Methods of AI — Course MOC
Course: Methods of AI · Cognitive Science Bachelor · Uni Osnabrück
Active: SoSe 2026 (re-take) · also taken WiSe 2024/25
Topics: Local Search · CSP · Planning I+II · Knowledge Representation · Vagueness & Uncertainty · ML I-III · Neural Networks · Deep Learning
⭐ ORAL EXAM — 1 Jun 2026 · Focus: (Local) Search · CSP · Machine Learning
Main drill: Quiz Exam Schwerpunkte — 15 hard why/compare/apply questions on the three reported focus topics (English, fact-checked 27/05/26 against the slides, with 📋 slide-scope notes).
Paper dossier: pruefung_paper-transformers-search_25-05-26 — “Transformers Struggle to Learn to Search”.
📑 Table of Contents
🗺️ Start here for “where do I find X?”: Methods of AI MOC — every topic → the file with the deep content, plus an algorithm locator (where is AC-3, A*, Bellman, …).
Navigation & topic links
- Quick Navigation — cheat sheet, Q&A hub, decision tree
- Topics index — per topic: 📋 Lernzettel · ✏️ Quiz · 🧠 atomic notes
Max’s lecture notes (Max’s lecture notes)
Archives
- Archive — NotebookLM Q&A dumps — general questions · Calculating questions · more questions
- Archive — VIPS exercise chats — VIPS 1 — Local Search · VIPS 2 — CSP · VIPS 3 — Vagueness
- Archive — Vagueness deep-dive (claim analysis) — Vagueness and Uncertainty · Analysis of the Claims about Vagueness · Summary Table · VL10 — SVM notes
Bottom of file
Quick Navigation
| What | Where |
|---|---|
| ⭐ Oral-exam focus drill | Quiz Exam Schwerpunkte — Local Search · CSP · ML, 15 hard Qs (fact-checked 27/05/26) |
| ⭐ Algorithm decision tree | Algorithm Decision Tree — MoAI — “which algorithm for which problem?” (the meta-skill the exam tests) |
| ⭐ Exam cheat sheet | Methods of AI — Exam Cheat Sheet — A4-printable, all formulas + traps |
| Exam Q&A hub | Questions for Methods of AI — 104 basic + 20 complex + 6 MC sets + 35 deep / exam-trap (2026) |
| Lernzettel | 9 files — 1-2 pages per topic, formulas, traps. See below ↓ |
| Quizzes | 8 files — recall-style. See below ↓ |
| Atomic notes | 30+ — see Topics index below ↓ |
| Max’s lecture notes | Personal observations from VL4-VL10. See ↓ |
| Course material PDFs | ~/Documents/Uni/Cognitive Science [Course]/Courses/SoSe 2026/Methods of AI/ |
Things I still need to drill: (add as you go)
- …
Paper, welches ich reviewen soll:
Topics index
Each topic links: 📋 Lernzettel · ✏️ Quiz · 🧠 Atomic notes.
