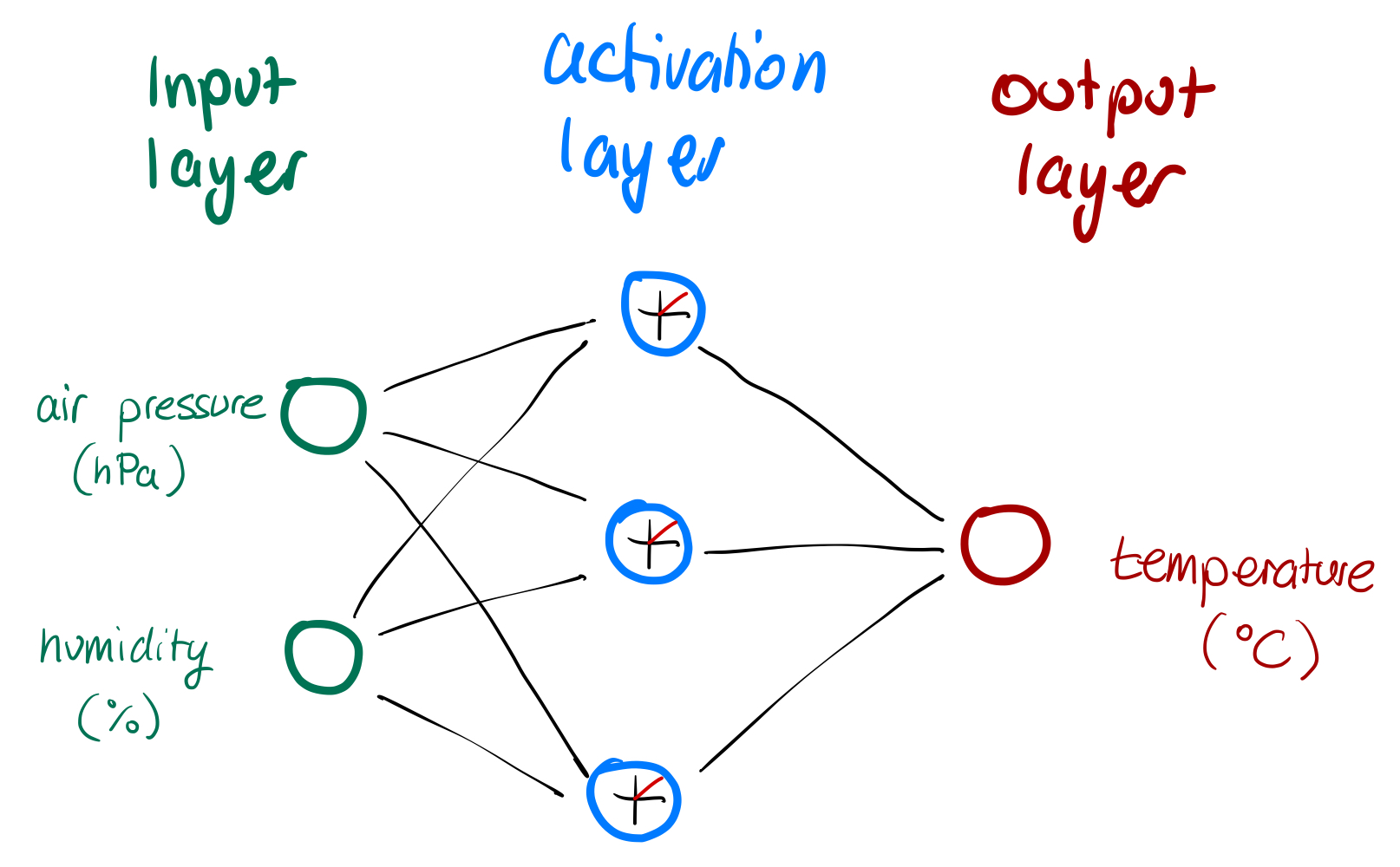
In our standard ANN, we get three essential layers, each consisting of units (2 input units). The lines connecting the units are called weights.
An ANN is called a neural network because it tries to mimic neurons in the brain. This is why Machine Learning engineers also refer to units as neurons. To distinguish them both, I will use the term units.
The input layer:
- receives input (from our sensors)
- air pressure sensor gives a value in hPa (usually between 980hPa and 1040hPa)
- humidity (given in %)
- passes on the values of the sensors to the network
In other use cases, this can be other kinds of data. Like photos, poems, and music. Whatever you want to use the AI for.
Next we have the activation layer:
- receives the input from the input layer (sensory data)
- there are many options to activate a neural path from input to output
- here we use the ReLU function (Rectified Linear Unit). That sounds fancier than it is. It is just a function that passes on the input value from the input layer, but if the input value is below 0, it will just pass on 0. In mathematical terms: f(x) = max(0, x)
Why do we need an activation layer?
