Machine Learning for Computational Cognitive Neuroscience
Ideas for project proposal
softmax like lateral inhibition? I would test that
lateralization would be nice to look at. Models always pretend there is one big brain which only have one full sphere. but what about modeling the hemispheres?
model language acquisition with DeepSeek.
so LLM + RL without prior knowledge
project proposal dopamine gated grid cell navigation
something like more recurrence? double recurrence?
vielleicht passiert einfach mehr auf dem cortical column level und man kann es mit mehr recurrence modeln?
Fragen an Tim
lecture 3 page 41
- how is the noise ceiling determined? is it human performance? yes
lecture 3 page 35
- when should you take the average of all RDMs?
lecture 5 page 32
- why does a V1-structured layer improve noise robustness?
Papers
VL1
Richards - A deep learning framework for neuroscience
Douglas - Cognitive Computational Neuroscience
VL2
Kietzmann - Deep Neural Networks in Computational Neuroscience
Elmoznino - High-performing neural network models of visual cortex benefit from high latent dimensionality
Doerig - The neuroconnectionist research programme
Summary of the week:
Neuroconnectionism and TNNs
VL3
Representational geometry; integrating cognition, computation, and the brain
If deep learning is the answer, what is the question?
Summary of this week:
RDMs and RSA
VL4
Minimal criteria for a sensory encoding model
Summary of the Week:
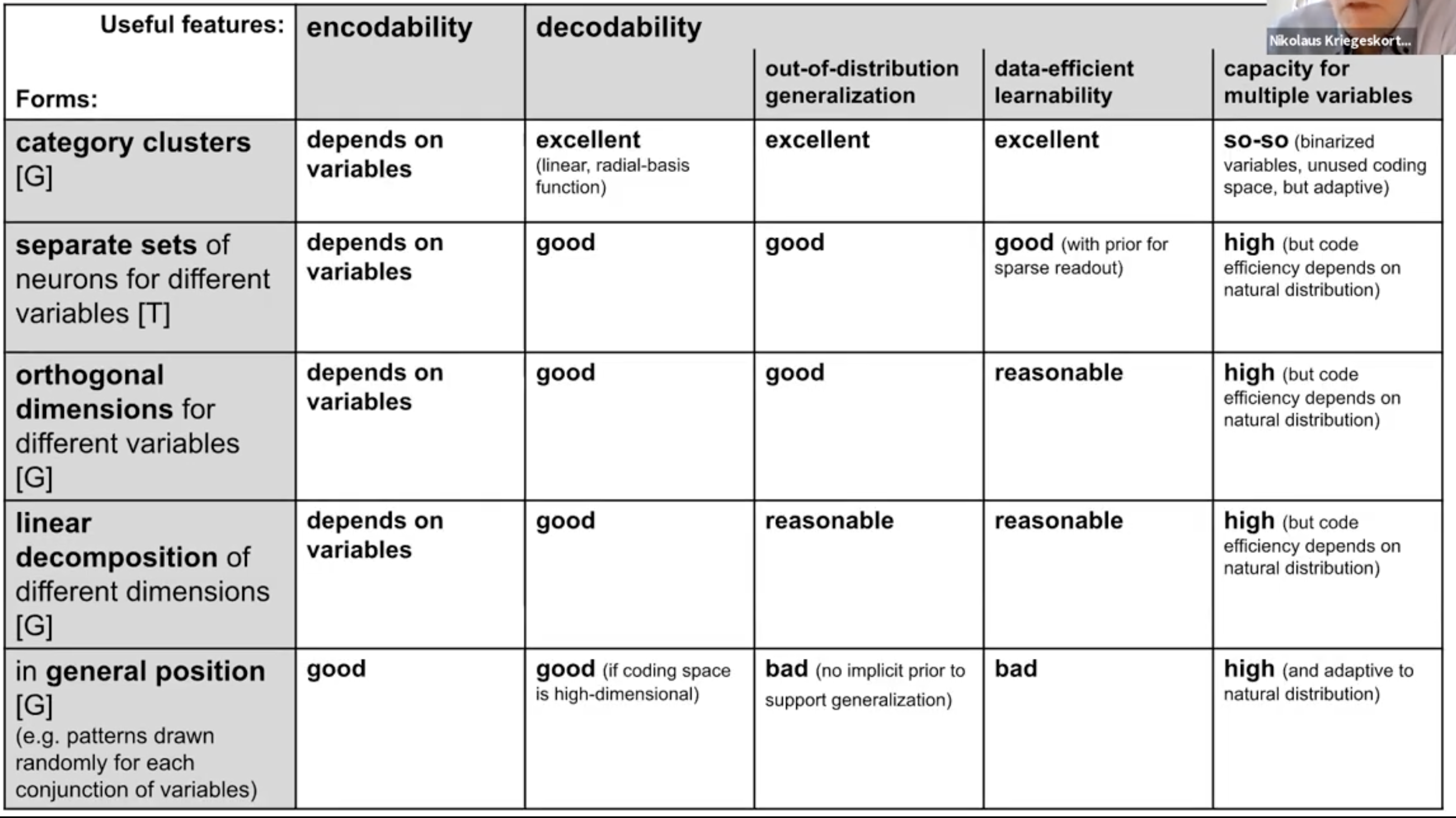
Tuning Curves and decodability
VL5
- If you build a DNN which should predict the activity of a neuron, you cannot make sure that it is in the exact receptive field as you trained the DNN for.
- There could be a spatial gap between the neuron firing and the output layer of the DNN
- The neuron has a certain receptive field which you do not know yet
- so you take the image and vary it in location on a huge grey background as the visual space. therefore you can see where the activation of the DNN best represents the firing of the V4 neuron.
DNNs are very vulnerable to adversarial attacks and you assign “elephant” to a grayish cat, because it rather assigns by texture than by shape.
elicit activity of V4 in monkey
Deep Learning the good, the bad and the ugly
VL6
VL7
interessantes paper:
https://www.tandfonline.com/doi/abs/10.1080/02643294.2012.660138
Fragen
It takes more time to recognize whole pictures than just shapes. ad this is due to the delay the electrochemical signal needs to tranverse through the areas of the visual system.
What about the shortcut to the amygdala for recognizing danger really fast?
Building Machines that learn and think like people
VL8
VL 9
VL 10
Where does attention in transformers come from?
in semantics it’s the best to push objects as far apart from each other as possible
ML4CCN VL10 auditory cortex and semantics
VL 11
Memes ideas

computational neuroscientist
gf: imageNet
other woman: NSD (this better dataset)
Questions from Notebook LM
General Concepts and Neural Connection:
- What is neuroconnectionism, and how does it differ from classical connectionism?
- Explain Marr’s three levels of analysis and why they are important in cognitive neuroscience.
- What desiderata should a good cognitive model fulfill?
- Describe the research cycle of neuroconnectionism.
- How do ANNs (Artificial Neural Networks) fit into testing hypotheses about the brain?
- Why is biological accuracy not always the best approach in brain modeling?
Topography and Self-Organizing Maps (SOMs):
- What are topographical organizations in the brain, and why are they important?
- How do self-organizing maps (SOMs) work?
- How can topographical features arise in TNNs (Topographic Neural Networks)?
- How does a TDANN (Topographic Deep Artificial Neural Network) replicate the organization of the visual cortex?
- What role do spatial constraints play in the formation of streams in the visual cortex?
Few-Shot and Meta-Learning:
- What is few-shot learning, and why is it important for understanding learning?
- What are prototypes and exemplars in the context of few-shot learning?
- What role does representation play in the ability to perform few-shot learning?
- What is meta-learning, and how does it differ from regular learning?
- How can the PFC (prefrontal cortex) function as a meta-reinforcement-learning system?
- What is the role of the dopaminergic system in meta-learning?
Semantics and Language:
- How can we study semantic systems?
- Describe how language models are used to derive semantics.
- Explain the encoder-decoder architecture in language models.
- How does attention work in encoder-decoder models?
- How can we evaluate language models as models of language processing in the brain?
- What role do next-word predictions play in language processing?
Embodiment and Navigation:
- Why is embodiment important for understanding the brain?
- How can body movement influence cortical activity?
- How can ANN models integrate actions and body signals?
- What are the advantages of reinforcement learning for embodied agents?
- What are grid cells and place cells, and what role do they play in navigation?
- How can ANNs be used to model the navigation system?
Supervised vs Unsupervised Learning & Models:
- What is the difference between supervised and unsupervised learning in the context of the brain and ANNs?
- Explain the neocognitron and its significance in the history of neural networks.
- How does the sparse coding model by Olshausen and Field work?
- What are autoencoders, and how are they used for learning representations?
- What are variational autoencoders (VAEs) and why are they better than vanilla autoencoders?
- What is the benefit of self-supervised learning methods for predicting neural data?
- What role does temporal stability play in self-supervised learning?
- What are the characteristics of Ecoset, and how does it differ from other image datasets?
Representational Similarity Analysis (RSA):
- What is representational similarity analysis (RSA), and why is it useful?
- How are representational distance matrices (RDMs) created?
- What different distance measures exist, and how do they differ?
- How are RDMs compared, and what are “noise ceilings”?
- What are the advantages and disadvantages of RSA?
Feedforward Networks and Their Limits:
- What are the successes of feedforward networks in modeling the brain?
- What limits do feedforward networks have?
- What are adversarial attacks, and how do they affect ANNs?
- How can style transfer be used as an experimental probe?
- How do input statistics influence representations in ANNs?
Evolution and Learning:
- Why is it important to consider the role of evolution in understanding the brain?
- What is the argument of “critique of pure learning”?
- How does overparameterization affect learning and generalization in ANNs?
- What is “double descent”?
Recurrent Networks:
- Why is recurrence important in neural processing?
- What are the advantages of recurrent networks?
- How can recurrent models be used to predict time-varying representations?
- What is predictive coding, and how is it implemented in neural networks?
Noise ceilings
Certainly, here are three complex questions about Noise Ceilings, along with bullet-point answers based on the sources:
Question 1: How are Noise Ceilings calculated in Representational Similarity Analysis (RSA) and model evaluation, and why are they important for interpreting model results?
-
Calculation of Noise Ceilings:
- There are two main types: upper and lower bounds.
- The upper bound is calculated as the average distance to the average Representational Dissimilarity Matrix (RDM), representing the best possible model to explain the data.
- The lower bound is obtained through cross-validation, calculating the average distance between the average of N-1 data points and the N-th data point, indicating how well participants predict each other.
- Another method involves subsampling the data and using one participant as the prediction target, with others as source representations, often used in fMRI data analysis.
- To get the most conservative ceiling value, extrapolate the participant group size, using an infinite number of subjects for the final ceiling value.
-
Importance for Interpretation:
- Noise Ceilings indicate how much variance any model can explain given the inevitable noise in biological measurements.
- They normalize model performance by dividing correlation by the Noise Ceiling to show how much of the explainable variance a model accounts for.
- Reaching the lower Noise Ceiling implies a need for better data, whereas failing the ceilings suggests better model development is required.
- The size of the Noise Ceiling is affected by the number of measurements (larger N leads to tighter ceilings) and measurement noise (less noise raises ceilings).
- A low Noise Ceiling is often due to the data being the limiting factor, not the models.
Question 2: Why are Noise Ceilings often lower in language research (e.g., fMRI or ECoG studies) compared to visual research, and what implications does this have for modeling cognitive processes?
-
Lower Noise Ceilings in Language Research:
- Language research often shows lower ceilings due to the higher variability and complexity of language processing.
- Language processing is not strictly bottom-up/stimulus-driven, leading to greater variability in responses.
- Language stimuli, such as sentences or stories, are typically presented only once, whereas visual stimuli are repeated, providing better neural response estimates.
- Language studies often focus on broad distinctions, like the presence or absence of semantic errors, rather than detailed stimulus-based responses.
-
Implications for Modeling:
- Lower ceilings make evaluating performance of language models challenging.
- High signal-to-noise ratio data collection is crucial for reliable neural response estimation.
- The lower ceilings suggest that higher cognitive areas like language are harder to model due to their less stimulus-bound responses.
- This emphasizes the need for better methods for capturing and analyzing language data, and more robust models to handle inherent neural response variability.
Question 3: How do factors such as the number of participants, type of data (e.g., fMRI, ECoG), and experimental design (e.g., number of stimulus repetitions) affect the calculation and interpretation of Noise Ceilings, and what challenges arise from this?
-
Influence of Factors on Noise Ceilings:
- A larger number of participants narrows the Noise Ceiling by reducing variance in estimates.
- Higher-quality data with less noise increases the Noise Ceiling by raising the amount of explainable variance.
- Type of data (fMRI, ECoG, single-cell recordings) significantly impacts ceilings due to different signal and noise characteristics, with fMRI generally having lower signal-to-noise ratios compared to single-cell recordings.
- Number of stimulus repetitions improves neural response reliability, raising Noise Ceilings with more repetitions.
- Experimental design (e.g., tasks, stimuli materials, presentation times) influences data variability and thus the ceiling.
-
Challenges in Interpretation:
- Noise Ceilings are dataset-specific, complicating direct comparison between different studies.
- Reaching a Noise Ceiling does not necessarily mean perfect modeling of neural processing—only maximization of the explainable variance in given data.
- Ceilings can be influenced by systematic artifacts in the data, necessitating careful examination and cleaning.
- Extrapolating the Noise Ceiling to infinite participants is an approximation and may be affected by other factors.
- Estimating Noise Ceilings with natural stimuli (e.g., stories) is challenging due to difficulties in repeated or independent stimulus presentation.
I hope these detailed answers help you understand Noise Ceilings better.
Questions from NotebookLM answered 1
Certainly, here are 100 questions for exam preparation based on the provided sources and our previous conversation, along with their respective answers:
Fundamentals and Concepts
-
What are Marr’s three levels for understanding an information processing system?
- Answer: Computational Theory, Representation and Algorithm, Implementation.
-
What is the Turing Test and why is it used?
- Answer: The Turing Test assesses whether a machine can “think” by competing with a human in an imitation game.
-
What is the goal of the “Direct Fit to Nature” approach?
- Answer: To allow models to directly adapt to the environment, instead of learning explicit, human-interpretable rules.
-
What is “imprinting” in the context of HMAX?
- Answer: A simple, non-iterative method for directly storing input data to learn environmental statistics.
-
What are the main differences between supervised, unsupervised, and self-supervised learning?
- Answer: Supervised learning uses labeled data, unsupervised learning uses unlabeled data, and self-supervised learning generates artificial labels from unlabeled data.
-
What is the difference between a generative and a discriminative model?
- Answer: Discriminative models learn to predict labels, while generative models learn to generate data resembling the training data.
-
What are representation models and what are the three types?
- Answer: Models that make broad predictions about the representation space; Encoding Models, Pattern Component Models, and Representational Similarity Analysis.
-
What is the goal of regularization in complex models?
- Answer: To control model complexity without altering the model itself by influencing “readout”.
- prevent model from overfitting
-
What is the difference between cross-validation and an independent test set?
- Answer: Cross-validation uses part of the data for training, while an independent test set provides an “unbiased” evaluation of model performance.
-
What are metamers and adversarial examples?
- Answer: Metamers are images indistinguishable to a model, while adversarial examples are minimal image modifications causing incorrect classification by the model.
Neural Networks and Deep Learning
-
What are convolutional neural networks (CNNs) and how do they function?
- Answer: Neural networks that use convolution operations to recognize patterns in images, often structured in multiple layers.
-
What are recurrent neural networks (RNNs)?
- Answer: Networks with feedback loops allowing their activation to be influenced by previous inputs.
-
What is the role of backpropagation in training neural networks?
- Answer: An algorithm used to update the weights of a neural network based on the network’s error.
-
What is an activation function in a neural network?