1. Local Search
- 📋 lernzettel_local-search_30-04-26
- ✏️ quiz_local-search_30-04-26 · quiz_local-search_2026-04-30
- 🧠 Search Algorithms · Loss Surface (the landscape these algorithms traverse) · Hill Climbing · Gradient Descent (modern successor) · Local Beam Search · Simulated Annealing · Temperature in neighbour selection · Genetic Algorithms · Paper Review Genetic Algorithms · Stochastic Diffusion Search · cul-de-sac obstacles
2. Constraint Satisfaction (CSP)
3. Planning I — Classical (STRIPS, Situation Calculus)
- 📋 lernzettel_planning-i_30-04-26
- ✏️ quiz_planning_30-04-26 (covers both Planning I + II)
- 🧠 Why an an AI struggles with Planning · Frame Problem · Situation Calculus · STRIPS · PDDL and STRIPS
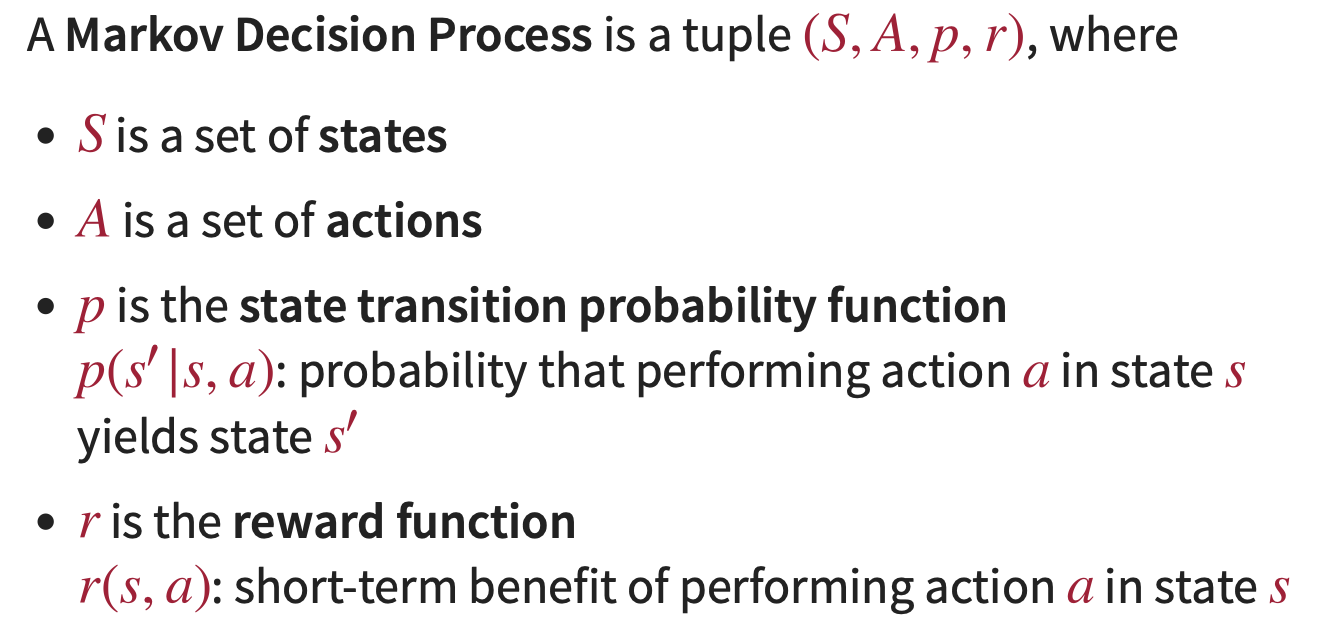
4. Planning II — Probabilistic (MDP)
- 📋 lernzettel_planning-ii_30-04-26
- ✏️ quiz_planning_30-04-26
- 🧠 Markov Decision Process (MDP) · Bellman Equation · Q-Function · Reinforcement Learning (RL) · Temporal Difference Reinforcement Learning · You Only Live Once, Single Life Reinforcement Learning
5. Knowledge Representation (I + II)
- 📋 lernzettel_knowledge-representation_30-04-26
- ✏️ quiz_knowledge-representation_30-04-26
- 🧠 Description Logics · Allen’s Tense Logic · RCC-8
6. Vagueness & Uncertainty
- 📋 lernzettel_vagueness-uncertainty_30-04-26
- ✏️ quiz_vagueness-uncertainty_30-04-26
- 🧠 Fuzzy Logic · Dempster-Shafer Theory
7. Machine Learning I & II
- 📋 lernzettel_ml-i-ii_30-04-26
- ✏️ quiz_ml_30-04-26
- 🧠 Machine Learning · Bias-Variance Tradeoff · Decision Trees and ID3 · Random Forest · Supervised Learning · Unsupervised Learning · Machine Learning for Cognitive Computational Neuroscience · Complementary Learning Systems
- ↗ Important terms (TP/TN, accuracy, recall): Important terms
8. Machine Learning III — SVMs & Perceptron
- 📋 lernzettel_svm_30-04-26
- ✏️ quiz_svm_30-04-26
- 🧠 Perceptron · Support Vector Machines · Kernel Trick
9. Neural Networks & Deep Learning (incl. Transformers)
- 📋 lernzettel_neural-networks-deep-learning_30-04-26
- ✏️ quiz_neural-networks_30-04-26
- 🧠 Hopfield Networks · Gradient Backpropagation · Gradient Descent · Loss Surface (what backprop computes the gradient of) · Deep Neural Networks · Deep Neural Networks in Computational Neuroscience · Implementing Artificial Neural Networks with TensorFlow · The neuroconnectionist research programme
- 🧠 Transformers / Attention: Transformers · Self-Attention · Attention is All You Need · Attention Systems · YT - Attention in Transformers vs. menschliche Aufmerksamkeit
Max’s lecture notes
VL4
What are the differences between the frame and the ramification problem?