- it makes sure the input is suitable for a good prediction of the network
- if the input is not suitable (a negative value) a 0 is passed on, so it does not effect further computations.
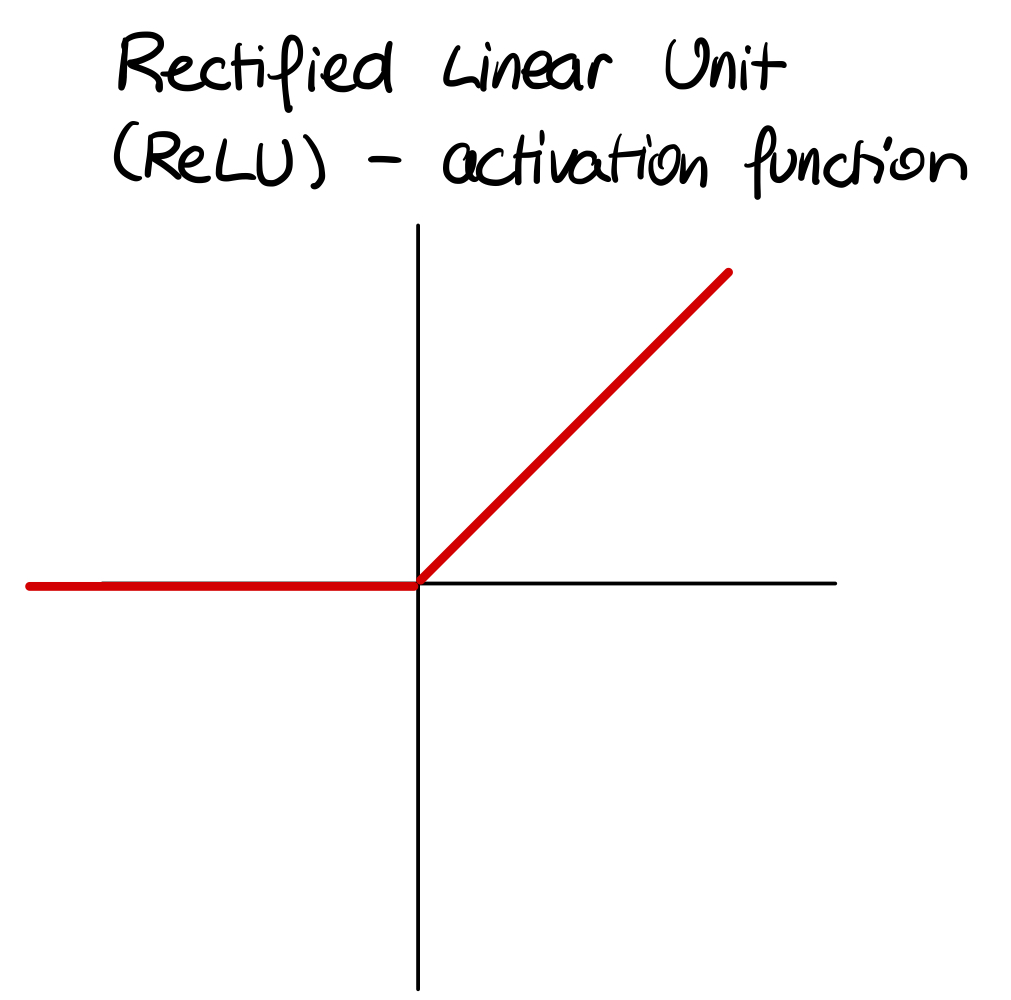
You can see the miniature of the ReLU-function in the activation units above.
Finally the output-layer:
- produces the prediction
- in this case it predicts the temperature in °Celsius (I am European and I will stick to SI measurements. I will not be translating to Fahrenheit)
how does the ANN learns the relationship between air pressure, humidity and temperature?
The two inputs we get have a specific strength of predicting the temperature. But we do not know this strength. It could look like this:
These weights determine how much the input value is passed on to the next unit.
If the input to the activation layer is negative, the activation layer will pass on a 0.
So the air pressure of 991hPa will be passed on as 50% to the top unit of the activation layer. But the humidity will increase by 230%!!