- Answer: A function that applies a non-linear transformation to the output of a neuron in a neural network to generate a new “activation”.
-
What is an encoder and a decoder in an autoencoder?
- Answer: The encoder compresses the input into a latent representation, and the decoder reconstructs the input from this representation.
-
What are generative adversarial networks (GANs) and how do they work?
- Answer: A model that simultaneously trains a generator to create realistic images and a discriminator to distinguish between real and generated images.
-
What are transformer networks and what role does attention play?
- Answer: Models using attention mechanisms to capture dependencies in sequential data (like text) by determining the relevance of each input in the current context.
-
What is one-hot encoding and what is it used for?
- Answer: A representation where each value in the vocabulary gets its own cell in the encoded vector, with the current cell set to 1 and all others set to 0.
-
What is a loss function and how is it used?
- Answer: A function that measures the error between a model’s output and the actual output, used for optimization.
-
What is the significance of weights in the context of neural networks?
- Answer: Parameters learned in neural networks that define the strength of connections between neurons.
Visual Processing and Cognition
-
Which brain areas are crucial for visual processing?
- Answer: V1, V2, V3 (primary visual cortex), and IT (inferior temporal cortex).
-
What role does the IT cortex play in visual processing?
- Answer: It is involved in shape discrimination.
-
What is the importance of representational similarity analysis (RSA)?
- Answer: A method for comparing representations across different systems (e.g., brain and model).
-
What does it mean for a model to be considered a “good fit” for neural data?
- Answer: A model that can effectively predict neuronal activity.
-
What is the role of dopamine in reinforcement learning related to reward learning?
- Answer: Dopamine signals reward prediction errors (RPE) and is a key mechanism in reinforcement learning.
-
What is the difference between model-based and model-free reinforcement learning (RL)?
- Answer: Model-free RL learns directly from experience, while model-based RL learns a model of the environment to make decisions.
-
What is meta-learning in the context of RL?
- Answer: Learning to learn, which is the ability to quickly adapt to new tasks or environments.
-
What are grid cells and what role do they play in navigation?
- Answer: Neurons in the entorhinal cortex showing a grid-like pattern of activity, involved in spatial orientation.
-
What are place cells and how do they differ from grid cells?
- Answer: Neurons in the hippocampus that become active at specific locations, forming a place-specific representation.
-
What are head direction cells?
- Answer: Neurons that show specific activity when an animal faces a particular direction.
Language and Semantics
-
What does the phrase “You shall know a word by the company it keeps” mean?
- Answer: The meaning of a word emerges from its context and the words it co-occurs with.
-
How is the performance of language models evaluated?
- Answer: Through various tasks like next-word prediction, grammaticality judgement, sentiment analysis, etc.
-
What is the goal of semantic encoding in visual processing?
- Answer: A representation of visual inputs that includes the semantic features of seen objects.
-
How can language models be used as models for brain processing?
- Answer: By comparing the neural activations of language models with brain data.
-
What role does context play in language processing?
- Answer: Context helps understand and predict the meaning of words and sentences.
-
What is surprisal?
- Answer: The information a word evokes in the receiver, and thus a measure of a word’s unexpectedness.
-
What is the Universal Sentence Encoder?
- Answer: A model that converts sentences into vectors capturing their meaning.
-
What does “language-selective” mean in the context of brain activity?
- Answer: Brain areas that are particularly engaged in processing linguistic information.
Learning Strategies and Modeling
-
What is few-shot learning?
- Answer: Learning with few examples, often leveraging prior knowledge.
-
What is continual learning?
- Answer: The ability of a model to learn new tasks without forgetting knowledge from previous tasks.
-
What is zero-shot learning?
- Answer: The ability of a model to solve tasks with no prior training examples for those tasks.
-
What is an inductive bias?
- Answer: Assumptions a learning algorithm makes about the structure of the function to be learned.
-
What is the bias-variance dilemma?
- Answer: The need to balance a model’s accuracy on training data with its ability to generalize to new data.
-
What is active learning?
- Answer: A learning process where a model chooses which data to analyze.
-
What is curriculum learning?
- Answer: A learning process that starts with simple examples, gradually using more complex ones for training.
-
Why is overfitting a problem when training neural networks?
- Answer: It means the model learns the training data too well and cannot generalize to new, unseen data.
-
Why are tasks important for cognition research?
- Answer: They allow for the quantitative study of cognition in a controlled environment.
-
What role does the environment play in learning a model?
- Answer: The environment is a significant factor influencing a model’s development and performance but is not one of the model’s main components.
-
What is the purpose of in-silico experiments?
- Answer: To explore models through simulations to better understand and test them.
-
What does it mean for a model to learn robust representations?
- Answer: That the model still performs adequately despite noise or other input data disturbances.
Specific Simulations and Experiments
-
What was shown in Simulation 1 of the DeepMind Meta-Learning paper?
- Answer: That the PFC integrates action and reward information to construct a choice value.
-
What is the “Inferred-Value” effect from Simulation 3?
- Answer: A change in DA signals following a reward reversal, reflecting an inference about the value of other goals.
-
What was shown in Simulation 4 and what was the template for this simulation?
- Answer: Behavior in a two-step task based on Miller et al.
-
What was shown in Simulation 5?
- Answer: That Meta-RL can learn in a 3D environment.
-
What was shown in Simulation 6?
- Answer: The impact of optogenetic stimulation on RPE signals in the context of a risk/reward task.
-
What was the goal of the experiment with “fake” goal grid codes in the DeepMind Grid Cell Paper?
- Answer: To show that the goal grid code provides enough information for the agent to navigate to any target location.
-
What did the experiments with stochastic doors in the DeepMind Grid Cell Paper investigate?
- Answer: The agent’s ability to generalize to a new environment with changing doors.
-
What is the purpose of masking units in the Goal Grid Code?
- Answer: To investigate the importance of grid cells and ensure the model does not navigate through just a few activated cells.
-
What were the key findings of the experiments with “adversarial” attacks on neuronal representations in the IT cortex of primates?
- Answer: That the preference of individual IT neurons can be overridden by “adversarial” changes to an image, and that it’s harder to influence biological neurons than artificial neurons in neural networks with adversarial attacks.
-
What was the outcome regarding humans’ ability to perceive the adversarial changes to images?
- Answer: That the adversarial changes to images are hardly perceptible to humans.
Methods and Experiment Design
-
What is the purpose of a “Reporting Summary” in scientific publishing?
- Answer: To improve the reproducibility of research.
-
What statistical parameters should be provided in a scientific publication?
- Answer: Sample size (n), the test used, one-tailed or two-tailed testing.
-
Why should multiple replicates be used in experiments?
- Answer: To verify the robustness of the results.
-
What role does sample size play in an experiment?
- Answer: An adequate sample size is necessary to account for variability in the configuration of the environment.
-
What are bootstrapped samples?
- Answer: Resampling methods to capture the variability of estimates.
-
What does it mean if a test is one-tailed or two-tailed?
- Answer: One-tailed tests for a change in one direction, while two-tailed tests for changes in both directions.
-
What are Pearson correlation coefficients and what are they used for?
- Answer: A measure of the linear relationship between two variables, often used to measure representational similarities between different systems.
-
What does “p < 0.05” mean in a statistical test?
- Answer: That the result is statistically significant, with the probability of the result being due to chance being less than 5%.
-
What is MSE in relation to a model?
- Answer: Mean Square Error, a measure of the average squared deviation between a model’s predictions and actual values.
-
What is an RDM?
- Answer: Representational Dissimilarity Matrix, which quantifies differences in the activity of neurons or models for different stimuli.
Theoretical Background and Discussion
-
What does the phrase “What I cannot create, I do not understand” mean?
- Answer: A statement emphasizing the importance of constructing models to understand a phenomenon.
-
What is the difference between explaining and predicting?
- Answer: Explaining refers to understanding mechanisms, while predicting aims to forecast future events.
-
Why might simple models be insufficient to explain complex intelligence?
- Answer: Because intelligence requires extensive world knowledge and sufficient parametric complexity to store this knowledge.
-
What role do objective functions play in the context of brain models?
- Answer: Objective functions can drive learning in models and be aligned with biologically plausible goals (e.g., homeostasis).
-
What is predictive coding?
- Answer: A model suggesting that the brain constantly makes predictions and attempts to minimize prediction errors.
-
What does it mean to say that ANNs are “transparent boxes”?
- Answer: Unlike “black boxes,” they allow the examination of each neuron’s activity and connections.
-
What are the goals of neuroconnectionism?
- Answer: To specify what computations the brain performs, show how these computations lead to testable behavior and neural activity, also in complex environments.
-
What is a “lottery ticket” in the context of neural networks?
- Answer: The theory that small networks, found through a “lottery principle,” can achieve good performance.
-
How is the “gridness score” calculated?
- Answer: By analyzing the spatial autocorrelogram of the activity map (ratemap).
-
What is the significance of temporal stability in the context of learning?
- Answer: An idea used in unsupervised learning where representations should change gradually if the world changes gradually.
Course-Related Questions
-
How many ECTS can be acquired in this course?
- Answer: 8 ECTS.
-
How many hours of work are estimated for this course?
- Answer: 200 hours.
-
How is the weighting of each component of the final grade?
- Answer: Project Proposal (25 points), Workgroup Summaries (45 points), Final Exam (30 points).
-
What are the tasks in the workgroups?
- Answer: Discussions and summaries about current scientific publications and lectures.
-
What is the purpose of the project proposal?
- Answer: To demonstrate deep thought about a topic of the course.
-
What type of exam will take place at the end of the course?
- Answer: A multiple-choice exam.
-
What should be considered when using AI tools like chatbots in dealing with course materials?
- Answer: Developing your own thoughts and avoiding copying text from other sources to not undermine your learning success.
-
Where are the course materials provided?
- Answer: On StudIP.
-
Why is it important to ask questions during the lectures?
- Answer: To clarify doubts and benefit from others’ perspectives.
-
Why are the workgroups a part of the course?
- Answer: To enable deeper discussions about course topics and learn about current research.
Application-Based Questions
-
How can neural networks be used as scientific models?
- Answer: To simulate complex mechanisms implemented by the brain and compare them with experimental data.
-
How are neural networks used in image processing?
- Answer: For object recognition, classification, and segmentation.
-
What is the use of neural networks in language processing?
- Answer: To understand language and generate text.
-
How are neural networks employed in reinforcement learning?
- Answer: To make decisions in an environment to maximize a reward.
-
What role do neural networks play in understanding spatial navigation?
- Answer: They are used to model the activity of grid cells and place cells.
-
What are potential ethical concerns with using neural networks?
- Answer: Possibility of AI use for plagiarism, model biases, use of AI for military purposes, etc.
-
What role can neural networks play in medicine?
- Answer: They can be used for analyzing medical imaging data, simulating drug effects, and studying disease mechanisms.
-
What practical applications exist for generative models?
- Answer: Synthesizing images, text, and other data, creating new designs, developing creative tools, etc.
-
How is the “Universal Sentence Encoder” related to neural models of language processing?
- Answer: It can be used to predict and compare activities in human brain areas during language processing.
-
How can deep learning be used to create “Brain Scores”?
- Answer: By comparing individuals’ brain activities with the model to provide a “score” reflecting performance.
I hope these questions aid in your exam preparation! Good luck!
Questions from NotebookLM answered 2
Certainly! Here are 100 questions for exam preparation based on the provided sources and our previous conversation, including answers. The questions cover various topics and concepts to test your understanding of cognitive and computational neuroscience.
Exam Preparation Questions and Answers:
-
Question: What are the three levels of analysis proposed by David Marr to understand cognitive systems?
Answer: Computational, algorithmic, and implementational. -
Question: What is the main goal of neuroconnectionism?
Answer: The main goal is to create connections between brain activity, behavior, and artificial neural networks to understand how the brain functions. -
Question: Explain the importance of cross-validation in model evaluation.
Answer: Cross-validation helps assess a model’s ability to generalize to unseen data and avoid overfitting. -
Question: What is representational similarity analysis (RSA)?
Answer: RSA is a method to compare similarities in patterns between brain data and model data to infer representations. -
Question: What are metameric stimuli in the context of neural networks?
Answer: Metamers are stimuli that appear identical to a model, although they may differ for humans. -
Question: What are “adversarial examples” and why are they important?
Answer: Adversarial examples are minimal changes to input data that cause a model to make incorrect predictions, highlighting a model’s vulnerabilities. -
Question: What role does the “next-word prediction” task play in evaluating language models?
Answer: “Next-word prediction” evaluates how well a language model can predict the next word in a sequence, serving as a measure of language understanding. -
Question: What is meta-reinforcement learning (Meta-RL)?
Answer: Meta-RL is learning how to learn, focusing on developing algorithms that can quickly adapt to new tasks. -
Question: What is the difference between ideal-fit and direct-fit models?
Answer: Ideal-fit models aim to identify the underlying generative rule, while direct-fit models are directly adjusted to the data without assumptions about the true generative rule. -
Question: Why is a control condition important when testing the effect of a lesion on a navigation model?
Answer: A control condition allows for identifying specific effects of the lesion rather than only observing catastrophic errors. -
Question: Name three types of analysis in representational models.
Answer: Encoding models, pattern component models, and representational similarity analysis (RSA). -
Question: What is the difference between supervised and self-supervised learning?
Answer: Supervised learning uses labeled data, while self-supervised learning trains models by deriving labels from the data itself. -
Question: What is a “reward prediction error” (RPE)?
Answer: An RPE is the difference between the expected and the actual reward received. -
Question: Why are tasks important for studying cognition?
Answer: Tasks provide a controlled environment to quantitatively study cognition. -
Question: Describe the “searchlight” approach in fMRI analysis.
Answer: The “searchlight” approach analyzes fMRI data in local, spherical volumes to investigate representational geometry. -
Question: Name the main goals of neuroconnectionism.
Answer: The main goals are:
* Determining the computations of the brain
* Linking computations to behavior and neural dynamics
* Applicability in complex environments. -
Question: What is “biased competition” and how is it related to “divisive normalization”?
Answer: “Biased competition” is a model where objects compete for attention. “Divisive normalization” is a mathematical model that implements this. -
Question: In what context is Meta-RL used in the sources?
Answer: Meta-RL is used in the context of reinforcement learning to improve the ability to quickly adapt to new tasks. -
Question: What is the Turing Test and what does it assess?
Answer: The Turing Test assesses whether a machine can exhibit human-like behavior. -
Question: Why are overparameterized models useful even though they are hard to interpret?
Answer: They allow for solving complex tasks and storing large amounts of information. -
Question: What is the bias-variance tradeoff?
Answer: The bias-variance tradeoff describes balancing between fitting training data (bias) and generalizing to new data (variance). -
Question: What is the “inner loop” of visual processing?
Answer: The “inner loop” is a recurrent network deciding which computations to perform to reduce uncertainty. -
Question: What is the “encoding model approach”?
Answer: The approach uses linear regression to map model representations onto brain representations. -
Question: What is the “Psychlab framework”?
Answer: The “Psychlab framework” is a platform for creating experiments with visual stimuli in a 3D environment. -
Question: What is a generative model?
Answer: A generative model is used to generate new data points resembling the training data. -
Question: How are “Reward Prediction Errors” (RPEs) used in Meta-RL?
Answer: RPEs are used in Meta-RL to direct the actor and evaluate the effectiveness of the last action. -
Question: What is a “ratemap”?
Answer: A ratemap is a visual representation of a cell’s average firing rate concerning positions in space. -
Question: What is the difference between “model-based” and “model-free” RL?
Answer: “Model-based” RL uses a model of the environment, while “model-free” RL learns directly from experience. -
Question: What is the Gridness-Score?