The ramification problem and the frame problem are distinct yet related challenges in artificial intelligence (AI), particularly within planning and action reasoning. The frame problem deals with the difficulty of representing which facts about the world remain unchanged after an action, focusing on efficiency in representing unchanged facts without explicit enumeration. Conversely, the ramification problem addresses the indirect effects or consequences of actions, emphasizing the need to account for and reason about broader consequences that are more difficult to predict. While the frame problem is concerned with inertia and what stays the same, the ramification problem focuses on change, specifically the indirect changes caused by actions. Both are crucial for developing AI systems capable of accurate world modeling, planning, and executing actions in complex environments, highlighting the complexity of modeling the world for AI from different perspectives of change and inertia.
Planning
Frame-Problem:
What stays the same after an actions as been performed?
Qualification-Problem:
assessing all the preconditions that could prevent the action from executing (could be endless in this complex world?)
Ramification-Problem:
When moving an object, it also moves other objects
VL5
What is the Markov Decision Process?
- What does it do?
- probability of state changes
- short-term rewards of actions
- What is it about?
- future, present and past are independent
- Outcomes depend only on the current state
- does not take into account past and future states
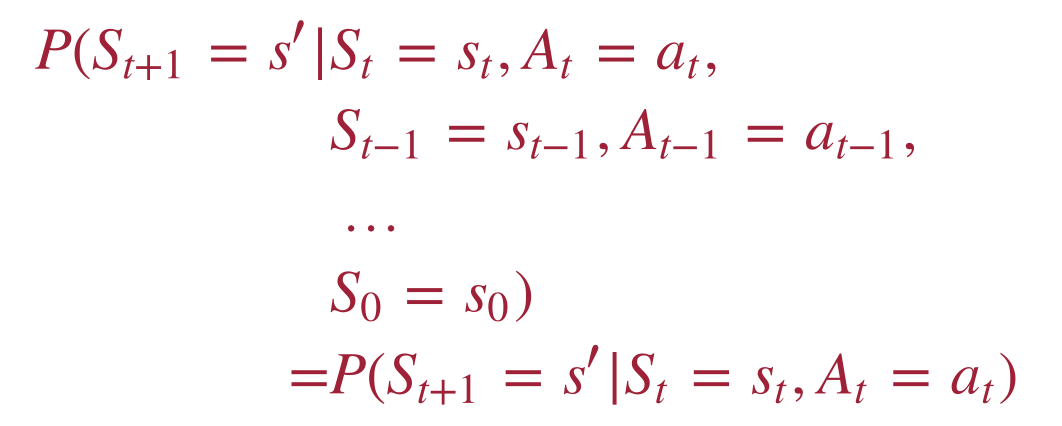
- What is the formal definition of the MDP?
- What problems does MDP tackle?
- uncertainty
- long-term-consequences
- How does it work?
