You Only Live Once, How does Single Life Reinforcement Learning work?
It is easy to take deadly jumps from a cliff if you have endless lives to live. In a simulated world, if you were a robot, you would eventually learn that jumping from heights is dangerous. An AI-driven robot might repeatedly try jumping until it finds the maximum height it can jump from—perhaps it would achieve this with a death count of 134.
Now, let’s consider the fact that the robot has only one life and dies at failure, such as a Mars rover or a disaster relief robot. In the latter case, imagine designing a robot that can rescue people from burning buildings. This capability could save many lives without putting firefighters at risk.
We could allow the robot to train in a simulation, dying many times until it learns the task effectively
However, it’s not feasible to simulate and model every building before the fire breaks out.
Also there will be many unpredictable obstacles inside a building like broken doors or fallen ceilings.
Here is a quick recap on Reinforcement Learning (RL) where a robot makes decisions in an environment to achieve some kind of goal.
You should be familiar with the terms Q-function, policy, state-action, reward and entropy.
https://www.geeksforgeeks.org/what-is-reinforcement-learning/
Usually, in RL, the environment is reset so that the agent can learn repeatedly until it determines the best course of action. This is known as episodic RL.
example of RL and drawing
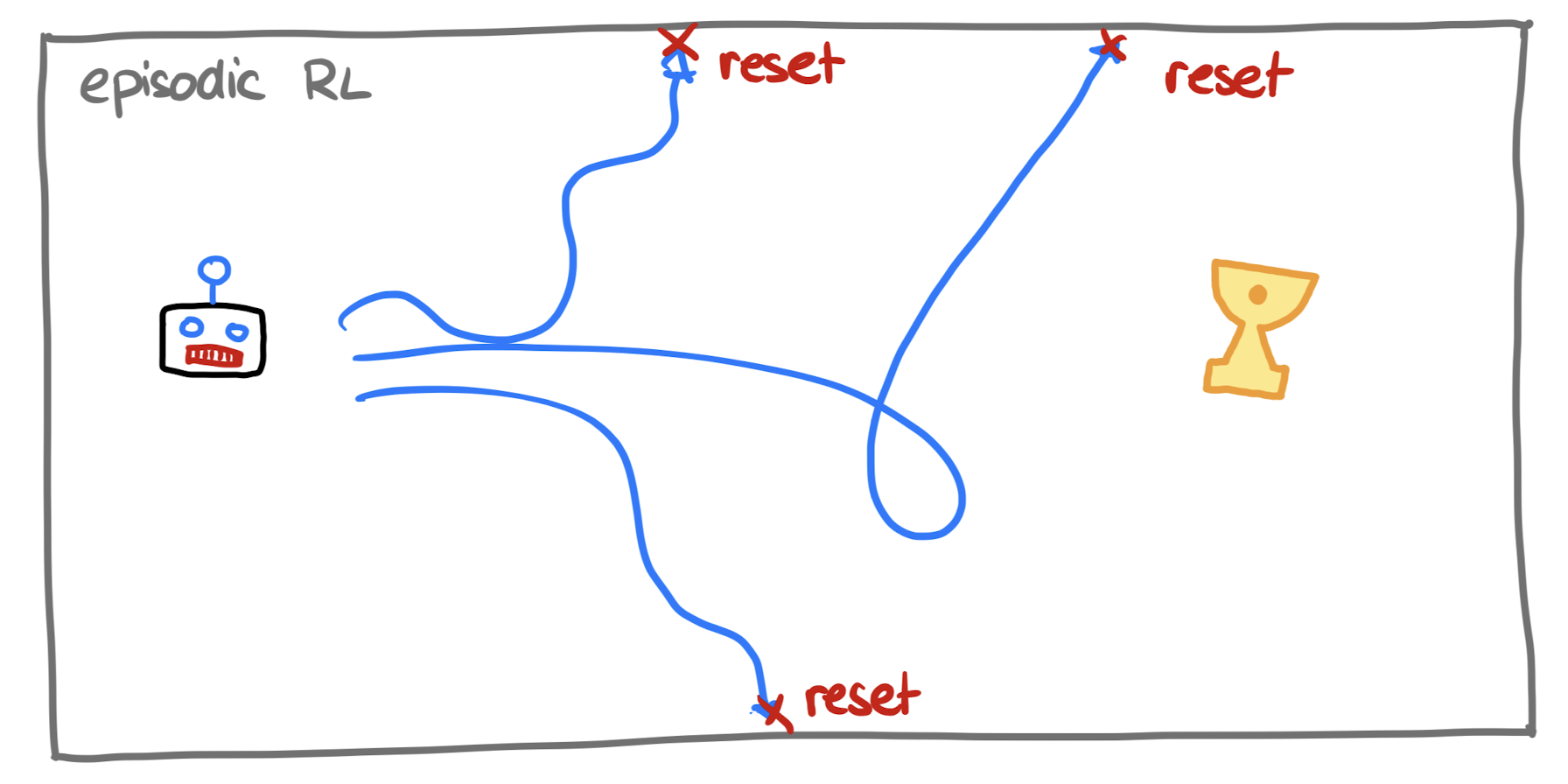
But what if the robot has just a single attempt to complete a task? If it can only die once, we need a strategy for the robot to backtrack when it gets stuck and navigate unknown terrain.