Answer: The Gridness-Score quantifies the hexagonally regular activity of grid cells. -
Question: What does the “Softmax” function do in the context of a probability distribution?
Answer: “Softmax” converts a neural network’s output into a probability distribution where the outputs sum to 1. -
Question: Explain the function of dopamine in the context of “Reinforcement Learning” (RL).
Answer: Dopamine conveys reward prediction errors, driving learning in RL. -
Question: What are the fundamental components of a “transformer” model?
Answer: “Query”, “key”, and “value” vectors are crucial for calculating attention. -
Question: Why do we use “one-hot encoding” for processing text data in neural networks?
Answer: “One-hot encoding” represents words as distinct vectors, with a 1 at the position corresponding to the word and 0 elsewhere, making them processable by neural networks. -
Question: What is a “loss function” in training neural networks?
Answer: A “loss function” measures the difference between a model’s prediction and the actual value and is crucial during training. -
Question: What is the purpose of “backpropagation” in training neural networks?
Answer: “Backpropagation” is an algorithm used to adjust the weights of a neural network based on errors in predictions. -
Question: What is “curriculum learning” and how does it work?
Answer: “Curriculum learning” is a training approach where a model is trained first on simpler and then on more complex tasks. -
Question: How do accuracy and “overfitting” relate to model complexity?
Answer: As model complexity increases, training data accuracy may rise, but the risk of “overfitting” also increases, leading to poor generalization to new data. -
Question: What role does “sparsity” play in representations emerging from reinforcement learning?
Answer: “Sparsity” leads to more meaningful and interpretable representations, as only relevant information is represented. -
Question: What is the significance of “transfer learning” in deep learning models?
Answer: “Transfer learning” allows applying knowledge learned from one task to another task, reducing training time and improving performance. -
Question: What is the role of “attention” in “transformer” models?
Answer: “Attention” enables the model to focus on relevant parts of the input sequence during processing. -
Question: How can we study the internal representation of a neural network?
Answer: By analyzing activations of individual units and their connections, and using techniques like dimensionality reduction. -
Question: What are the advantages and disadvantages of “supervised learning”?
Answer: Advantages include the ability to make accurate predictions, while disadvantages require large amounts of labeled data and can only learn known patterns. -
Question: What does “zero-shot learning” mean?
Answer: “Zero-shot learning” refers to a model’s ability to solve tasks without having seen specific training data for those tasks. -
Question: Why is studying brain topography important?
Answer: Brain topography reveals the spatial arrangement of regions and their connections, crucial for understanding the function and interaction of brain areas. -
Question: What is the difference between “generative” and “discriminative” models?
Answer: “Generative models” learn the probability distribution of input data, while “discriminative models” learn the probability of a specific class given input data. -
Question: How is the “Brain Score” a useful tool in computational neuroscience?
Answer: The “Brain Score” measures how well a model’s representations explain brain representations, based on alignment with empirical data. -
Question: Describe how “adversarial training” can improve the robustness of neural networks.
Answer: “Adversarial training” enhances robustness by training models to make correct predictions even under minimal perturbations. -
Question: In what context is the work of Tsutsui et al. mentioned in the source “Deepmind_PFC_Meta_Learning.pdf”?
Answer: Tsutsui et al.’s work is mentioned in the context of simulating reward-based learning in the prefrontal cortex. -
Question: What is the significance of the “discount factor” in reinforcement learning?
Answer: The “discount factor” determines how much future rewards are weighted relative to immediate rewards. -
Question: Explain the role of the lateral habenula and the ventral tegmental area (VTA) concerning dopamine signals.
Answer: The lateral habenula inhibits dopamine release during negative events, while the VTA enhances dopamine release during positive events. -
Question: What is the role of the prefrontal cortex (PFC) in the context of “Meta-RL”?
Answer: The PFC stores and updates values based on recent actions and rewards, forming the basis for Meta-RL. -
Question: How does the amount of training data affect the performance of deep learning models?
Answer: Generally, more training leads to better performance but also risks overfitting, especially with too few test data. -
Question: What is the role of the hippocampus in “model-based” learning?
Answer: The hippocampus aids in planning by providing a model of the environment used for decision-making. -
Question: Describe the “two-step task” mentioned in the source.
Answer: The “two-step task” is one where the agent chooses between two actions in the first stage and then transitions to a second stage, leading to rewards. It’s used to study “model-based” learning behavior. -
Question: Explain the function of the “convolutional layers” in a CNN.
Answer: “Convolutional layers” extract features from input images by applying convolution operations to local areas of the images. -
Question: How are training and test data used in machine learning models?
Answer: Training data is used to learn the model parameters, while test data evaluates the model’s ability to generalize to independent data. -
Question: What is the “lottery ticket” phenomenon in neural networks?
Answer: The “lottery ticket” phenomenon describes the discovery that in an overparameterized neural network, a small subnetwork can train to achieve similar performance on its own. -
Question: What are the different spatial scales of grid cells?
Answer: There are at least three different spatial scales of grid cells, capable of representing different distances. -
Question: In what context is Harlow’s work mentioned in the source “Deepmind_PFC_Meta_Learning.pdf”?
Answer: Harlow’s work is mentioned in the context of learning processes after the introduction of new objects and training connections of weights. -
Question: What is the significance of the term “embodiment” in cognitive science?
Answer: “Embodiment” emphasizes the role of the body and its interaction with the environment in shaping cognition and perception. -
Question: What are “latent states” and in what context are they mentioned?
Answer: “Latent states” are hidden states used in reinforcement learning to capture the structure of a task not directly observable. -
Question: What function does the “actor-critic” model play in reinforcement learning?
Answer: The “actor” selects actions based on the current situation, while the “critic” evaluates actions and provides feedback to the actor regarding their quality. -
Question: What is the concept of “divisive normalization” in neural modeling?
Answer: “Divisive normalization” is a mathematical operation where a cell’s activity is divided by the sum of the activity of other cells. It can be used to normalize neuron activity. -
Question: What is the significance of “generalization performance” in neural networks?
Answer: “Generalization performance” describes how well a model can be applied to new, unseen data, a crucial criterion for a useful model. -
Question: What is “Occam’s Razor” and how is it applied in machine learning?
Answer: “Occam’s Razor” holds that the simplest explanation is usually the best. In machine learning, it is used to minimize model complexity and prevent overfitting. -
Question: Explain the concept of “predictive coding”.
Answer: “Predictive coding” is a model of neural processing where the brain constantly makes predictions about its sensory inputs and minimizes the error between prediction and input. -
Question: What is “representational geometry” in the context of neural representations?
Answer: “Representational geometry” describes how various stimuli are arranged in the brain’s representational space and the relationships between these representations. -
Question: How are a neural network’s weights adjusted during training?
Answer: Weights are adjusted using gradient descent methods and backpropagation. -
Question: What is the role of “innate” components in brain development?
Answer: “Innate” components are encoded in the genetic code and provide a basic structure and initial functions for the brain. -
Question: What is “empowerment” in the context of reinforcement learning?
Answer: “Empowerment” measures the degree of control an agent has over its environment. -
Question: What is “synthetic neurophysiology” and how can it be used?
Answer: “Synthetic neurophysiology” uses simulated input patterns to investigate a model’s internal representations. -
Question: What is the significance of “batch size” when training a deep learning model?
Answer: “Batch size” determines the number of training samples used in each training step. It influences the stability and efficiency of the learning process. -
Question: What is the difference between a “white-box” and a “black-box” attack on a neural network?
Answer: “White-box” attacks have full access to the model, while “black-box” attacks only see inputs and outputs. -
Question: Explain the significance of the term “unsupervised feature learning”.
Answer: “Unsupervised feature learning” enables extracting features from unlabeled data, which can be used for later classification or regression. -
Question: Why is it necessary to regularize training parameters?
Answer: Regularization reduces the risk of overfitting and improves the generalization ability of the model. -
Question: What is the role of “visual attention” in processing visual information?
Answer: “Visual attention” allows selectively focusing on relevant parts of the visual field. -
Question: Concerning biological and artificial vision, what are some advantages of recurrent neural networks (RNN)?
Answer: RNNs can process temporal dependencies, perform flexible computations, and tailor processing to the task. -
Question: How can employing artificial neural networks (ANNs) support hypothesis testing in neuroscience?
Answer: ANNs enable testing specific hypotheses in a system capable of processing sensory information and generating behavior. -
Question: What is the significance of “task design” in cognitive research?
Answer: “Task design” allows isolating components of cognition so they can be quantitatively studied. -
Question: What is the function of the “visual module” in a grid-cell agent?
Answer: The “visual module” is a type of “front-end” of the neural network tasked with processing an input image for the subsequent neural network. -
Question: What is the difference between “common” and “uncommon” transitions in the “two-step task”?
Answer: “Common” transitions are more frequent, while “uncommon” transitions are rarer. These transitions are used to study how model-based and model-free learning work. -
Question: What does it mean in the context of reinforcement learning when an agent chooses a “safe arm” or “risky arm” in a task?
Answer: A “safe arm” offers a secure, small reward, while a “risky arm” provides a chance for a larger reward or no reward. The choice is influenced by the respective reward probability. -
Question: What is the difference between a “supervised” and a “self-supervised” task in training neural networks?
Answer: A “supervised” task requires labeled data, while a “self-supervised” task, such as color prediction, does not require additional labels. It extracts labels from the data itself. -
Question: Explain the purpose of the “linear layer” in analyzing “grid cells”.
Answer: The “linear layer” is a layer in the neural network whose activity is analyzed to identify the activity of grid cells, border cells, and head-direction cells. -
Question: What is the goal of “lesion studies” in neuroscience?
Answer: “Lesion studies” investigate the effect of damaging or inactivating brain areas to determine their function. -
Question: What is the goal of “meta-learning” in machine learning?
Answer: “Meta-learning” aims to develop algorithms that can quickly learn and adapt to new tasks. -
Question: Explain the concept of “dimensionality reduction”.
Answer: “Dimensionality reduction” reduces the number of variables in a dataset while retaining important information. -
Question: What is the role of “episodic memory” concerning Meta-RL?
Answer: “Episodic memory” could be used in Meta-RL to store past experiences for use in future tasks. -
Question: What is “model-based planning” in decision making?
Answer: “Model-based planning” uses an internal model of the environment to plan for future events and make decisions. -
Question: What is the role of the “mesolimbic”, “mesocortical”, and “nigrostriatal” dopamine pathways in the context of Meta-RL?
Answer: The exact roles of these dopamine pathways in Meta-RL are unknown, but they are speculated to play a differential role in learning processes. -
Question: What is the significance of “naturalism” in cognitive ability research?
Answer: “Naturalism” emphasizes the need for tasks that simulate natural environments and behaviors in studying cognition. -
Question: What are the advantages and disadvantages of “bottom-up” and “top-down” approaches in neuroscience?
Answer: The “bottom-up” approach starts with basic elements and builds up, while the “top-down” approach begins with a broad overview and then works down to details. -
Question: Describe the “inception loop” approach to exploring neural activity.
Answer: “Inception loops” use deep predictive models to discover which stimuli most stimulate neurons. -
Question: What are the ethical implications of using artificial intelligence in animal and human studies?
Answer: Ethical aspects include improved planning, minimizing suffering, and the potential for virtual experiments, allowing better use of resources. -
Question: How is data compared in “representational similarity analysis” (RSA)?
Answer: Data is compared by comparing patterns or distances between patterns in neural and model activities. -
Question: Concerning the “zero-shot” learning approach, how do the types of data used differ from other learning methods?
Answer: “Zero-shot” learning uses information from one task to solve another task without specific training data for that task. -
Question: What is the significance of “over-production” with variation in the context of evolution and direct-fit learning?
Answer: “Over-production” with variation is a mechanism that promotes diversity and adaptability in evolution and direct-fit learning. -
Question: What are some limitations of “deep neural networks” (DNNs) as models of the brain?
Answer: DNNs are often difficult to interpret and require large amounts of labeled data, which does not always correspond with the brain’s learning mechanisms. -
Question: Describe the concept of “transfer of adversarial vulnerability”.
Answer: The concept describes that if an “adversarial example” is developed against a specific neural network, the vulnerability can transfer to other networks. -
Question: Describe the “bias-variance tradeoff” in choosing the right complexity of a model.
Answer: The goal is to find the right balance between model complexity and generalization ability, so that models are not too tailored to training data, but still meaningful.
These questions should help you prepare well for the exam. It is important that you understand not only the answers but also the concepts behind the questions. Good luck!
Questions
1. How is the Meta-Reinforcement Learning (Meta-RL) architecture modeled in the DeepMind study and how does it learn?
The Meta-RL architecture is modeled as a recurrent neural network (RNN) called the “Prefrontal Network (PFN),” which includes areas of the basal ganglia and thalamus directly connected to the prefrontal cortex (PFC). This network is trained using an RL algorithm driven by dopamine (DA). It processes perceptual inputs (o), actions (a), and rewards (r) over time (t) and computes the state value (v). A key component is an LSTM (Long Short-Term Memory) unit that processes the current observation, previous action, and reward. Synaptic weights are adjusted by the RL algorithm, with the LSTM unit featuring input, output, and maintenance gating. The network learns across episodes to efficiently learn within an episode, shifting from exploration to exploitation.
2. What are grid cells and how are they modeled in the DeepMind models?
Grid cells are neurons in the entorhinal cortex that form a spatial grid pattern of activity as an animal moves through space. In DeepMind models, they are modeled using a multilayer architecture that includes a recurrent LSTM network with linear layers projecting to place and head-direction cells. The LSTM network receives input from the agent’s linear and angular velocity. The system can be trained through “supervised learning” to calculate the agent’s position in space or through “reinforcement learning” to aid navigation. After training, units develop spatial responses similar to grid, border, and head-direction cells found in the entorhinal cortex, as well as conjunctive grid cells showing directional modulation. These models enable the agent to navigate and track its position in an environment.
3. What is Representational Similarity Analysis (RSA) and how is it used to compare models with brain data?
RSA is a method to compare representations of different systems by comparing their representational geometries. An RDM (Representational Dissimilarity Matrix) records the dissimilarity of a system’s responses (neural or model) to pairs of experimental conditions. Conditions eliciting similar responses are closer in the response space, while differing conditions are further apart. A model is considered similar to brain representation if it emphasizes the same distinctions among stimuli, i.e., if the model and brain produce similar RDMs. RSA circumvents the need to correlate specific model units with activity measurement channels and can be applied to fMRI, single-cell recordings, EEG/MEG, and behavioral data.
4. What role do intrinsic dimensionality and regularization play in modeling the brain?
Intrinsic dimensionality refers to the number of degrees of freedom needed to describe the data. Studies suggest that models with higher intrinsic dimensionality often make better predictions of brain activity. Regularization is a technique to limit model complexity, preventing adaptation to noise rather than generalizable patterns. It avoids “overfitting” and increases robustness but can also affect interpretability. Intrinsic dimensionality choice and regularization methods significantly impact a model’s ability to map the brain and perform general tasks.
5. What is the role of recurrence in neural networks, and what advantages does it offer?
Recurrence, especially through LSTM units, allows networks to process temporal patterns and dependencies. In the Meta-RL model, it enables the network to integrate information about prior actions and rewards, adjust internal dynamics for learning, and store dynamic information, adapting to new tasks with high “plasticity.” Recurrent models are not limited to “feedforward” principles but also learn feedback processes, essential for replicating complex cognitive functions.
6. What is the role of attention in sequence-based models, and how does it work in practice?
Attention in sequence-based models allows the network to focus selectively on the most relevant parts of an input sequence. In image captioning (image to text), it allows the decoder to attend to relevant image regions when generating each word. In translation tasks, it helps find the input word corresponding to the output word. Typically implemented by calculating attention weights for each input at each step. The attention concept, crucial in Transformer networks, is consistent across domains, enabling flexible and effective sequential models.
