Excel in handling sequential data, like text and time series.
Key innovation: self-attention mechanism, allowing models to weigh the importance of different input parts.
Highly effective in NLP tasks: translation, summarization, question-answering.
Architecture consists of encoder and decoder layers; some models use only encoders (e.g., BERT) or decoders (e.g., GPT) for specific tasks.
Scalable and parallelizable, leading to large, powerful models.
Pre-training and fine-tuning approach enables adaptation to various tasks with minimal task-specific data.
Transformers have set new standards in accuracy for many NLP benchmarks.
How does a transformer work?
Transformers are a type of deep learning model that process data in parallel, making them highly efficient for tasks like natural language processing (NLP). They rely on a mechanism called self-attention to weigh the importance of different words in a sentence, enabling them to understand context and relationships between words. Transformers consist of two main parts: the encoder, which processes the input data, and the decoder, which generates the output. This architecture allows them to excel at tasks such as translation, text summarization, and question answering by capturing complex dependencies in data.
Embedding
Transformers use Embedding to transform words into numbers.
Every word in a dictionary has its own code.
Positional Encoding
Every word has its position encoded. For every position, there is a different wave length, therefore resulting in different numbers for each position.
🐍 Figure — Sinusoidal positional encoding (Vaswani et al. 2017)
What this shows. Left: the full (50 × 64) positional-encoding matrix as a heatmap — one row per token position, one column per embedding dimension, with the classic banded pattern. Each dimension is a sine/cosine of a different wavelength: low-index dimensions oscillate fast with position, high-index ones change slowly, so every position gets a unique multi-frequency signature (right panel). This matters because the Self-Attention mechanism at the heart of transformers is permutation-invariant — it computes the same set of attention weights regardless of token order, so on its own it cannot tell “dog bites man” from “man bites dog”. Adding PE to the token embeddings injects absolute (and, via trigonometric identities, relative) position information back into an otherwise order-blind model. Because the encoding is a fixed function rather than learned parameters, it also generalises to sequence lengths never seen during training — unlike the order handled implicitly by the recurrence in Hopfield Networks and classic RNNs.
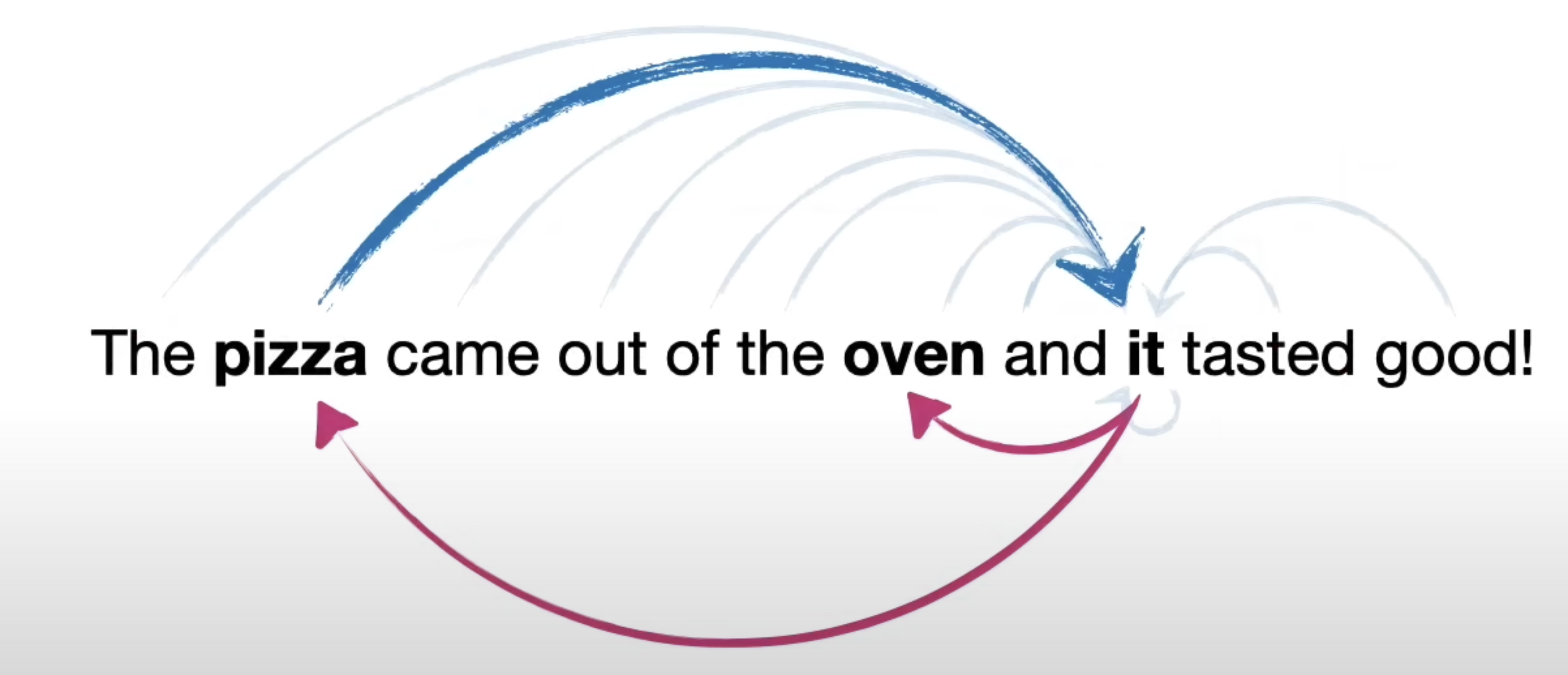
Self Attention
The model calculates the relationships within words and calculates the probability another word is associated with the given word. The more often it receives texts where it refers to pizza, the higher the chance in this text it will be the same.
The highest association to a word is to the word itself.
Encoder-Decoder-Attention
The importance of the single words within a sentence is tracked by the encoder-decoder-attention. It makes sure the most important words are translated first.
Residual Connections
Residual connections ensure the algorithm learns efficiently and focuses on solving just one part of the problem.
Where Transformers are used today
Transformers (Vaswani et al., 2017) are now the dominant architecture in essentially all of AI — far beyond the NLP they were invented for.
Large language models — GPT-4, Claude, Gemini, LLaMA, DeepSeek, Mistral. Decoder-only architectures.
Linear-time complexity in sequence length (vs. quadratic for attention) → cheaper for very long contexts
MoE (Mixture of Experts) architectures — Mixtral, DeepSeek-V3
Same parameter count, sparse activation → faster inference per token
Linear attention variants (Performer, Linformer, RWKV)
Approximate attention in O(N) instead of O(N²)
Hyena / FlashFFTConv
Convolution-based long-range modeling — competitive on some benchmarks
Diffusion language models
Parallel token generation instead of autoregressive — research stage
JEPA architectures (LeCun’s vision)
Predicting embeddings rather than tokens — early stage
Status quo (early 2026): transformers still dominate, but hybrids (SSM + attention, MoE + transformer) are eating into pure-transformer dominance for specific use cases. Pure attention is no longer obviously the best architecture for long-context — Mamba-style SSMs are catching up fast.