Questions ML4CCN VL6
How can we make ANN inference more human-like/robust?
“We are raising a generation of algorithms that are like undergrads didn’t come to class the whole semester and then the night before the final, they’re cramming. They don’t really learn the material, but they do well on the test.” - Prof. Efros
How is learning in babies different from ANNs?
- Babies start of with blurry vision while ANNs always get the sharp images
- ANNs get more input data, but babies generalize better and do not remember every image
- ANNs with blurred to high-res images perform the best (overall)
How can we do unsupervised learning with images?
Unsupervised learning with images can be performed in various ways, with the goal of extracting useful representations from image data without explicit labels. Here are some of the key methods and concepts described in the sources:
-
Self-Supervised Learning: Many modern approaches fall into the category of self-supervised learning rather than strictly unsupervised learning. This involves creating artificial labels or tasks to train the network without needing manual annotations. These labels are generated from the unlabeled data. After pretraining using self-supervised methods, the learned representations can be used for other tasks (e.g., classification). This can be advantageous as unlabeled data is often easier and cheaper to obtain than labeled data.
- Distortion: This involves altering images or image patches through augmentations (e.g., rotation, zoom, etc.), and the network learns to predict these changes or restore the original version. The transformed images are treated as a new class, or the network predicts the augmentation value.
- Patches: The network learns to determine the position of image patches or to assemble patches into a full image (e.g., jigsaw puzzle).
- Masking: The network must complete missing parts of an image. This can be done by filling in the masked information.
- Colorization: The network learns to colorize a grayscale image.
- Generative Modeling: Here, the network learns to generate images that resemble the training data. The aim is to find a method that represents images well by discovering the “causes” behind the sensory evidence. The network attempts to reconstruct input data using the learned model, such as through a linear superposition of basis functions. The resulting model should explain the data with as few “causes” as possible.
- Contrastive Learning: This method aims to bring similar image representations together and separate different images. For instance, different augmentations of the same image should result in similar representations, while different images should result in distinct representations.
-
Methods from Early Processing:
- Sparse Coding: This method aims to explain data with as few “causes” as possible. It seeks to find a set of basis functions (Phi) that can well reconstruct the input images. An intuitive way to understand the algorithm is that it searches for a set of basis functions for which the activation values (ai) can be sparsified while minimizing reconstruction error.
- Slow Feature Analysis: This method uses the principle of temporal stability; that is, representations should change slowly as the world changes slowly. It can be implemented using a contrastive learning approach, where closely related frames produce similar representations compared to distant frames.
- Neocognitron: An early multilayered, feedforward CNN-like network inspired by the discoveries of Hubel and Wiesel. The Neocognitron employed local unsupervised learning and did not use end-to-end training.
-
Generative Adversarial Networks (GANs): GANs use two networks, a generator and a discriminator. The generator tries to synthesize realistic images, while the discriminator tries to distinguish between real and synthetic images. This competitive interaction produces impressive synthetic images.
-
Autoencoders and Variational Autoencoders (VAE): Autoencoders learn to compress the input and then reconstruct it. VAEs add a latent variable model, allowing for the generation of new, similar data.
-
Multimodal Learning: Using information from multiple modalities (e.g., image and text, image and sound) can lead to richer representations. This reflects the diverse nature of sensory experience in infants. By integrating different modalities, models can learn statistical relationships, enhancing their performance.
-
Behavioral Relevance and Neural Data: The goal is to develop models that predict neural data well while exhibiting good behavior. This means that the learned representations are useful for task-solving and reflect neural processing in the brain.
-
Feature Visualization and Interpretability: Methods for visualizing learned features help in understanding how neural networks operate. Analyzing individual neuron activations and identifying preferred stimuli (e.g., by optimizing the input image) can reveal what features the network has learned.
In summary, unsupervised learning with images encompasses a variety of methods aimed at extracting useful representations from unlabeled data. These methods range from simple, non-iterative approaches like “imprinting” in the HMAX model to more complex, iterative methods like GANs and contrastive learning. Research increasingly focuses on self-supervised methods, as they leverage the advantages of unlabeled data while providing a form of “supervision” to learn useful representations. An important aspect is integrating biological insights to develop more robust and relevant models. The aim is to create models capable of both performing well and simulating neural processing in the brain.
What does it mean to generate instead of discriminating?
Generating is creating an image or an object from the latent representation while discriminating is differentiating between two inputs and classifying them
preserve information vs sparseness?
The brain is highly efficient and incorporates sparseness constraints. Sparseness leads to less energy consumption and therefore is something nice to have.
but when you create a sparse representation of a stimuli you loose information. that’s why it’s a tradeoff between preserving information and making the representation sparse.
What are good latent representations?
good latent representations encode the input as accurate as possible while requiring less data than the actual input. The latent representation is good if the decoder amanges to replicate the input image just from the latent represerntation.