7. How do “Target Propagation” algorithms (especially “Difference Target Propagation (DTP)”) work, and why are they an alternative to backpropagation?
“Target Propagation” algorithms are alternatives to backpropagation, attempting to propagate error information backward through networks while avoiding the “chain rule.” DTP uses auto-encoders to reconstruct layer output and compute local layer errors. Each layer attempts to optimally reconstruct the previous layer, using error signals to update autoencoder and feedforward weights. DTP facilitates “local” learning, considered more biologically plausible than global “backpropagation,” by learning to learn the reconstruction of each layer’s activation.
8. How are “Normative Models” used, and what alternative learning objectives exist aside from supervised learning?
“Normative Models” are used to understand what makes neural networks “brain-like.” Beyond supervised learning, unsupervised objectives like “sparseness” strive for sparse data representation, while “compression” aims to reduce representational dimensionality for optimal “resource” use. “Temporal stability” or “slowness” highlights slowly changing signals for adaptive behavior. These objectives train networks without external “supervision,” promoting autonomous learning.
What is the neuroconnectionist approach?
The neuroconnectionist approach is a research framework aimed at understanding brain functions by modeling with artificial neural networks (ANNs). This approach emphasizes using ANNs as a type of “computational language” to express falsifiable theories about brain computation. Rather than viewing individual models as the “truth,” neuroconnectionism considers a diversity of ANN models as useful tools for exploring the brain.
Here are the key aspects of the neuroconnectionist approach:
- Focus on Explaining Cognitive Functions: Neuroconnectionist models primarily aim to explain cognitive functions rather than describing biological details with high accuracy. Biological details are added “top-down,” hypothesis-driven, when necessary to explain behavioral or neural data, distinguishing the approach from attempts to perfectly replicate a human brain in silico or model every neuron detail.
- Distributed Representations and Computation: The modeled feature emerges from the collective behavior and dynamics of simple units, which individually do not exhibit the modeled feature. This distributed nature naturally bridges individual units, collective dynamics, and behavior, setting the approach apart from traditional models with direct parameter interpretation.
- Iterative Training and Inference: The high dimensionality of distributed models makes it impossible to manually set all parameters, necessitating iterative training. The behavior and dynamics during inference cannot be summarized in a simple interpretable equation.
- Sensory Grounding: Although not all models are sensory-grounded, a goal is to develop models driven by sensory inputs, enabling a connection between perception, cognition, and action. In cases where the sensory nature of inputs may be irrelevant (e.g., language models), they can be added later if needed.
- Hypothesis-Driven Research: The neuroconnectionist approach is hypothesis-driven, aiming to elucidate mechanisms and theoretical understanding through research, differing from engineering goals.
- Use of ANNs as Core: Experiments apply not directly to the core but to surrounding belt hypotheses realized through ANN instantiations and tested with various techniques. The program’s success is judged by its ability to generate new insights, confirm belt hypotheses, derive testable predictions, and address criticism productively.
- Model Situated in a Biological Abstraction Goldilocks Zone: It is abstract enough to be manageable and trainable, while retaining sufficient biological details in its algorithmic structure to map to neural and behavioral data.
Neuroconnectionism as a Lakatosian Research Program:
Neuroconnectionism is viewed as a Lakatosian research program consisting of a core of fundamental assumptions and a belt of auxiliary hypotheses. The core is the general approach of modeling brain functions using ANNs, while the belt includes specific architectures, learning rules, and objective functions tested in experiments. This framework enables new insights and responsive criticism, marking the approach as progressive.
Tools of Neuroconnectionism:
Neuroconnectionism employs several tools to train and evaluate ANNs, including:
- In-silico Electrophysiology: Experiments on ANNs to understand the selectivity of individual units.
- Network Dissection: A method for quantitatively analyzing unit selectivity by identifying images that maximally activate them and evaluating their semantic consistency.
- Representational Similarity Analysis (RSA): A method for comparing representational structures among ANNs, brains, and behaviors.
- Encoding Models: Use ANNs to predict neural responses by matching ANN parameters to measured brain data.
- Decoding Models: Identify information encoded in brain region neural activity patterns.
Challenges and Criticism:
Despite its successes, neuroconnectionism faces challenges like the biological implausibility of some ANN models and their tendency to behave differently from humans. These challenges are seen as signposts for further development, reinforcing the program’s belt.
In summary, the neuroconnectionist approach is a promising path to understanding the brain, leveraging ANNs to create hypothesis-driven, multi-level models that explain both neural data and behavior.
complex deep questions from notebookLM
Certainly, here are 20 deep and complex questions to help you prepare for an exam, along with detailed answers based on the sources:
-
Question 1: Explain the concept of “direct fit” in the context of artificial and biological neural networks. How does it differ from traditional models in psychology and neuroscience?
Answer: “Direct fit” refers to a learning process where models, particularly overparameterized models like deep neural networks (DNNs), learn by optimizing millions of synaptic weights based on millions of observations to function robustly in real-world contexts. Unlike traditional models that aim to learn simple, human-interpretable rules or representations, these models interpolate over task-specific manifolds in a high-dimensional parameter space through local computations. This method resembles evolutionary processes and offers a flexible and robust solution for learning a variety of functions. Unlike ideal models, which build on a limited sample of data, “direct fit” models use dense sampling to expand the interpolation zone, facilitating generalization. -
Question 2: What are the three core elements of a deep learning framework for the brain according to Richards et al.? How do these elements influence the development of brain function models?
Answer: The three core elements are: (i) Objective functions, (ii) Learning rules, and (iii) Architectures. Objective functions describe the goals of the learning system, learning rules specify how parameters in a model are updated, and architectures describe how units in an artificial neural network are arranged and what operations they can perform. These elements form a framework to understand neural responses as the result of the interplay between objective functions, learning rules, and architecture. -
Question 3: Describe the role of “representational similarity analysis” (RSA) in investigating brain representations. How does it differ from decoding, and what are its advantages?
Answer: RSA is a method for characterizing representations by considering the distance between population activity vectors evoked by different inputs. Unlike decoding, which typically focuses on binary distinctions and whether a region contains information about a stimulus class, RSA goes beyond class discriminability to examine the geometric structure of the representation. RSA allows hypotheses about the representational space to be tested based on multivariate descriptions of experimental conditions, such as semantic descriptions or activity patterns in neural network layers. It is particularly useful for identifying matches between brain representations and model representations and offers a more stringent testing method than simple correlations. -
Question 4: Explain the significance of “Effective Dimensionality” (ED) concerning the performance of DNNs in predicting neural data. Is higher dimensionality always better?
Answer: Effective Dimensionality describes the variance distribution in a model’s eigenspectrum and influences its ability to explain neural data. Contrary to the assumption that higher dimensionality unambiguously leads to better performance, this isn’t the case. Models with too high ED can overfit to training data, leading to worse performance on test data. One study found that higher ED, achieved through performance-oriented DNN architectures, can increase the overlap of model representations with cortical representations. Thus, it’s not just about the number of dimensions, but whether those dimensions are relevant to the task at hand.more depth answer:
Whether high effective dimensionality (ED) is beneficial or detrimental depends on the context, particularly when modeling the visual cortex with deep neural networks (DNNs). Contrary to the traditional view that low-dimensional representations in neural systems and DNNs are advantageous, recent research shows that high-dimensional representations can offer significant benefits in certain cases.Here are the key points to consider when evaluating the pros and cons of high effective dimensionality:
Advantages of High Effective Dimensionality:
- Improved Prediction of Brain Activity:
- DNNs with high ED are strongly positively correlated with their accuracy in predicting neuronal activity in the visual cortex. This means that models with higher dimensionality can better capture the activity patterns in the brain.
- This correlation persists even when controlling for architecture, training data, and other design factors.
- High ED allows models to encode a wider variety of image features, resulting in more accurate predictions.
- Better Generalization to New Categories:
- High-dimensional representations enable models to learn and classify new object categories more effectively.
- They are better equipped to generalize and recognize new categories with fewer examples.
- This suggests that high-dimensional representations could serve as more flexible general-purpose representations as opposed to low-dimensional representations optimized for specialized tasks.
- More Efficient Use of Representation Resources:
- High-dimensional codes can represent a greater variety of features and downstream readouts.
- They utilize redundancy in high-dimensional spaces more efficiently, leading to a better representation of patterns.
- Concentration of Measure:
- In high-dimensional spaces, most of the manifold mass concentrates along the equator. This results in a stronger concentration of features near their class centroids, facilitating category discrimination.
- Robustness:
- High-dimensional codes can be more robust to perturbations.
- Higher dimensionality can increase the expressiveness of the model.
Disadvantages of High Effective Dimensionality and Limitations:
- Potential Redundancy:
- High-dimensional models might represent redundant visual features not present in neuronal data.
- This could indicate inefficiency, particularly in terms of biological plausibility.
- Interpretation:
- The large number of parameters in complex models can make interpretation difficult.
- It may be challenging to directly interpret individual parameters in high-dimensional models.
- Overfitting:
- Models with too many parameters can fit noise rather than general patterns (overfitting) if not adequately trained. This can hinder generalization to new data. Cross-validation is needed to prevent overfitting.
- Not Always Necessary:
- In some cases, low-dimensional models with good encoding performance exist, suggesting that high dimensionality is not always necessary.
- There are outliers: Models with low ED can still perform well, especially if their high-variance dimensions align with those in the brain. Their actual dimensionality may be higher than suggested by their low ED.
- Computational Cost:
- Models with high dimensionality may require higher computational resources.
Key Considerations:
- The relationship between ED and encoding performance is not trivial and cannot be simply explained by high ED alone.
- Performance also depends on other factors, such as the alignment between models and neural representations (Alignment Pressure).
- High ED alone is insufficient for good performance; the alignment of relevant dimensions is also critical.
- Interpreting ED as the number of accurately encoded visual features assumes that variance along a dimension is proportional to the signal-to-noise ratio (SNR). This assumption is not always valid, and ongoing work aims to develop metrics that account for SNR more accurately.
Conclusion:
High effective dimensionality is neither inherently good nor bad. It appears to be an important factor for the performance of DNNs in modeling the visual cortex, as it allows for better fitting of neuronal data and improved generalization to new categories. However, it is not the only factor and should be interpreted in conjunction with others, such as alignment. The choice of dimensionality depends on the specific task requirements. It’s important to consider the trade-offs between handling more complex tasks and potential downsides such as redundancy and interpretability issues. Research in this area is ongoing, and future studies are expected to provide a better understanding of the role of dimensionality in brain modeling.
- Improved Prediction of Brain Activity:
-
Question 5: What is the “black-box” objection to using DNNs as brain models? How can this criticism be countered, and how do DNNs enable “in-silico” experiments?
Answer: The “black-box” objection argues that DNNs are difficult to understand and interpret due to their complexity (millions of parameters). This criticism can be countered because DNNs are transparent boxes, offering easy access to the activity and connections of each unit. “In-silico” experiments on DNNs can be conducted to understand internal representations, often much faster than traditional experiments. By analyzing activity patterns and connections, researchers can gain insights into the model’s function and possibly into brain function. -
Question 6: Discuss the pros and cons of models with high biological fidelity compared to models with high cognitive fidelity. Where do DNNs fit in this spectrum?
Answer: Models with high biological fidelity aim to replicate properties of biological neural networks, such as action potentials and interactions between individual neurons, focusing on understanding emergent dynamics in small parts of the brain but often neglect cognitive function. Models with high cognitive fidelity try to capture cognitive functions at an algorithmic level while overlooking biological details. DNNs are on the spectrum’s cognitive fidelity end, modeling complex behaviors while abstracting from biological details. They serve as a minimally working starting point to investigate which biological details are vital for brain function.
Question 7: Describe the challenges and methods for mapping artificial neural networks to real neurons. What metrics are crucial?
Answer: Mapping DNNs to real neurons involves various approaches, from matching task information to predicting single-cell responses. Task-Information Consistency compares patterns of information extracted by decoding methods in neural populations and models. Single-Unit Response Predictivity investigates how well linear combinations of model units replicate real neuron response patterns. The R² metric, measuring variance explained in neuron responses to new stimuli, is key. A challenge is that deeper models have more parameters, complicating output visualization and generalization.
Question 8: Explain the importance of “tasks” in cognitive neuroscience and the development of AI models. Provide examples of tasks used in these fields.
Answer: Tasks define controlled behavior environments, supplying sensory inputs and capturing motor outputs. They drive data acquisition and model development, providing well-defined challenges and quantitative performance benchmarks for comparing models. Examples include psychophysical tasks with simple stimuli and responses, virtual reality interactions, and tasks like the ImageNet classification challenge. Tasks are designed for cross-disciplinary use, facilitated by platforms like OpenAI’s Gym or DeepMind’s Lab.
Question 9: What is “amortized inference” and why is it important for understanding brain function?
Answer: Amortized inference describes a brain strategy for rapid learning. The brain learns by repeatedly applying costly iterative algorithms like Markov Chain Monte Carlo (MCMC) or belief propagation and storing these inferences, allowing quicker responses in repeated operations. The brain uses these fast forward models as shortcuts for frequent, costly operations.
Question 10: Describe the role of grid cells in navigation and how they are implemented in deep learning models.
Answer: Grid cells are neurons with place-specific activity patterns, serving as the brain’s spatial coordinate system, crucial for navigation. In deep learning models, grid cells are simulated through layers of linear units exhibiting space and direction-dependent activity patterns. Adding grid cell inputs has been shown to enhance navigation in RL environments for agents.
Question 11: How can the manipulation of different aspects of ANNs, such as architecture, input statistics, objective function, and learning algorithm, be used to test theories about the brain?
Answer: Manipulating aspects like network architecture, input statistics, objective functions, and learning algorithms allows testing theories about the brain. Adjusting input statistics helps examine how different distributions of categories or temporal dependencies develop internal representations in the brain and artificial NNs. Manipulating the objective function allows observing the emergence of specific properties (e.g., through a particular task) and understanding why they’re important for brain information processing. Changing the learning algorithm can uncover how the brain learns and whether neuronal learning processes can be mimicked artificially. Different NN architectures help investigate how connection patterns in NNs reflect brain representations.
Question 12: Discuss the significance of “meta-learning” in the context of reinforcement learning (RL).
Answer: Meta-learning allows an agent to efficiently learn how to learn within episodes across episodes. A meta-RL agent adjusts its synaptic weights by learning from previous episodes to enhance performance in subsequent ones. The network learns to learn, making transitions from exploration to exploiting behavior more efficient. DeepMind’s model uses an RL-guided recurrent neural network for meta-learning.
- Question 13: What are “adversarial examples” and how can they be used in cognitive neuroscience to test brain models?
Answer: Adversarial examples are minimal image modifications that lead DNNs to output incorrect categorizations. These examples illustrate DNNs operate differently from the human brain, as modifications are imperceptible to humans. In cognitive neuroscience, adversarial examples can craft stimuli where various representations (e.g., brain and DNN) diverge maximally, optimizing model differentiation. Adversarial attacks on NNs can induce similar errors as the brain.
Question 14: How can neural networks be used to simulate the development of neural representations in the brain?
Answer: Neural networks simulate the development of neural representations by being fed various inputs and undergoing different learning strategies. Resulting representations are compared to brain ones to study what environmental aspects are crucial for generating similar neural representations in brains and models.
Question 15: Explain the importance of “generalization” in neural network performance. How does the amount of training data influence generalization ability?
Answer: Generalization describes a model’s ability to make accurate predictions on new, unseen data. Overparameterized models can tend to overfit to training data if data volume is small, hampering generalization. Dense parameter space sampling with large datasets enables overparameterized models to achieve remarkable interpolation with good generalization.