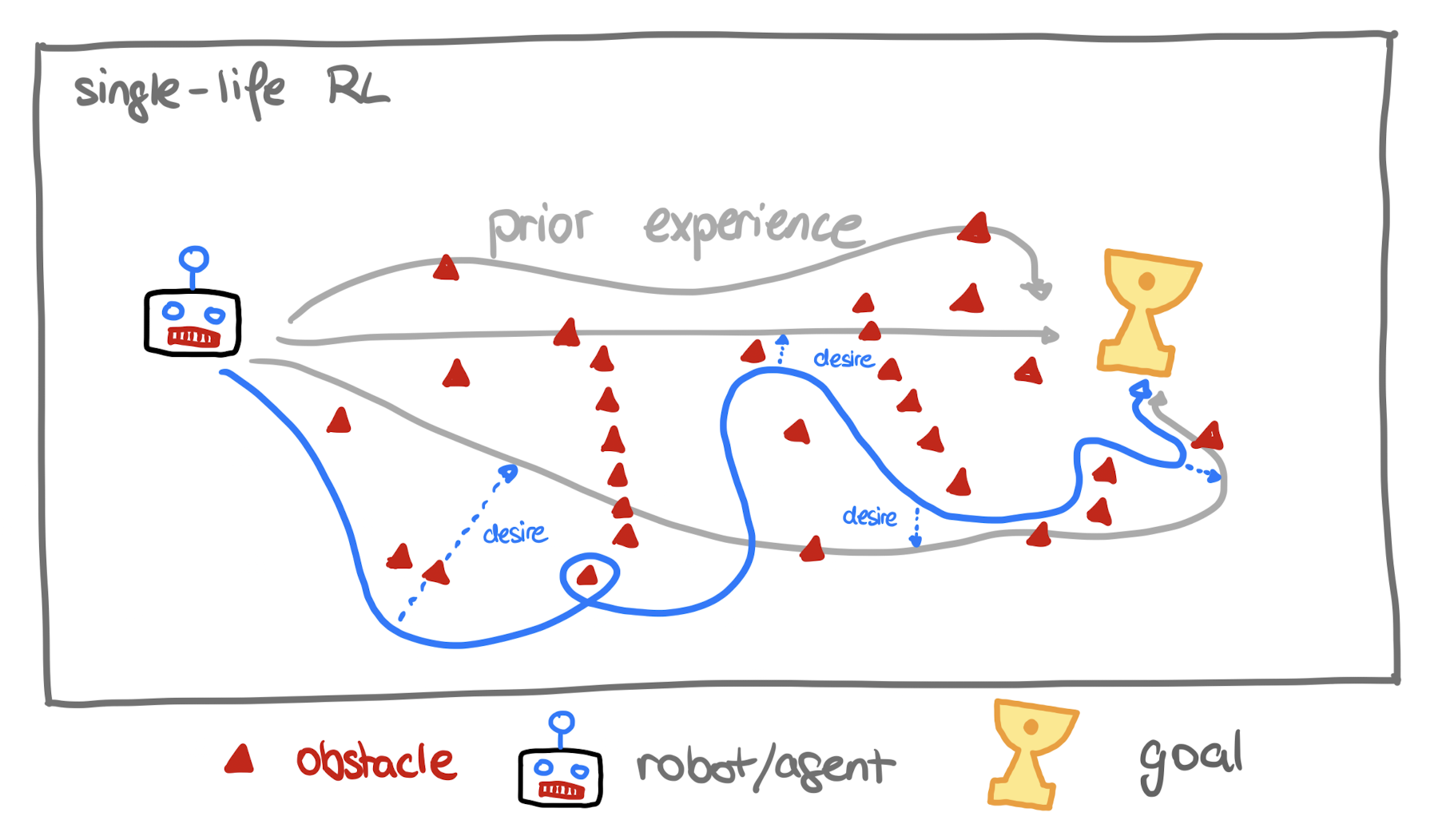
Single-Life-Reinforcement Learning
how does it work?