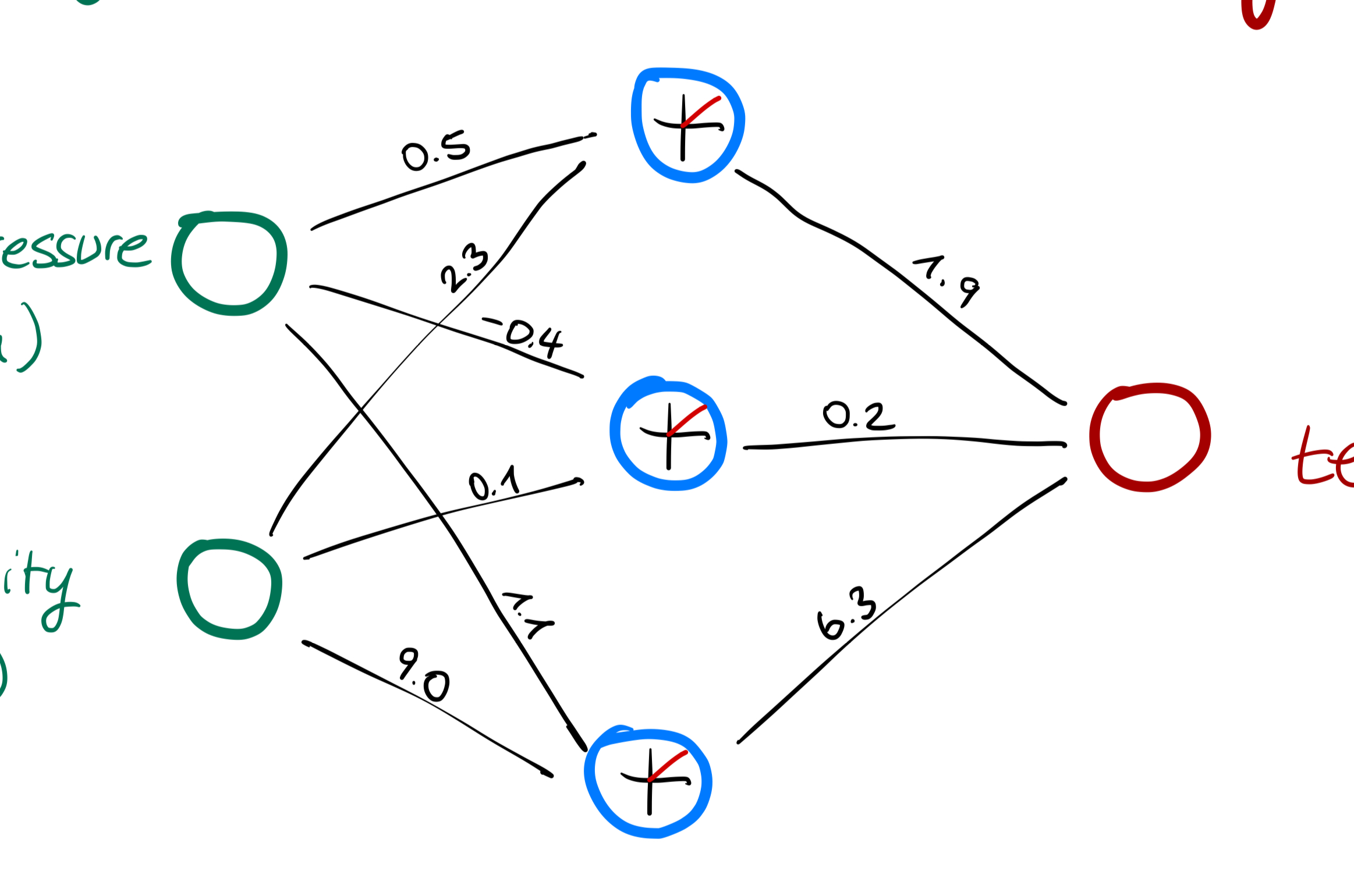
How does the AI come up with the weight values?
Initially, these weights are assigned randomly because we need a starting point. It’s similar to attempting something for the first time: you can’t know if you’re correct unless you try.
Consider the analogy of throwing a ball into a basketball net. How would you know if you need to use less or more strength if you’ve never thrown the ball before? So, you give it a try.
Based on the outcome, you can adjust your strength accordingly and apply less or more strength.
This is very similar to how an AI operates! It just randomly used a random strength to “throw the ball”. Then, the AI can start changing weights (applying less or more strength) the next time.
This adaptation process is also called backpropagation (backward propagation of errors).
What to do with these weights?
Now, with these weights, the AI predicts a temperature of 21°Celsius for tomorrow.
But when tomorrow comes, you realise: No, it’s actually 18°Celsius!
This discrepancy of 3° is called “loss.” The loss value is used to assess the accuracy of an AI model. The AI’s goal is to reduce the loss and improve its prediction.
The more often you check the correct temperature and give the data to the AI, the better it will be at predicting it.
It is similar to how humans do it. We adjust to falsely predicted outcomes and learn to adapt to a new environment.
The difference is that an AI needs thousands of data points to predict something trivial (to us) correctly.
For example, to learn a new letter in a foreign language.
What if you were to learn the Greek letter “ξ” (Xi)? If I show you hand-drawn “ξ”s, you will probably get it right.
But an AI needs to look at the letter ξ many thousand times to get it right.
That’s one of many advantages of our supercomputers between our ears. Take care of it!
How can deep learning help us understand the brain?
see also
Type:
Tags:
Status:
Location:
Created: 11-11-24 20:34
Mein Blog