Question 16: How does the “traditional” experimental approach in neuroscience and psychology differ from using DNNs as brain models?
Answer: The traditional approach often involves testing singular hypotheses about cognition, verbally defined and aiming to reveal brain algorithms through binary questions. In contrast, DNNs enable a data-driven approach, optimizing network calculations through learning rather than researchers defining them. DNNs become comprehensive task-performing models highlighting interactions of mechanisms and their suitability for cognitive function.
Question 17: What is the concept of “inductive bias” in the context of machine learning and neural networks?
Answer: Inductive bias refers to assumptions a learning algorithm makes about data, including NN architecture, learning rule type, and training data selection. Good inductive bias helps a network learn and generalize faster and better by enabling it to recognize correct patterns and ignore irrelevant information.
Question 18: Describe the various methods for testing robustness and spatial activity in neural network models as described in the sources.
Answer: Testing robustness includes strategically silencing network units using random masks, silencing 20% of Goal Grid Code units to assess agent adaptation to untrained inputs. Spatial activity is measured by activity maps for each unit, showing average activity from trajectory points in spatial and directional bins. Hexagonal regularity of grid-like patterns is quantified using the “Gridness-Score” and “Grid-Scale.”
Question 19: Discuss the difference between using “ideal-fit” models and “direct-fit” models for brain modeling.
Answer: Ideal-fit models often rely on hand-crafted rules, capturing fundamental mechanisms, working well under ideal conditions, and fitting controlled data. Direct-fit models use large datasets and overparameterized structures, fitting data directly and learning complex, multidimensional relationships. They often skip explicit rules, focusing on interpolation in a high-dimensional parameter space, best for complex real-world contexts.
Question 20: How can understanding learning processes in the human brain provide new possibilities for training artificial neural networks, especially concerning learning with small data sets?
Answer: The human brain, especially in infants and children, learns efficiently from relatively small datasets, applying knowledge flexibly. Developmental research explores factors underpinning this learning, like innate inductive bias and guidance from parents/environment. Such insights might improve machine learning representation, learning principles, and training strategies, like enhancing hyperparameter spaces or using active learning. This is crucial as most deep learning models require large data volumes.
Question 21: What are the difference between LeNet, Neocognitron, AlexNet and TDANN
Certainly, here is a breakdown of the differences between LeNet, Neocognitron, AlexNet, and TDANN based on the sources:
* **LeNet:**
* LeNet was an early **convolutional neural network architecture (CNN)** developed primarily for **handwriting recognition**.
* It used **convolutional layers** for feature extraction and **subsampling** (pooling) to reduce spatial resolution.
* It was an important precursor to later CNN architectures, demonstrating the effectiveness of convolution operations in image processing.
* **Neocognitron:**
* Introduced by Kunihiko Fukushima in **1980**, the Neocognitron was an early **hierarchical, multilayered neural network**.
* Considered the **first CNN**.
* Used **convolutional filters**, **average pooling**, and a **ReLU activation function** long before they became widespread in modern deep learning.
* It was trained **self-supervised** for handwriting recognition.
* Featured S-cells (feature detectors) and C-cells, organized in groups. S-cells received excitatory connections from C-cells, while V-cells had variable inhibitory connections with fixed input from C-cells.
* S-cells initially showed weak orientation selectivity, strengthened through a learning process where weights were copied to other S-cells.
* It was a **self-organizing** network model for pattern recognition, independent of positional changes.
* **AlexNet:**
* AlexNet was a groundbreaking CNN introduced in **2012**.
* Achieved **significantly better performance** than previous models in image classification on the ImageNet dataset.
* Shared many architectural details with earlier hierarchical feedforward models of the visual cortex, like the Neocognitron.
* Used **convolutional layers**, **ReLU activation functions**, **pooling**, and **fully connected layers**.
* AlexNet demonstrated the potential of deep neural networks, sparking a significant advancement in deep learning.
* Achieved a top-5 accuracy of **83.6%**, surpassing the second-best system by over 10%.
* **TDANN (Topographic Deep Artificial Neural Network):**
* TDANN is a **convolutional architecture** based on **ResNet18**.
* Unlike other models, TDANN considers the **topographic organization of neurons** found in the brain.
* Uses **"virtual" spatial positions** and is pretrained on ImageNet.
* After pretraining, the network is **locally shuffled** to achieve smoothness (unit swapping), then reset and retrained with a new spatial neighborhood.
* TDANN **outperforms other models** in functional correspondence, especially after rotation/reflection.
* Capable of predicting visual cortex areas selectively activated by certain stimulus categories.
* TDANNs were found to **outperform other models** without supervision.
**Summary of Differences:**
* **LeNet** was an early CNN pioneer for handwriting recognition, highlighting the foundational principles of convolutional networks.
* **Neocognitron** was an early hierarchical network with self-organizing properties, a precursor to CNN architectures also applied to handwriting recognition.
* **AlexNet** marked a breakthrough in deep learning, proving the prowess of deep CNNs in image recognition tasks.
* **TDANN** is a newer development focusing on the topographic structure in the brain, improving prediction accuracy in visual processing areas.
These models represent various developmental stages and approaches in neural networks and image processing, each with its strengths and unique features.
-
Question: Explain Marr’s three levels of analysis and how these levels interplay in modeling cognitive processes. Provide examples of how insights at one level can influence other levels.
Answer: Marr’s three levels of analysis are:
* Computational Theory: What is the goal of the computation? Why is it appropriate? What is the logic of the strategy? For example, what information is extracted and why? What are the input and output?
* Representation and Algorithm: How can the theory be implemented? How are the input and output represented? What algorithm transforms input into output?
* Hardware Implementation: How can representation and algorithm be physically realized?
The levels inform and influence each other. Insights at the hardware level, for example, can reveal constraints for the algorithm and representation, while a clear computational theory can guide the search for a suitable algorithm. -
Question: Why do the authors consider ANNs (Artificial Neural Networks) a good level of abstraction for modeling the brain, and what does the concept of the “Goldilocks Zone” mean in this context?
Answer: ANNs operate at a level of abstraction that is productive because they are biologically plausible yet not too detailed, allowing for algorithmic clarity and computational manageability. The “Goldilocks Zone” describes this ideal middle ground: ANNs are detailed enough to be biologically relevant but abstract enough to allow for algorithmic clarity and training with rich domain knowledge. This enables them to perform complex behaviors based on sensory perceptions. -
Question: Describe the neuroconnectionist research cycle and how it differs from other research approaches. What is the goal of model contrasts within this cycle?
Answer: The neuroconnectionist research cycle focuses on modeling neural data and behavior while integrating neural insights into networks for hypothesis testing. Unlike purely behavior-based or strictly biologically detailed approaches, neuroconnectionism aims to explain both behavioral and neural data. Model contrasts serve to test different hypotheses about brain function by incorporating various architectures, goals, input statistics, or learning methods in ANNs and examining their impact on outcomes. -
Question: Explain the significance of RSA (Representational Similarity Analysis) for comparative analysis between the brain and ANNs. What advantages does RSA offer, and what limitations should be considered?
Answer: RSA allows comparison of representations at the level of patterns of activity similarities rather than individual units. This avoids the problem of matching ANN units to voxels/neurons. Advantages include that RSA requires no parameter fitting (except for reweighting), applies to population data, and the choice of distance metric provides a “lens” on data that highlights various aspects. A limitation is that it’s an indirect measure, avoiding direct mapping of ANN units to brain activity. -
Question: Explain various distance metrics used in RSA, such as Euclidean distance, Manhattan distance, cosine similarity, and Mahalanobis distance. What specific properties does each metric have, and when is it best used?
Answer:- Euclidean Distance (L2): Measures the “straight-line” distance between two points but is susceptible to noise distortion.
- Manhattan Distance (L1): Measures distance as the sum of absolute differences along axes. It implies neurons contribute additively.
- Cosine Similarity: Measures the angle between two vectors and is size-independent.
- Mahalanobis Distance: Considers data distribution and downweights noisy dimensions, making it robust against noise.
The choice of distance metric depends on data type and properties being investigated.
-
Question: What are “noise ceilings” and how are they used in RSA to assess model quality? Explain the difference between the upper and lower bounds.
Answer: Noise ceilings define the maximum accuracy a model can achieve regarding brain data prediction and assess how much of the explainable variance a model can explain.- Upper Bound: Defines the best possible model based on average distance to average RDM. No model RDM can be better.
- Lower Bound: Defines how well participants predict each other based on average distance between the average of N-1 participants and the Nth data point.
Noise ceilings help judge whether a model is good enough or limited by noise.
-
Question: Describe the development of ANNs from Neocognitron to AlexNet and what key innovations led to the “Deep Learning Revolution”.
Answer: Neocognitron was an early model inspired by biological insights. LeNet showed promise in the 1990s. The “Deep Learning Revolution” from 2012 was triggered by AlexNet, notable for:
* Larger networks (80x bigger than LeNet).
* ReLU activation functions.
* Dropout.
* GPU parallelization.
* Strides.
These innovations, along with larger datasets like ImageNet, led to significant improvements in image recognition performance. -
Question: How can style transfer be used as an experimental method to investigate how ANNs and humans recognize and categorize objects?
Answer: Style transfer applies texture A to image B. Then, tests how well ANNs and humans classify objects. This method helps explore whether models and humans respond more to form or texture when recognizing objects. -
Question: What are TDANNs (Topographically Differentiated Artificial Neural Networks) and how do they mimic the organization of the visual cortex?
Answer: TDANNs are a type of ANN that mimics the topographic organization of the visual cortex. Based on a ResNet18 architecture with “virtual” spatial positions, trained with a local shuffling procedure for “smoothness” in feature selectivity, TDANNs replicate lower and higher organizational features of the human visual cortex and generate multiple streams due to spatial constraints. -
Question: Explain the two main theories that account for the formation of multiple streams in the visual cortex, and how TDANNs contribute to this debate.
Answer:- Theory 1 (Multiple Behavioral Demands): Streams serve different functions: ventral for categorization, dorsal for object recognition, and medial for action recognition.
- Theory 2 (Spatial Constraints Hypothesis): The proximity of neurons processing related information speeds processing and increases efficiency (minimizes wiring length).
TDANNs contribute by showing spatial constraints in architecture can lead to stream specialization.
-
Question: Describe the concept of “few-shot learning” and why it is challenging for traditional machine learning models. What role does “tight” representational geometry play?
Answer: Few-shot learning is the ability to learn from few examples. Traditional models need many examples to generalize. “Tight” representational geometry means concepts occupy narrowly defined manifolds in neural activity space, allowing quick downstream plasticity adaptation. -
Question: What is the difference between prototype and exemplar theories in the context of few-shot learning?
Answer:- Exemplar Theory: Stores all instances and classifies by nearest neighbor rule.
- Prototype Theory: Stores only the average/prototype and classifies based on distance to the prototype.
-
Question: How do language models (LLMs) work and what steps are necessary to use them in models of semantic processing in the brain?
Answer: Language models predict the next word in a sentence based on large text corpora. Steps to use in the brain:
* Train language models on text data.
* Use text/transcripts from fMRI stimuli to derive predictions from language model.
* Evaluate prediction ability using multivariate benchmarks.
Encoder-decoder architectures transform sentences into semantic representations. -
Question: Explain how the “Encoding Model Approach” is used to evaluate whether GPT-2 is a good model for language processing in the brain. What steps are involved and how are results interpreted?
Answer: The Encoding Model Approach involves:
* Presenting materials to the model also shown to human participants.
* Mapping ANNs to individual voxels using encoding model.
* Predicting activation levels for independent materials.
* Correlating predictions with actual data.
* Normalizing correlation by noise ceiling.
Results are interpreted as the proportion of explainable variance the model can account for. -
Question: How can the integration of embodiment and reinforcement learning (RL) improve the understanding of brain function, and why is it important not to consider the brain in isolation from the body?
Answer: Integration of embodiment and RL is essential as the brain doesn’t exist independently of the body it controls. Much of brain function serves behavior control and action selection. Embodiment recognizes that the brain processes not just static categories but interacts dynamically with the environment. -
Question: Explain the role of grid cells in navigation and how they are used in models of spatial orientation and navigation.
Answer: Grid cells code spatial position through a grid pattern. Used in navigation models to enable spatial orientation. Grid cell input is superior to place cell input for navigation. In modeling, they allow path integration and support efficient navigation in complex environments. -
Question: What are the key differences between classical “pattern recognition” approaches and deep learning regarding feature extraction and classification processes?
Answer:
* Classical Pattern Recognition: Uses explicitly defined feature extraction methods and a trainable classifier.
* Deep Learning: Learns feature extraction and classification simultaneously through a cascade of trainable layers.
Deep learning allows learning feature hierarchies, overcoming the need to manually define features. -
Question: Describe the neuroconnectionism approach and what are its goals compared to other research directions like pure neuroscience or pure AI research?
Answer: Neuroconnectionism aims to explain both behavioral and neural data. It uses ANNs for inter-level modeling, from neural data to behavior, while integrating neural insights into models. In contrast, pure neuroscience focuses on biological details, and pure AI research focuses on task performance and algorithmic efficiency. Neuroconnectionism bridges these fields. -
Question: What does “self-supervised learning” mean in the context of brain modeling and how does it differ from supervised and unsupervised learning? What are the advantages of this approach?
Answer: Self-supervised learning uses tasks and data from input itself to train models. It differs from supervised learning, which needs labeled data, and unsupervised learning, which uses no labels. Self-supervised learning enables learning representations suited for various downstream tasks and reduces the need for large labeled data amounts. -
Question: Explain the concept of “double descent” regarding model complexity and how it influences our understanding of how the brain can handle a large number of parameters.
Answer: Double descent describes a U-shaped curve of test errors as model complexity increases. At few parameters, bias dominates, followed by overfitting, after which test errors decrease and generalization occurs with even more parameters. The brain is heavily overparameterized, but the double descent phenomenon suggests that, coupled with regularization (e.g., energy costs), this can indeed aid generalization.
I hope these questions and answers are helpful for your studies! Let me know if you have any further questions.
Multiple choice questions by NotebookLM
multiple choice by notebookLM 1
multiple choice by notebookLM 2
Sure! Here are 25 multiple-choice questions about the lecture content, each with one correct answer, and the answers at the end.
Questions:
-
What is a main goal of neuroconnectionism?
- a) Developing new computer hardware components.
- b) Testing hypotheses about the brain using artificial neural networks.
- c) Improving robot performance.
- d) Exploring the history of machine learning.
-
What type of analysis is used to investigate similarity between neural representations?
- a) Fourier analysis
- b) Principal component analysis (PCA)
- c) Representational similarity analysis (RSA)
- d) Cluster analysis
-
What does the term “topographical organization” mean in the context of neural networks?
- a) A random arrangement of neurons.
- b) An arrangement of neurons reflecting spatial relations in the input.
- c) A hierarchical structuring of neurons.
- d) An arrangement of neurons based on their activity.
-
What is an advantage of using overparameterized Bayesian Neural Networks (BNNs)?
- a) They are easier to train.
- b) They always deliver the best results.
- c) They can understand and communicate the structure of the world in a human-like way.
- d) They are faster at computation.
-
What is the goal of “feature visualization” in deep neural networks (DNNs)?
- a) Improving network architecture design.
- b) Increasing network performance in image recognition.
- c) Identifying preferred stimuli for individual network units.
- d) Accelerating network training.
-
What does the term “few-shot learning” describe?
- a) Training a network with a large amount of data.
- b) Training a network with a very small amount of data.
- c) Training a network without any data.
- d) Training a network for very specific tasks.
-
Which of the following tasks is typically associated with Convolutional Neural Networks (CNNs)?