To begin, the robot is equipped with prior knowledge of disaster relief scenarios where it has successfully achieved its objectives (e.g. saving a little child from a burning house). For instance, it understands how to open doors and climb stairs. However, the researchers provide the robot with suboptimal prior knowledge — lacking expert insights — so that the training mirrors real-life conditions more accurately.
In general, when the robot enters the building, it continuously compares the current policy (state-action pair) with the target policy and takes the best action to achieve the goal (little child).
What does this mean?
The robot’s prior knowledge consists of environments with known rewards stored in its memory. The ultimate reward is finding, for example, a child in the building. The robot receives rewards for actions such as opening doors or moving closer to where it hears cries for help. This is guided by a fixed Q-function , based on a Markov Decision Process.
However, this robot could be in a state far away from anything it remembers.
This is why the robot has a discriminator evaluating the distance between the prior knowledge and the current state.
The discriminator compares the prior distribution (state-action pairs from memory) with the newly acquired information while exploring the building, Donline, using a cross-entropy loss function:
This loss function is used to update the rewards in the environment which could ultimately lead to the robot choosing the best path currently available - often the one closer to the target (little child) - or one that retraces steps from its prior or online knowledge.
Formally, the ultimate goal of the robot is to find a policy (state-action pair) that minimizes the Jensen-Shannon divergence which evaluates the difference between the current and target policy.
https://en.wikipedia.org/wiki/Jensen–Shannon_divergence
(this searching technique used for finding the policy which minimizes is called Generative Adversarial Imitation Learning or GAIL.)
This process leads to what is called Q-weighted adversarial learning (QWALE). QWALE incentivizes the robot to consistently move closer to the pathways that lead to task completion.
Whenever the robot veers off track due to terrain or obstacles, it attempts to return to the best path available for fulfilling its goal.
The objective is not simply to imitate prior data, but to identify the most relevant states from that data for the current situation the robot is facing.
The desired algorithm should be agnostic to the quality of prior experiences;
And the more similar the task or state, the easier the problem.
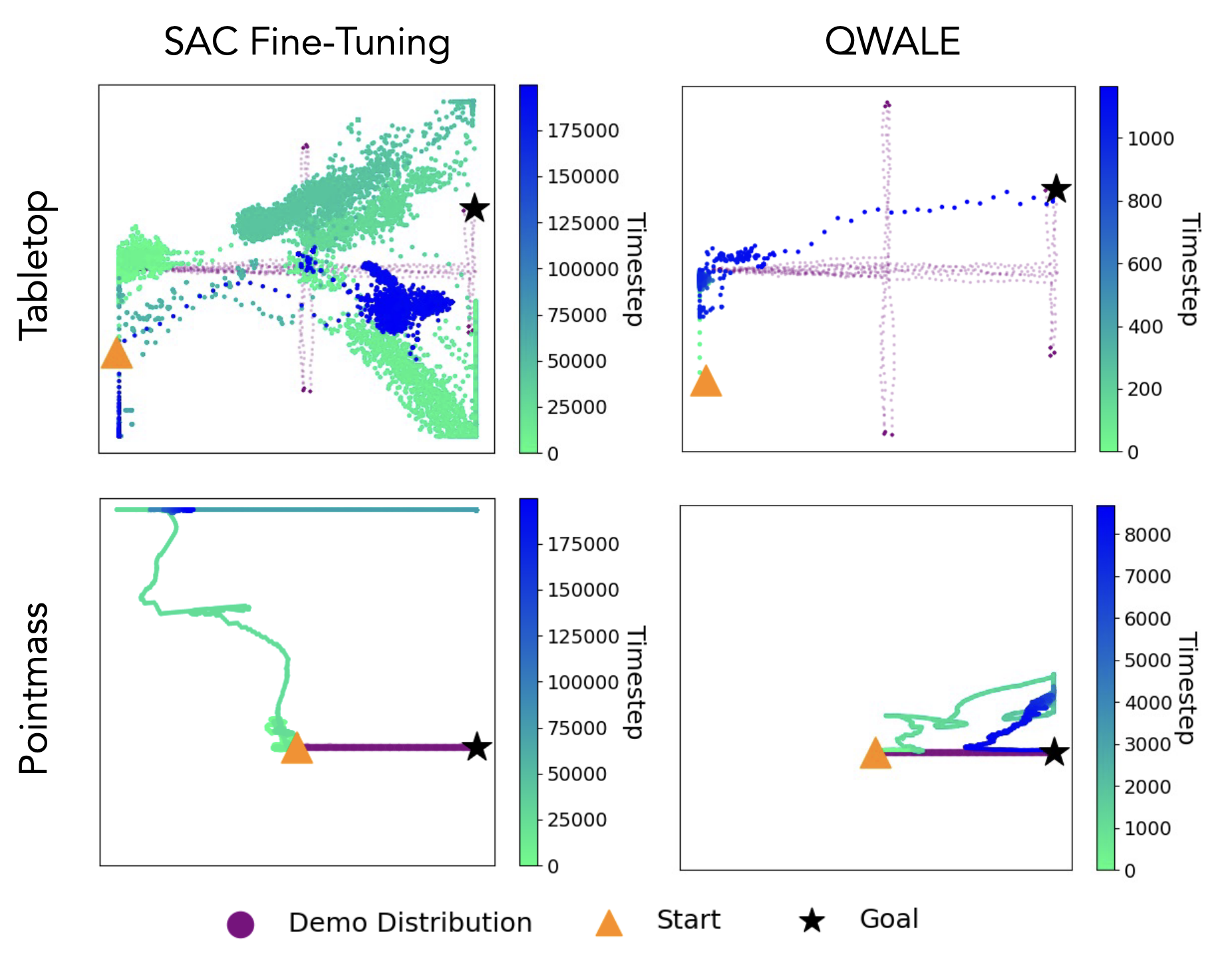
Fig 1 displays the paths the robot has taken showing that QWALE more reliably reaches the target compared to SAC fine-tuning (an algorithm focussing on optimizing performance of existing policies)
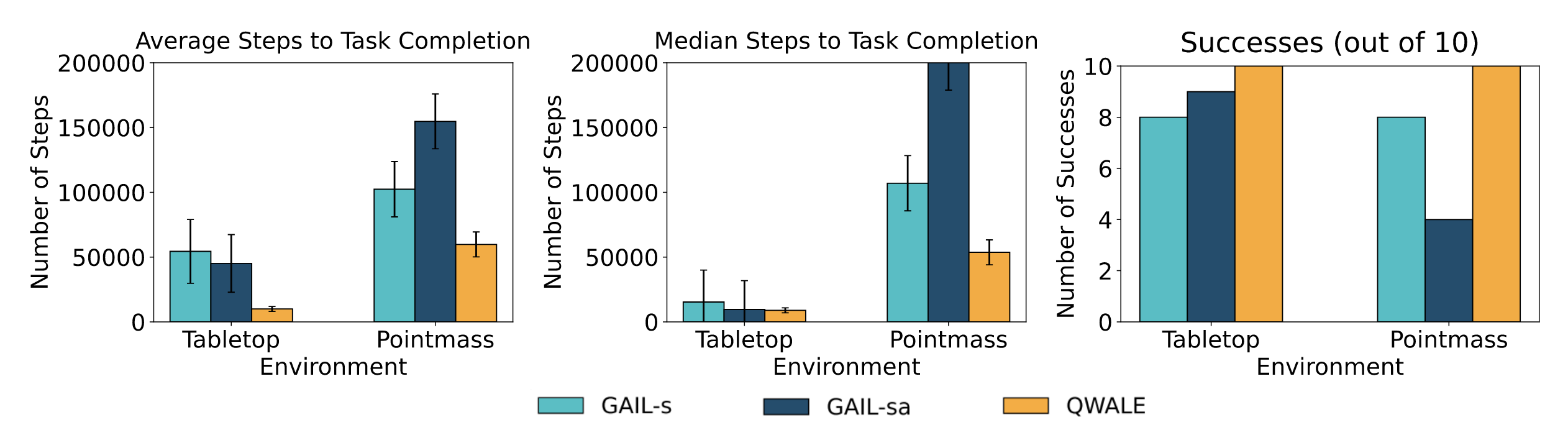
Fig 2 shows that QWALE performs better on all metrics compared to GAIL (mimicking expert behaviour)
Findings
these results show that the additional shaping provided by weighting the prior data by Q-value when training the discriminator can significantly improve guidance towards the goal
QWALE requires 20-40% fewer steps on average than the next best-performing method. These results demonstrate that the additional reward shaping provided by weighting prior data when training the discriminator significantly improves guidance toward the goal.