What are the two loss terms of VAE?
reconstruction loss and KL divergence (making sure it is a normal distribution)
So what is the goal we want to achieve with VAE?
What can you represent with autoencoders which you cannot do with DNNs, diffusion models or RL-algorithms?
In summary, it can be said that autoencoders are particularly well suited for tasks that require unsupervised learning of a compressed representation, feature extraction, and dimensionality reduction. Their ability to learn from unlabeled data and provide a latent representation makes them a valuable tool in various fields. Their strength, therefore, lies in these specific areas where other models may be less suitable.
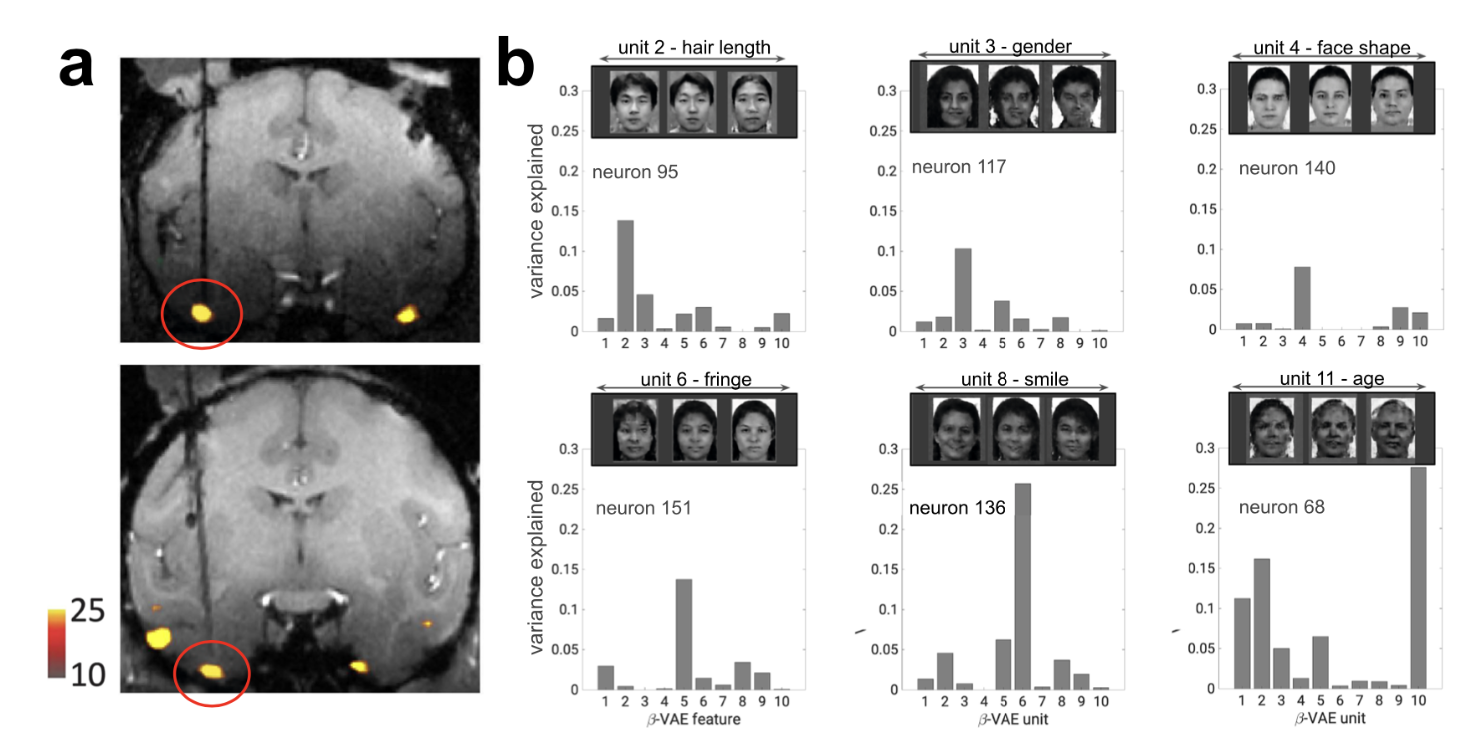
Is “disentanglement” a good normative objective?
Disentanglement can be a valuable goal, especially when interpretability and generalization are important.
However, it’s important to recognize that strict disentanglement is not always necessary or even desirable.
The optimal representation depends heavily on the specific task and context.
The brain might use a mix of disentangled and mixed representations.
It is crucial that a model is positioned at the right level of abstraction to understand the principles underlying brain function and be capable of executing complex tasks.
fragen
how does the optimization problem work?
page 24
why do we want continuous autoencoders? page 30
see also
Type:
Tags:
Status:
Location:
Created: 31-01-25 11:30
Machine Learning for Cognitive Computational Neuroscience