- a) Text generation
- b) Speech recognition
- c) Image recognition
- d) Time series analysis
-
What is the importance of “backpropagation” in the context of deep learning?
- a) It is an algorithm to reduce neural networks.
- b) It is an algorithm to train the network by minimizing errors.
- c) It’s a method to increase the accuracy of training data.
- d) It’s a visualization technique to understand neuron activity.
-
What is the main feature of “self-supervised learning”?
- a) It uses only labeled data.
- b) It uses only unlabeled data.
- c) It uses a mix of labeled and unlabeled data.
- d) It requires no training data.
-
What does the term “catastrophic forgetting” describe?
- a) A problem when training with small datasets.
- b) Rapid unlearning of previously learned information when training new tasks.
- c) A method to regularize the network.
- d) The inability to learn new tasks.
-
What is “episodic memory” in the context of reinforcement learning?
- a) Long-term storage of knowledge.
- b) Quick learning of individual tasks.
- c) Storing specific experiences to make decisions in similar situations.
- d) A method of data augmentation.
-
Which type of network is commonly used for sequence data like speech?
- a) Feedforward Neural Network
- b) Convolutional Neural Network
- c) Recurrent Neural Network
- d) Generative Adversarial Network
-
What is the function of “attention” in transformer networks?
- a) Reducing the complexity of input data.
- b) Focusing specifically on relevant parts of the input data.
- c) Increasing the speed of the training process.
- d) Preventing overfitting.
-
What is “inductive bias” in relation to artificial intelligence?
- a) A method to regularize the network.
- b) A predisposition that leads the network to favor certain patterns.
- c) A learning method without explicit data.
- d) Avoiding learning false patterns.
-
What is the role of “grid cells” in the brain and navigation?
- a) They are responsible for processing visual stimuli.
- b) They are involved in encoding space and position in space.
- c) They are responsible for processing emotions.
- d) They control motor skills.
-
What is the “bias-variance trade-off” in machine learning?
- a) The ratio between dataset size and model complexity.
- b) The ratio between computation time and model accuracy.
- c) The trade-off between a model’s ability to fit training data and generalize to new data.
- d) The ratio between input and output layers of a network.
-
What is the goal of “Representational Dissimilarity Matrices (RDMs)” in neuroscience?
- a) Visualizing patterns of neural activation.
- b) Depicting similarities or differences between stimulus representations.
- c) Training neural networks.
- d) Reducing the dimensionality of datasets.
-
What role do “critical periods” play in learning, especially regarding the development of neural networks?
- a) They extend training time.
- b) They influence how structures (not just weightings) change during training.
- c) They are irrelevant to the learning process.
- d) They limit the maximum performance of the network.
-
What does the term “cross-validation” describe?
- a) A method to increase the number of training data.
- b) A method to verify if a model generalizes well to independent data.
- c) A method to regularize the network.
- d) A visualization technique to understand neuron activity.
-
What are “Generative Adversarial Networks (GANs)”?
- a) A tool for reducing data dimensionality.
- b) A network used to generate new, similar data.
- c) Models used to model sequence data.
- d) Models used for classification.
-
What is the goal of “masking” studies in relation to the visual system?
- a) Reducing the complexity of images.
- b) Suppressing the processing of visual information.
- c) Adding noise to visual data.
- d) Improving object detection.
-
What is the difference between “encodability” and “decodability” in the context of neural representations?
- a) Encodability measures how well a model can predict neural data; decodability measures how well predictions can be made from neural data.
- b) There is no difference; both terms describe model performance.
- c) Encodability is a model’s ability to classify, decodability is its ability to regress.
- d) Encodability is the ability to process input, decodability is the ability to process output.
-
What is the function of the “softmax” function in a neural network?
- a) To normalize activations so they can be interpreted as probabilities.
- b) To restrict activations to 0 or 1.
- c) To linearly transform activations.
- d) To exponentially increase activations.
-
What is a main argument of Hasson et al. regarding the relationship between ANNs and the brain?
- a) They are causative but not generative.
- b) They are generative but not causative.
- c) They are neither causative nor generative.
- d) They are both causative and generative.
-
What is a challenge in using language models to model brain activity?
- a) The low complexity of language models.
- b) The lack of publicly accessible brain data.
- c) The low reliability of neural data in language tasks.
- d) The inability of language models to capture semantic relationships.
Meine antworten:
1b 2c 3b 4a 5c 6b 7c 8b 9b 10b 11c 12c 13b 14b 15b 16c 17b 18b 19b 20b 21b 22a 23a 24a 25c
4c
24c
Answers:
- b
- c
- b
- c
- c
- b
- c
- b
- b
- b
- c
- c
- b
- b
- b
- c
- b
- b
- b
- b
- b
- a
- a
- c
- c
Multiple-Choice Questions on Lecture Content
- What role does Meta-Reinforcement Learning (Meta-RL) play in the context of Dopamine (DA) and the prefrontal cortex (PFC)?
- a) It reduces the significance of the RPE model of DA function.
- b) It proposes a new RPE model of DA function for a new context.
- c) It explains the function of PFC without considering dopamine’s role.
- d) It ignores the importance of simulations for understanding DA and PFC.
- What is the main function of grid cells in spatial navigation according to the sources?
- a) They serve as pure reward indicators.
- b) They directly control the agent’s motor activity.
- c) They encode spatial metrics and facilitate navigation.
- d) They are replaced by place cells and other neural representations.
- Which statement best describes the outcome of a study on semantic scene descriptions in visual processing?
- a) Object labels are sufficient to describe visual representations.
- b) Semantic scene descriptions better characterize visual activity than object labels.
- c) Semantic information cannot be decoded from brain activity.
- d) Linear transformations are sufficient to generate complex semantic descriptions.
- What is the main goal of Representational Similarity Analysis (RSA)?
- a) To directly compare the activity of individual neurons in the brain and models.
- b) To use the distance between activity patterns to assess representation similarity.
- c) To reduce the complexity of neural networks through dimensionality reduction.
- d) To ignore the significance of distance metrics in neural networks.
- How is feature visualization used to understand neural networks?
- a) By directly measuring brain cell activity.
- b) By manipulating images and observing network unit reactions.
- c) By applying random disturbances to network architecture.
- d) By reducing the number of connections in a neural network.
- What is a central point in the discussion about the dimensionality of representations?
- a) Low dimensionality is always better for better generalization.
- b) High dimensionality is always better for increased storage capacity.
- c) There are arguments for both low and high dimensionality depending on context and task.
- d) The dimensionality of representations has no impact on model performance.
- What’s an important distinction between feedforward and recurrent networks?
- a) Feedforward networks can better capture recursive structures.
- b) Recurrent networks iteratively refine processing using feedback connections.
- c) Feedforward networks are more complex in all aspects than recurrent networks.
- d) Recurrent networks cannot be interpreted as feedforward networks.
- What do studies about adversarial attacks show about neural representations?
- a) They are always stable and resistant to small changes.
- b) They can be significantly affected by small targeted image changes.
- c) Adversarially trained artificial neurons are less robust than biological neurons.
- d) Adversarial attacks have no impact on network performance.
- Why are generative models considered important for understanding perception?
- a) They reduce the complexity of perception and cognition.
- b) They can generate sensory data from underlying causes.
- c) They are unimportant for understanding neural topography.
- d) They ignore the concept of data representation in the brain.
-
What does the concept of topography describe in neural networks?
- a) The spatial organization of neural activity.
- b) The absence of spatial organization in neural networks.
- c) The random arrangement of neurons in the network.
- d) The irrelevance of neural organization for network function.
-
What role do language models like GPT-2 play in brain research?
- a) They serve as pure replicas of brain structures.
- b) They are potential models for language processing in the brain.
- c) They are too simple to capture the complexity of human language.
- d) Their results show that predictive processing does not fundamentally shape language processing.
-
Why is self-supervised learning considered a biologically plausible alternative to supervised learning?
- a) It requires large quantities of manually annotated data.
- b) It better mimics how humans and animals learn.
- c) It always results in worse performance than supervised learning.
- d) It ignores the importance of feedback in learning processes.
-
What shift is suggested regarding the goal of visual processing?
- a) From semantic scene descriptions to categories.
- b) From categories to semantic scene descriptions.
- c) The importance of semantic scene descriptions is ignored.
- d) The importance of categorization is emphasized.
-
What is the implication if a representation is too high dimensional?
- a) It can improve generalization ability.
- b) It can lead to overfitting and redundant features.
- c) It always leads to better performance.
- d) It has no impact on information encoding.
-
What is the main goal of masking studies?
- a) To test the function of specific paths in a model.
- b) To improve model performance.
- c) To increase model complexity.
- d) To reduce noise in the model.
-
What role does feedback play in visual processing according to the sources?
- a) It has no impact on early processing.
- b) It is important for iteratively refining processing.
- c) It can be mimicked by a pure feedforward model.
- d) It speeds up processing.
-
What’s the surprising result regarding representational drift over time?
- a) Representations always stay stable.
- b) Representations change unexpectedly and unpredictably.
- c) Representations show steady performance improvement.
- d) Drift shows no change, proving stability of representations.
-
Why is it difficult to study learning in younger individuals?
- a) They have more stable representations.
- b) Their learning processes are more complex and less predictable.
- c) It’s easier to experiment with older individuals.
- d) Ethical considerations with children are irrelevant.
-
What is a loss function?
- a) A function that quantifies prediction accuracy.
- b) A function solely related to network architecture.
- c) A function that transforms input data.
- d) A function that measures the size of the network.
-
What’s an important property of topographic neural networks?
- a) They reflect the spatial arrangement of neurons in the brain.
- b) They are not dependent on the spatial arrangement of neurons.
- c) They show no selectivity in the center of the visual field.
- d) They are fully replicated by CNNs.
-
What’s the core idea behind using prototypes in few-shot learning?
- a) They use all training examples for classification.
- b) They classify data points based on their distance to an average value.
- c) They ignore the distance between data points.
- d) They complicate classification with few examples.
-
What purpose does the attention mechanism serve in a transformer model?
- a) It disregards input relevance.
- b) It calculates the importance of each input token in context of others.
- c) It only normalizes the output of the previous layer.
- d) It generates pure noise patterns.
-
What’s the main issue with using classification metrics for DNNs?
- a) They reward models that are too good for a small number of tasks.
- b) They reward models good for a broad range of tasks.
- c) They are highly correlated with neural coding performance.
- d) They cannot be used by computational neuroscientists.
-
What is the main statement of the “No Free Lunch” theorems in optimization?
- a) There is one optimal algorithm for all optimization problems.
- b) All algorithms are on average equally good across all possible problems.
- c) Algorithms should always be used without any bias.
- d) Only some optimization algorithms can always lead to a solution.
-
What is the core problem regarding noise suppression in the context of neural dimensionality?
- a) It is always masked by the dimensionality of the neural space.
- b) It complicates understanding variance reduction in representations.
- c) It cannot distinguish between signal and noise dimensions in neural networks.
- d) It always produces a low dimension not correlated with neural dimensionality.
meine antworten:
1b 2c 3b 4b 5b 6c 7b 8b 9b 10a 11b 12b 13b 14b 15a 16b 17c 18b 19a 20a 21b 22b 23a 24d 25c
17f
24f
Antworten
1.b) 2.c) 3.b) 4.b) 5.b) 6.c) 7.b) 8.b) 9.b) 10.a) 11.b) 12.b) 13.b) 14.b) 15.a) 16.b) 17.b) 18.b) 19.a) 20.a) 21.b) 22.b) 23.a) 24.b) 25.c)
multiple choice questions by notebookLM 3
- What is a main goal of neuroconnectionism research?
- a) Developing algorithms for controlling robots.
- b) Using ANNs to gain insights into the understanding of mind and brain.
- c) Exploring the history of artificial intelligence.
- d) Developing new hardware architectures for computers.
- What is the main problem with using simple models with few parameters to explain intelligence?
- a) They are too simple to understand.
- b) They require too much computational power.
- c) They cannot capture the complexity of intelligence.
- d) They cannot predict neural responses.
- What does “synthetic neurophysiology” mean in the context of ANNs?
- a) Studying neural activity in animal brains.
- b) Using ANNs to simulate nerve conduction speeds.
- c) The detailed investigation of ANNs’ internal representations by testing with millions of input patterns.
- d) Developing new brain imaging techniques.
- What is an important feature of a “good” neural code according to current findings in computational neuroscience?
- a) A high number of dimensions to reduce noise.
- b) The ability to perform complex mathematical operations.
- c) High interpretability by human cognition.
- d) Reducing latent dimensionality to promote abstraction and invariance.
- Why might high-dimensional codes in neural networks be advantageous for representing new categories?
- a) They are easier to train.
- b) They are better interpretable.
- c) They allow for the representation of a greater variety of downstream readouts and have advantages in learning new categories through concentration phenomena.
- d) They reduce computational effort.
- What is the main problem with using classification metrics to evaluate DNNs?
- a) They are too complicated.
- b) They require too many computational resources.
- c) They are often optimal for a single task on a small, closed set of categories and may be less useful for representing new categories.
- d) They do not lead to a better prediction of neural activity.
- What problem in brain modeling is addressed by using overparameterized BNNs?
- a) The difficulty of explaining biological neural networks with simple models.
- b) The need to create exact copies of the human brain.
- c) The search for increasingly faster computers for training neural networks.
- d) The need to capture and interpret complex cognitive processes.
- Why is it important to use an independent test dataset when evaluating models?
- a) To save computational resources.
- b) To reduce training data.
- c) To avoid overfitting and ensure the model generalizes to unseen data.
- d) To improve the model’s interpretability.
- What is the goal of “representational similarity analysis” (RSA)?
- a) Developing algorithms to improve image recognition.
- b) Studying neural activity during language processing.
- c) Comparing representations in models and the brain by comparing their geometric structures.
- d) Exploring differences in brain structure across species.
- What type of distance measure should be used in RSA?
- a) It is irrelevant which distance measure is used.
- b) Only Euclidean distance is permissible.
- c) It depends on the type of data and the aspects to be highlighted; different distance measures offer different “lenses” on the data.
- d) One should always take the maximum distance.
- What is an important argument against the sole use of supervised learning to describe human learning processes?
- a) Supervised learning is too expensive and computationally intensive.
- b) Supervised learning is only suitable for very simple tasks.
- c) Children do not require large amounts of annotated data compared to the amounts ANNs require.
- d) Supervised learning cannot lead to complex concepts.
- What are the benefits of self-supervised learning in modeling brain activity?
- a) It requires a lot of manual work.
- b) It delivers better results than supervised learning in all cases.
- c) It allows learning with fewer annotated data and enables the development of models that exhibit good behaviors while also predicting neural data.
- d) It is less computationally intensive.
- What is a main goal of meta-learning?
- a) Developing neural networks that can solve only one task.
- b) Developing neural networks that can quickly learn new tasks.
- c) Reducing the number of parameters in neural networks.
- d) Improving the accuracy of neural networks in all applications.
- What describes the term “inductive bias” in relation to neural networks?
- a) The network’s ability to ignore new information.
- b) The predefined assumptions or constraints, embedded in the architecture or learning process of a neural network, to accelerate learning.
- c) The ability of a neural network to adapt to noisy data.
- d) A method of data augmentation.
- What is a “generative model” and why is it important in neuroscience?
- a) A model that classifies data.
- b) A model that generates random numbers.
- c) A model that models the underlying causes of data and can be used for inference, which is essential for understanding neural processing.
- d) A model that can only be used for supervised tasks.
- What is an essential feature of overparameterized models that makes them suitable for analyzing complex datasets?
- a) They are easy to interpret.
- b) They are computationally efficient.
- c) They are adaptable and can identify and utilize complex relationships in large data volumes.
- d) They are particularly suited for very simple datasets.