This suggests that standard fine-tuning using RL does not sufficiently recover from mistakes or trapped situations.
Prior data significantly assist in recovery through reward shaping (discriminator ) and QWALE, which weights the examples by their Q-value.
discriminator
The researchers found that QWALE outperformed other algorithms in four different single-life RL challenges:
- TableTop Organization: Arranging items on a table.
- Pointmass: Rolling a ball through an environment.
- Half-Cheetah Environment: Getting a robotic cheetah to run as fast as possible.
- Franka-Kitchen: Using tools to accomplish complex tasks and planning.
This work demonstrates that prior data can aid robots (agents) in recovery through reward shaping and introduces a novel distribution matching method, QWALE.
Experiments confirmed that distribution matching strategies enhance the use of prior data and that QWALE outperforms previous distribution matching methods.
aussortiert
autonomous RL - going back without reset
Continual RL - lifelong, but similar. without prior knowledge, but the robot keeps learning.
So they use a Markov Decision Process (MDP) that the robot works on. Also this is a reward-driven algorithm. The same as the episodic one. But in areas with sparse rewards where a reset would happen in episodic RL, imitation learning is implemented, even though the prior data might be suboptimal in this state. Called aversarial limitation learning (AIL) which mimimizes the gap between the current state and the prior experience (desire).
- AIL not suficient, because it assumes expert data.
A distribution contains of a policy
So if the robot enters a building, we want the robot to learn stuff like it cannot access the kitchen, so it must find a way around. task rewards
but only learning from task rewards is dificult and might not lead to a result, because those rewards can be very sparse.
to prevent the robot getting stzuck in a sink state, we need some kind of regret mnimization.
We will use the realistic setting called general regret minimization framework
GAIL minizies the difference between the optimal state-action distribution
is the Jensen-Shannon Divergence between the expert data and current state
replace distribution with and therefore reduce to the minimum.
< QWLAE trains a weighted discriminator using a fixed Q-function
so the discriminator cann better distiguish between useful transitions and less useful ones.
the discriminator is also trained with the positive examples comeing from offline data and negative ones from online experience
the goal of the discriminator is, to evaluate whether it believes to get to a better state than the current one, based on prior experience.
this will lead the dicriminator to prefer states that are closer to the goal
Why using a fixed q-function might be useful:
1. Efficient Use of Data:
Leveraging Existing Knowledge: A fixed Q-function might be derived from prior knowledge, such as pretraining on different tasks, expert demonstrations, or simulations. Using this fixed function allows the agent to benefit from previously acquired knowledge without starting the learning process from scratch.
2. Improving Sample Efficiency:
Focus on Relevant Transitions: When training algorithms (like discriminators in adversarial frameworks), having a fixed Q-function allows the model to prioritize learning over transitions that lead to higher expected rewards. This can lead to better utilization of experiences and a more efficient learning process.
distribution matching
Practical implementation
Maximum entropy off-policy RL with the SAC algorithm
discriminator is used to modify rewards when updating off-policy.
- actor and critic initialized with pretrained weights
- replay buffer initialized with offline data
So how good is QWALE the SLRL algorithm?
So the researchers used the algorithm in four different tasks.
I wont explain each task in detail, but I liked a detailed description of each of them:
- TableTop organization
- arranging items on a table
- Pointmass
- ball rolling through an environment
- HalfCheetah environment
- make a robot cheetah run as fast as possible
- Franka-Kitchen
- using tools to accomplish complex tasks and planning
Comparison
fine-tuned with a pretrained policy
see also
Type:
Tags:
Status:
Location:
Created: 25-12-24 18:45
610 🤖Artificial Intelligence, Künstliche Intelligenz
611 📠Machine Learning
Zero-shot adaptation
Maximum entropy off-policy RL with the SAC algorithm
Mein Blog