- What is the significance of the “No-Free-Lunch” theorem in the context of machine learning and neural networks?
- a) It states that all algorithms are equally good.
- b) It describes a method for accelerating neural network training.
- c) It states that no single algorithm is optimal for all problems.
- d) It describes a technique to reduce the complexity of neural networks.
- What is the significance of the term “representational geometry” in computational neuroscience?
- a) The geometric shape of the brain.
- b) The way different stimuli are arranged relative to each other in neural space, crucial for the region’s function.
- c) How information is transmitted through neurons.
- d) The structure of connections in a neural network.
- Why is it challenging to fit single neuron computational models to data from the inferior temporal cortex (IT)?
- a) There are too few stimuli to train these models.
- b) IT is too small a brain region.
- c) The model spaces are insufficiently defined and the number of parameters is too large in relation to the amount of available data.
- d) The function of individual IT neurons is too simple to model.
- What is “episodic memory” and why might it be relevant for learning in neural networks?
- a) A memory that only remembers facts.
- b) A memory specialized in long-term storage.
- c) A memory that stores specific events and can be relevant for fast learning.
- d) A memory relevant only for remembering faces.
- What is “continual learning” and why is it a challenge for neural networks?
- a) Learning that happens only once.
- b) Learning that proceeds at a constant speed.
- c) The ability to continuously learn new tasks without forgetting previous knowledge; for neural networks, this is challenging due to the risk of “catastrophic interference.”
- d) Storing information for only a short time.
- What is the main goal of “feature visualization” in deep learning models?
- a) Improving object recognition in images.
- b) Identifying preferred stimuli for individual units in a neural network.
- c) Reducing the computational complexity of a neural network.
- d) Optimizing the parameters of a neural network.
- What roles do “attention” and “top-down mechanisms” play in neural networks?
- a) They are not important for neural networks.
- b) They slow down the learning process.
- c) They are used in newer approaches to enable the allocation of information to neural circuits in different contexts and assist in continual learning.
- d) They lead to worse results.
- What are some of the “three components” of a good theory that explains the function of complex, hierarchical brain circuits, according to one of the sources?
- a) Input, Output, and Recurrent Layers
- b) Training, Validation, and Testing Data
- c) Architecture, Learning Rules, and Objective Functions
- d) Encoder, Decoder, and Attention Mechanisms
- What is the main point of Zador’s critique of “pure pedagogy” in machine learning?
- a) The inability of current algorithms to exactly mimic the brain.
- b) The overreliance on supervised learning algorithms and the lack of unsupervised paradigms, which are unnatural compared to children’s learning mechanisms.
- c) The lack of research on new architectures of neural networks.
- d) The neglect of the importance of mathematical models.
Meine antworten:
1b 2c 3c 4d 5c 6c 7d 8c 9c 10c 11c 12c 13b 14b 15c 16c 17a 18b 19c 20c 21c 22b 23c 24c 25b
7a
17c
Answers:
- b
- c
- c
- d
- c
- c
- a
- c
- c
- c
- c
- c
- b
- b
- c
- c
- c
- b
- c
- c
- c
- b
- c
- c
- b
Zusammenfassung des Kurses
Certainly! Here is a detailed briefing document summarizing the key topics and ideas from your sources, focusing on using quotes and organizing by themes:
Briefing Document: Meta-Learning, Neural Representations, and Deep Learning in Neuroscience
I. Meta-Learning and Reinforcement Learning
- DeepMind_PFC_Meta_Learning.pdf: Explores a Meta-Reinforcement Learning (Meta-RL) model capable of learning across episodes for efficient intra-episode learning.
- Architecture: Utilizes a recurrent neural network (RNN), modeled as a Prefrontal Network (PFN) with synaptic weights adjusted by an RL algorithm driven by dopamine (DA). LSTM units in PFN receive inputs from perception, previous action, and reward.
- Quote: “The prefrontal network (PFN), including sectors of the basal ganglia and the thalamus that connect directly with PFC, is modeled as a recurrent neural network, with synaptic weights adjusted through an RL algorithm driven by DA; o is perceptual input, a is action, r is reward, v is state value, t is time-step and δ is RPE.”
- Behavior: Demonstrates transition from exploration to exploitation in bandit tasks, slower for more complex problems.
- Quote: “The network shifts from exploration to exploitation, making this transition more slowly in the more difficult problem.”
- Encoding: Individual RNN units code for action and reward history. Network activity evolves within trials, reflecting reward probabilities.
- Quote: “individual units in simulated recurrent network code for action and reward history.”
- Two-Step Task: Displays model-based behavior in a two-step task.
- Quote: “Learned rL algorithm displays model-based behavior and rPes.”
- Implementation: Uses LSTM units. Dynamics described by standard equations:
- Quote: “The dynamics of the LSTM were governed by standard equations51,53:
- σ= + +−i W x W h b( )t xi t hi t i1
- σ= + +−f W x W h b( )t xf t hf t f1
- = ∘ + ∘ + +− −c f c i W x W h btanh( )t t t t xc t hc t c1 1
- σ= + +−o W x W h b( )t xo t ho t o1
- = ∘h o tanh c( )t t t
- where xt is the input to the LSTM at time t, ht is the hidden state, it is the input gate, ft is the forget/maintenance gate, ot is the output gate, ct is the cell state, σ is the sigmoid function, and ∘ is an operator denoting element-wise multiplication.”
- ML4CCN_Lecture9_Topography.pdf: Focuses on RNNs learning optimal internal dynamics and comparing RNN activity with RL processes.
- Quote: “RNN activity resembles RL: (1) integrating reward information”
- Meta-learning highlighted, with performance comparable to RL algorithms.
- Quote: “Performance results comparable with common RL algorithms designed for such tasks.”
- Quote: “Exploration → Exploitation”
- Richards_DL_Framework.pdf: Proposes that credit assignment in biological systems is solved by attention and neuromodulatory signals.
- Quote: “Attention-based models of credit assignment propose that the credit assignment problem is solved by the brain using attention and neuromodulatory signals.”
- Dendritic models suggest gradient signals via “dendritic error signals” (δ) in pyramidal neurons’ apical dendrites.
II. Neural Representations and Topography
- DeepMind_gridcells_modelling.pdf: Models the brain’s spatial navigation system using Deep Learning, generating neural representations like grid cells in the entorhinal cortex.
- Grid Cells: Linear layers develop spatial representations akin to the entorhinal cortex, showing hexagonal clustering.
- Quote: “the linear layer develops spatial representations similar to entorhinal cortex…exhibiting six-fold clustering reminiscent of conjunctive grid cells”
- Navigation: Capable of one-shot navigation to a hidden goal.
- Quote: “One-shot open field navigation to a hidden goal”
- Architecture: Uses an LSTM network for processing speed and direction.
- Quote: “The single recurrent layer is an LSTM (long short-term memory32) that projects to place and head direction units via the linear layer.”
- Supervised Learning: Receives linear velocity and angular velocity in the supervised setup.
- Quote: “In the supervised setup the grid cell network receives, at each step t, the egocentric linear velocity R∈vt and the sine and cosine of its angular velocity ϕt.”
- Loss Function: Grid cells and vision modules trained with the same loss function.
- Quote: “The grid cell network and the vision module were trained with the same loss reported for the supervised learning”
- Stability and Manipulation: Evaluates spatial activity stability and effects of silencing units.
- Quote: “For each unit, the reliability of spatial firing between baseline trials was assessed by calculating the spatial correlation between pairs of rate maps taken at two different logging steps in training”
- Hexagonal Regularity: Quantified using the gridness score.
- Quote: “The hexagonal regularity and scale of grid-like patterns were quantified using the gridness score18,20 and grid scale20, measures derived from the spatial autocorellogram20 of each unit’s ratemap.”
- ML4CCN_lecture11_embodiment.pdf: Explores navigation in the brain and machines, focusing on grid and place cells.
- Quote: “Biological brains likely perform this function via navigation-related cell types: grid cells (entorhinal cortex) and place cells (hippocampus).”
- ML4CCN_lecture12_QnA.pdf: Discusses using Mahalanobis distances and “Noise Ceiling” in model evaluation.
- Quote: “Mahalanobis distance takes the data distribution into account. Noisy dimensions are down weighted.”
- Quote: “Goal: test whether a SINGLE OBJECTIVE can yield dorsal and ventral stream representations”
III. Representational Similarity Analysis (RSA) and Model Comparison
- Kietzmann_Oxford_Encyclopedia.pdf: Describes RSA to compare internal representations in DNNs and the brain.
- RDMs: RSA based on Representational Dissimilarity Matrices storing system response dissimilarities.
- Quote: “RSA is based around the concept of a representational dissimilarity matrix (RDM), which stores the dissimilarities of a system’s responses (neural or model) to all pairs of experimental conditions.”
- Comparison: Models similar to brain representations if they produce similar RDMs.
- Quote: “A model representation is considered similar to a brain representation to the degree that it emphasizes the same distinctions among the stimuli, that is, the model and brain are considered similar if they elicit similar RDMs.”
- Unsupervised Learning: Highlights unsupervised goals like sparsity and stability.
- Quote: “One influential suggestion is that neurons in the brain aim at an efficient sparse code, while faithfully representing the external information.”
- Quote: “the temporal stability or slowness objective is based on the insight that latent variables that vary slowly over time are useful for adaptive behavior.”
- Kriegeskorte_Kievit_Representational_Geometries.pdf: Explains population codes and the use of tuning curves, emphasizing similarity concepts.
- Quote: “Population code: scheme for encoding information thought to be important to the organism in the activity of a population of neurons.”
- ML4CCN_lecture3_RSA.pdf: Covers RSA fundamentals, comparing systems by representational geometry.
- Quote: “Core idea: to compare different systems, we can compare their representational geometry”
- Distance Measures: Various metrics discussed.
- Quote: “Euclidean Distance (L2), Manhattan Distance (L1), Cosine Similarity, Pearson Similarity”
- Quote: “Mahalanobis distance takes the data distribution into account. Noisy dimensions are down weighted.”
- Comparing RDMs: Describes RDM comparison and distance metrics as data lens.
- Quote: “Distance measures are a “lens” onto your data, highlighting some aspects, while ignoring others.”
- Noise Ceilings: Introduces “Noise Ceiling” to assess model quality.
- Quote: “Upper Bound (overfitted) - what is the best possible model… Lower Bound (cross-validated) - how well do participants predict each other”
- Doerig_Neuroconnectionism.pdf: Details RSA application for population analysis and encoding models for predicting neuron activity.
- Quote: “In addition to RSA, which is predominantly aimed at characterizing responses at the population level, encoding models can be used to predict the activity of single neurons or voxels across a range of conditions.”
- Doerig_Visual_Semantics.pdf: Describes constructing RDMs from participant beta-weights using volumetric searchlight analysis.
- Quote: “Representational dissimilarity matrices were constructed from participants’ native space single-trial beta weights using a volumetric searchlight analysis 73,74. For each voxel v, we extracted condition-specific activity patterns in a sphere centred at v with a radius of 5 voxels (searchlight at v).”
IV. Deep Learning and Architecture
- Lillicrap_NGRAD.pdf: Describes backpropagation for error gradient calculation and target propagation algorithms.
- Quote: “The key insight behind the backprop algorithm is that the δ terms, sometimes called ‘error signals’, can be computed recursively via the chain rule”
- Target Propagation: Corrects feedback errors by adding corrections to targets.
- Quote: “To compensate for imperfections in the auto-encoders, we add the modified target at level l+1 backward through these approximate inverses and use the result to make a linear correction to the target at level l”
- The_Illustrated_Transformer_: Visualizes Transformer model with emphasis on Multi-Head-Self-Attention.
- Self-Attention: Describes how self-attention works and combines Z matrices.
- Quote: “If we do the same self-attention calculation we outlined above, just eight different times with different weight matrices, we end up with eight different Z matrices”
- Quote: “The feed-forward layer is not expecting eight matrices – it’s expecting a single matrix (a vector for each word). So we need a way to condense these eight down into a single matrix.”
- Decoder: Describes decoder functioning, including attention vectors K and V.
- Yamins_Goal_driven_deep_learning.pdf: Discusses using Goal-driven models to understand sensory cortex, with “LN” motif and “HCNN layer.”
- Quote: “The specific operations comprising a single HCNN layer were inspired by the ubiquitously observed linear-nonlinear (LN) neural motif5.”
- Describes generating synthetic neural responses.
- Quote: “rsynth(x) ≈ ∑i ci mi(x) where r(x) is the response of neuron r to stimulus x, and mi(x) is the response of the i-th model unit (in some fixed model layer).”
V. Representational Dimensionality and Overfitting
- Elmoznino.pdf: Discusses pros and cons of low vs. high dimensionality in networks, arguing low dimensionality improves generalization and robustness.
- Quote: “it is argued that low dimensionality improves a network’s generalization performance, its robustness to noise, and its ability to separate stimuli into meaningful categories.”
- High dimensionality benefits include efficient resource use and expressivity.
- Quote: “there are also potential benefits of high-dimensional manifolds, including the efficient utilization of a network’s representational resources and increased expressivity, making for a greater number of potential linear readouts”
- Describes modeling intrinsic dimensionality.
- Quote: “λi = e−sAPa←bxi”
- Describes noise impact based on variance.
- Quote: “Essentially, ecological/model dimensions with high variance were relatively unaffected by the noise and accurately encoded stimulus features, whereas dimensions with low variance were dominated by the noise and only coarsely encoded stimulus features”
- ML4CCN_lecture2_neuroconnectionism1.pdf: Covers overfitting and “Feature Fallacy,” cautioning against equating model success with feature confirmation.
- Quote: “Careful when interpreting the success of a model as confirmation of its basis set of features”
- Discusses high dimensionality’s relationship with better brain predictions.
- Quote: “High intrinsic dimensionality = better brain predictions”
VI. Language Modeling and “Normative Modeling”
- Schrimpf_pnas.2105646118.pdf: This paper investigates how well language models can predict brain activity during language processing by comparing neural representations with fMRI and ECoG responses.
- Quote: “Models Humans … Internal Neural Representations Hidden unit activations … fMRI and ECoG responses … predict brain score”
- Evaluates various models.
- Also explores connections to reading time predictions.
- ML4CCN_lecture10_language.pdf: Covers attention mechanisms and context vectors.
- Attention: The function and mechanics of attention are explained.
- Quote: “Attention and context vectors… = attentional weight at time t for input i”
- Demonstrates the use of attention in seq2seq models and translation.
- Quote: “The concept of how to use attention in DNNs is largely preserved across domains”
- Discusses models like GPT-2 and their underlying architectures.
- Quote: “Based on transformer architecture. However, it only uses a decoder and is trained to predict the next word in a sentence.”
- ML4CCN_lecture4_normativeModellingHistory.pdf: Introduces the idea of “normative modeling”:
- Quote: “By understanding which objectives render ANNs brain-like”
- Emphasizes that not all visual processing models are supervised or trained with gradient descent.
- Quote: “Not all models are supervised and trained using gradient descent. Many of them rely on other objectives and other learning rules.”
- ML4CCN_lecture10_language.pdf: Questions whether auditory processing can be modeled similarly to visual processing.
- Quote: “Normative models have seen success in vision. Can we expand this to other sensory modalities, such as audition?”
VII. Critique of the “Pure Learning” Approach
- Zador_critique_of_pure_learning.pdf: Critiques “pure learning” approaches emphasizing that neural circuitry is shaped by evolution, not just learning.
- Argues that learning methods without biological constraints can lead to outcomes far from biological reality.
VIII. Adversarial Robustness
- guo22d.pdf: Examines the sensitivity of IT cells to adversarial disruptions, showing they are not as robust as adversarially-trained artificial neurons.
- Quote: “Adversarially-trained artificial neurons are more robust than biological neurons”
- Shows that the “category preference” of individual IT neurons can be altered by small pixel perturbations.
- Quote: “Adversarial perturbations on non-preferred images (in blue) are able to drive firing rates past that of naturally occurring preferred images…and by ϵ = 10 turn non-preferred images into ‘super-stimuli’ (individual sites in light blue, average in dark blue n=17).”
IX. Other Topics
- vanBergen_going_in_circles.pdf: References dynamic routing and capsule networks for visual segmentation and grouping.
- Quote: “Introduced the influential Capsule Networks, which implement iterative recurrent information routing dynamics for visual segmentation and grouping.”
Summary
These sources illuminate various topics at the intersection of neuroscience, artificial intelligence, and deep learning. From modeling meta-learning and navigation to analyzing representational geometries, language technologies, and the significance of adversarial robustness. The documents highlight the growing effort to understand brain function through deep learning and the constraints to be considered.
I hope this comprehensive briefing document is helpful for you! Let me know if you have further questions.
Questions
Certainly, here are some questions you can use to prepare for your exam based on the given sources:
Basics and Concepts
- What are Marr’s three levels of analysis and how do they relate to understanding the brain?
- computational theory
- representation and algorithm
- hardware implementation
- Explain the concept of the “Bias-Variance Tradeoff” in the context of machine learning and its relation to neural network complexity.
- a higher inductive bias means the model will fit worse to the data, but can generalize more meaning you get higher variance
- if you want to lower variance you need to have a weaker inductive bias and therefore you model overfits to the data
- What are the main differences between supervised, unsupervised, and self-supervised learning?
- supervised: the model has a teacher that tells him: this is the image of a dog. So every image is labelled. That’s how the model learns predictions
- unsupervised: the model does not have a teacher als looks for clusters and patterns to sort the data
- self-supervised: it takes information from labelled data and then starts labelleling data itself.
- Describe the concept of “Representational Similarity Analysis” (RSA) and how it is used in neuroscience and computer science.
- Explain “Credit Assignment” in the context of neural networks.
- What is the difference between a “direct-fit” and an “ideal-fit” model, and when is each appropriate?
- What are the minimal criteria for a sensory encoding model?
- What is the difference between a “metamer” and an “adversarial example”?
- What does “amortized inference” mean?
Neural Networks and Deep Learning
- How can deep neural networks (DNNs) be used as models for the brain, and what advantages does this approach offer?
- What roles do different architectures (e.g., ResNet, LSTM, Transformer) and training methods play in the performance of DNNs?
- Describe the function of LSTM units in a recurrent neural network (RNN) as presented in the source.
- How are neural networks tested in “in-silico” experiments, and what are the advantages of this over traditional biological experiments?
- Explain the concept of “goal-driven networks” and how they differ from other neural system models.
- How are optimization methods like Backpropagation used in neural networks?
- What are “lottery tickets” in neural networks?
- In what way can the brain be viewed as an “over-parameterized modeling organ”?
Applications and Tasks
- How is Meta-RL used to enhance learning in neural networks as shown in the source?
- Describe the tasks used in the source simulations, such as “bandit problems” or “goal-doors tasks.”
- How can neural networks be utilized for understanding language, such as using “next-word-prediction” tasks?
- Explain how the performance of neural networks in different tasks (e.g., image recognition, language processing, navigation) is compared with brain activity.
- How are “adversarial attacks” used to test the robustness of neural networks and biological neurons?
- How can “Grid-Cell Activity” be simulated in neural networks for navigation?
- How can tasks be seen as “controlled environments for behavior” used in AI and cognitive neuroscience?
Theoretical Questions and Perspectives
- What are the main goals of neuroconnectionism as a research program?
- What role does the “objective function” play in neural networks, and how can it be linked to biological processes?
- How can parameters and architecture of neural networks be related to specific hypotheses about brain function?
- What are the challenges and limitations of using DNNs to model the brain?
- What new research questions arise from using deep learning in neuroscience?
- How is the brain characterized by a balance between “statistical and computational efficiency”?
- What role does iterative processing play in neural networks?
Experimental and Methodological Aspects
- What are the different ways to measure neuron activity in biological systems (e.g., fMRI, EEG, single-cell recordings), and how do they differ in space, time, and invasiveness?
- How can the dimensionality of neural representations in DNNs and the brain be analyzed and compared?
- How is “cross-validation” used to test the generalization ability of neural networks?
- How can generative models be used to understand the development of neural representations?
- What are the pros and cons of using “natural images” versus “simplified stimuli” in neuroscience experiments?
- What are the challenges in collecting and analyzing large datasets in neuroscience and AI?
- How can models be used to explore “representational geometries”?
Additional Questions
- How are the concepts of “continual learning” and “catastrophic interference” related to the challenges of learning in biological systems?
- How can the “topographical organization” of neural networks be compared with the structure of the brain?
- Why is it important to consider the “dynamics” of neural activity rather than just temporal averages?
Sure, here are additional questions to help you prepare for your exam, building on the given sources and our previous discussion:
Neuroconnectionism and Research Programs
- How does neuroconnectionism, as described in the sources, represent a Lakatosian research program? What roles do “belt” hypotheses and the “core” of the program play?
- Evaluate the productivity of neuroconnectionism in generating new insights and addressing existing challenges.
- What role do “shortcomings” play in a progressive research program like neuroconnectionism, and how can they serve as “signposts”?
- What are the main differences between the “bottom-up” and “top-down” approaches to understanding the brain, and how are both considered in neuroconnectionism?
Neural Networks and Their Interpretation
- What does “in silico electrophysiology” mean regarding DNNs, and how can it help understand unit selectivity?
- How can “network dissection” quantify and interpret unit selectivity in a DNN?
- Why is it important to understand the “latent dimensionality” of DNN representations, and how does it affect the ability to explain brain activity patterns?
- How does the relationship between DNN performance in image classification and their ability to explain cortical data shift at very high classification accuracy?
- How can we compare the geometric properties of neural representations in DNNs and the brain, and what methods are used, such as Representational Dissimilarity Matrices (RDMs)?
- Why might a representation be too high-dimensional, and what role does dimensionality play in generalization?
- In what way does the update of weights in neural networks resemble a local Hebbian learning mechanism?
- How do NGRADs overcome the biological implausibilities of backpropagation, and how do they implement error signal computation?
- What is the difference between an “unrolled RNN” and a “standard feedforward network”?
Learning and Tasks
- What are the critical factors that favor “Meta-RL effects” in the prefrontal cortex (PFC), and why might they be unique to this circuit?
- How does “meta-learning” differ from traditional learning approaches, and why is it important to consider continuous learning and adaptation in dynamic environments?
- What role do dopamine signals play in the context of Meta-RL, and what are the connections between mesolimbic, mesocortical, and nigrostriatal pathways?
- How do tasks influence the development of AI models and the gathering of brain and behavioral data?
- What are the pros and cons of “supervised,” “unsupervised,” “self-supervised,” and “semi-supervised” tasks?
- How can a task be used to test which function a component in a model is oriented towards?
Representational Geometry and Models
- What is a “representational geometry,” and how can we compare different stimulus responses with this geometry?
- How can “tuning curves” influence our representation and relate to the brain’s needs?
- Why can different “tuning curves” of individual neurons still lead to identical representational geometry?
- What is the difference between “encodability” and “decodability”?
- How is the “noise ceiling” calculated when evaluating models?
- What is the significance of comparing RDMs between brains, behaviors, and models, and what can these comparisons reveal?
- How can “representational models” be used to make comprehensive predictions about the “representational space” of a brain region?
- How does the approach to modeling representational geometries differ from other approaches, e.g., decoding models or connectivity models?
Dynamics and Relevance
- How can “iterative processing” be considered a way to refine input interpretation in the visual system?
- How do feedback connections affect processing in the visual cortex, and what roles do they play in attention and expectation?
- How can tasks examining the dynamic interaction of brain and behavior, such as “active vision,” improve our understanding of the brain?
- How can the analysis of “learning trajectories” and complex behaviors supplement the correlation of representations in brains and DNNs?
- What is the significance of “representational drift” for our understanding of continuous learning?
Experimental Aspects and Methodological Questions
- How can we measure and compare the “adversarial sensitivity” of neural representations in DNNs and biological networks?
- How can “controversial stimuli” be used to test neural networks as models of human cognition?
- What role does stimulus selection play in investigating neural representation, and why shouldn’t we rely solely on “ImageNet”?
- What is “searchlight analysis,” and how is it used to explore brain-model correspondence?
- How can we gain a better understanding of brain activity by examining “temporal trajectories” instead of temporal averages?
Additional Considerations
- How can we understand the concepts of “invariance” and “equivariance” in the context of neural representations and models?
- Why is it important to consider the “inductive biases” of neural networks, and how can we deploy them deliberately?
- What role does “curiosity” play in active learning, and how can we implement this mechanism in neural models?
- What is the “Goldilocks effect” in the context of learning processes, and why shouldn’t we only focus on the “simplest” or “most complex” models?
These questions aim to deepen your understanding, foster connections among various concepts, and encourage a critical view of the research field. Good luck!
Study Guide for Reviewing Understanding of Source Materials
Short Answer Questions
- Briefly describe how the Prefrontal Network (PFN) was modeled in the simulations of the DeepMind study and the role that dopaminergic (DA) feedback plays.
- Explain the purpose of the LSTM (Long Short-Term Memory) in the context of the meta-RL agent described in the sources.
- What is “Cumulative Regret” and why is it used to evaluate the performance of bandit algorithms?
- How are grid cells neurally represented in the study modeling grid cells?
- Briefly explain how the authors demonstrate that the networks in the Grid-Cell study learn in a “model-based” manner.
- What are Representation Similarity Matrices (RDMs) and how are they used in comparative analysis between brain and DNN representations?
- Name three “unsupervised” goals that are described in the texts as being pursued by neurons.
- What is the main problem with “backpropagation” that “target propagation” aims to solve?
- Describe the difference between an “Encoding Model” and “Representational Similarity Analysis” (RSA) in the context of analyzing neural data with DNNs.
- What is “attention” in a transformer network and how does it work?
Answer Key
- The PFN was modeled as a recurrent neural network whose synaptic weights are adjusted by a reinforcement learning algorithm driven by DA, which acts as a “Reward Prediction Error” (RPE).
- The LSTM is a type of recurrent neural network specifically designed to learn long-term dependencies in sequential data, making it useful for learning meta-RL strategies in episode-based learning tasks.
- “Cumulative Regret” is the cumulative measure of loss (in expected rewards) incurred when selecting suboptimal, lower reward arms in a multi-armed bandit problem. It quantifies the performance of an agent.
- Grid cells are represented by a recurrent LSTM network, projected with linear layers to place and head-direction cells, tracking movements in space.
- The study analyzes the network’s behavior in a two-step task and shows that the network accounts for both “common” and “uncommon” transitions, indicating it is not only learning “model-free” but developing a representation of the underlying model.
- RDMs store the dissimilarities of reactions from a system (neural or model) to all pairs of experimental conditions, which can be read as a “representational geometry”. Similarities between brain and model RDMs indicate similarities in their underlying representations.
- Three “unsupervised” goals are: encoding sparse representations, compressing inputs to the fewest neural dimensions, and temporal stability.
- Backpropagation requires a global computation of gradients; “target propagation” avoids this by using approximate local “inverses” to propagate errors.
- Encoding models attempt to predict the activity of individual neurons or voxels as a linear combination of DNN units, while RSA compares the similarity of patterns of brain and model activities on a population level using RDMs.
- Attention in a transformer is a mechanism that allows the network to learn to weigh certain parts of the input sequence differently to take more relevant information into account for output calculation, especially regarding contextual understanding in language.
Essay Questions
- Discuss the significance of using recurrent neural networks (RNNs) in DeepMind studies, particularly in terms of their ability to capture temporal dependencies. Compare their use in meta-RL and grid-cell models.
- Evaluate the evidence in the texts that both biological and artificial neural networks use high dimensionality, especially regarding data capture and the ability to generalize.
- Analyze the various “Normative Models” described in the texts. Discuss the pros and cons of each approach and how they can be applied to understanding the brain.
- Discuss the strengths and weaknesses of RSA as a methodology. How does RSA approach the problem of interpreting brain and model representations?
- Compare and contrast the different approaches to credit assignment in the biological brain and deep learning systems, discussing the presented models of “backpropagation”, “target propagation”, and “dendritic error signals”.
Glossary of Key Terms
- Reinforcement Learning (RL): A machine learning paradigm in which an agent learns to make decisions by interacting with an environment to maximize cumulative reward.
- Meta-RL: A form of reinforcement learning in which an agent learns how to learn, i.e., how to adapt to new tasks or environments.
- LSTM (Long Short-Term Memory): A type of RNN characterized by its ability to learn and store long-term dependencies in sequential data.
- RPE (Reward Prediction Error): The difference between the expected reward and the actually received reward.
- Cumulative Regret: The cumulative measure of the loss incurred when making suboptimal decisions in a learning task.
- Grid Cells: Neurons in the brain that function as part of the spatial navigation system, with periodic activity patterns.
- Place Cells: Neurons in the brain that are active at specific locations in space, helping to form a map of the environment.
- Head-Direction Cells: Neurons in the brain that fire when the animal faces a certain direction.
- Representational Similarity Analysis (RSA): A method of comparing neural, behavioral, or model representations by comparing the dissimilarity of response patterns.
- Representational Dissimilarity Matrix (RDM): A matrix that represents the dissimilarities between all pairs of experimental conditions in a system.
- Encoding Model: A model that attempts to predict the activity of individual neurons or voxels based on DNN activations.
- Normative Model: A model attempting to understand brain computation by finding models that perform the same goal.
- Backpropagation: An algorithm used in neural networks to update the weights by propagating the error back through the network.
- Target Propagation: A family of algorithms representing an alternative to “backpropagation” by using approximate local inverses to propagate errors.
- Attention (Transformer): A mechanism that allows the model to selectively focus on different parts of an input sequence, learning complex relationships between elements.
- Overfitting: A situation where a model is too well-fitted to the training data and unable to generalize well to new data.
- Dropout: A regularization technique where randomly selected neurons are deactivated during training to prevent overfitting.
- Manifold: A “low-dimensional surface” on which the data lies, which can reduce data dimensionality and thus improve interpretation and generalization.
- Mahalanobis Distance: A distance metric considering the covariance of data, suitable for analysis in high-dimensional, correlated data.
- Gradient Descent: An optimization algorithm for minimizing a loss function by iteratively adjusting parameters in the direction of the negative gradient.
- Temporal Stability/Slowness: A principle suggesting the brain favors variables that change slowly over time, filtering relevant information from noise.
- Sparse Coding: A concept assuming an efficient neural coding system uses as few neurons as possible to represent information.
- Adversarial Attack: The manipulation of an input to fool a model or provoke errors.
- Neuron: A nerve cell consisting of a cell body, an axon, and dendrites involved in processing and transmitting information in the brain.
- Dendrites: Branch-like extensions from the neuron body that receive signals from other neurons.
- Axon: A long, thin extension of the nerve cell that transmits electrical signals to other neurons.
- Neurotransmitter: Chemical messengers that transmit signals between nerve cells in the brain.
- Synapse: A junction between two neurons through which signals are transmitted.
- Von Mises Distribution: A probability distribution on a circle, similar to the normal distribution on a line, used for describing cyclic quantities.
- RMSprop: An optimization algorithm that adjusts learning rates for each parameter based on the size of their recent gradients.
See also
Status:
Tags: cognitivescience science
Superlink: 611 📠Machine Learning
610 🤖Artificial Intelligence, Künstliche Intelligenz
410 👨💻Uni und Lernen
Quellen
Erstellt: 29-10-24 22:55