- policy determines in which state we choose what action
- evaluate expected reward based on
- uncertainty
- future rewards
- Example Grid World
VL6/7 Knowledge Representation
Give examples to each of the Allen’s Tense Logic terms
Before:
Meets:
During:
Overlap:
Starts:
Finishes:
Equals:
Markov Decision Process
Aufgabe Tutorial Knowledge Representation 2:
![]()
- p((3,3) | (3,2), right) = 0.1
- p((4,2) | (2,3), left) = 0
- p((3,1) | (4,1), left) = 0.8
- p((4,1) | (4,1), right) = 0.8 + 0.1
What are subsumption and satisfiability tests in DL (Description Logics)?
Subsumption:
In Description Logics (DLs), a subsumption test determines whether one concept is a subtype of another.
For example, if we have two concepts:
- Person
- Student
A subsumption test would determine if “Student” is subsumed by “Person,” which is true because every student is also a person.
Satisfiability:
A satisfiability test determines whether a given concept is consistent, i.e., if there exists at least one individual that satisfies the concept’s description.
For example, the concept “Flying Horse” might be satisfiable in a fantasy world where such creatures exist, but it would be unsatisfiable in the real world.
These tests are fundamental to reasoning with knowledge bases in DLs and are used in various applications, such as ontology engineering, information integration, and natural language processing.
Links
https://stripsfiddle.meteorapp.com
good videos:
https://www.youtube.com/watch?v=YPJ6yMMNx-s
https://www.youtube.com/watch?v=qLIYJ2NiGq0
VL8 Vagueness and Uncertainty
How do description logics (DLs) differ from classical first-order logic?
Description Logics (DLs) and First-Order Logic (FOL) are both formal languages used for knowledge representation, but they differ in their goals and expressive power. Here are the main differences based on the sources:
-
Purpose:
- First-Order Logic is designed to describe properties of objects and make statements about them. It is a general language capable of modeling a wide range of statements and relationships.
- Description Logics are specifically designed to describe properties of categories or classes, facilitating the representation of terminological knowledge. DLs are therefore particularly suited for working with ontologies.
-
Expressive Power:
- FOL is very expressive and can represent complex relationships and quantifications. However, this often makes it difficult to manage for certain tasks, especially for the representation of classes and hierarchies.
- DLs are less expressive than FOL, which makes them simpler and more efficient for certain tasks. DLs focus on the description of concepts, roles, and individuals and their relationships. They are particularly adept at modeling hierarchies and relationships between concepts, which is crucial for ontologies.
-
Semantics:
- Both FOL and DLs are equipped with a logic-based semantics. This means that the meaning of expressions is defined formally and precisely.
- Unlike other knowledge representation formalisms, such as semantic networks, DLs have a formal semantics that enables automatic reasoning over the represented information.
-
T-Box and A-Box:
- DLs often use the distinction between a T-Box (terminology box) and an A-Box (assertions box).
- The T-Box contains terminological knowledge, i.e., the definitions and relationships of concepts and classes. This corresponds to the schema of a database.
- The A-Box contains individual knowledge, i.e., statements about specific individuals and their relationships. This corresponds to the data of a database.
- FOL does not make this explicit distinction.
-
Applications:
- FOL is a very general language suitable for a wide range of applications.
- DLs are particularly suitable for the representation and reasoning over ontologies. They are frequently used in applications involving the description of hierarchies and relationships between classes, such as in medicine, biology, and the semantic web.
-
Inference Mechanisms:
- Both FOL and DLs have inference mechanisms that allow new knowledge to be derived from given statements.
- For DLs, there are special algorithms like tableau algorithms tailored to the specific features of DLs.
- In FOL, theorem proving is often used.
In summary, DLs are a specialized form of knowledge representation that differs from the more general first-order logic by focusing on terminological knowledge, concepts, and classes. The restriction in expressive power makes them more manageable and efficient for working with ontologies, while FOL offers a more general and expressive language for a broader range of tasks.
What are the primary roles of concept names, role names, and individual names in description logics?
In Description Logics (DLs), concept names, role names, and individual names play distinct but crucial roles in knowledge representation.
-
Concept Names represent sets of individuals, also known as their extensions. They are used to describe classes or categories of objects.
- Examples of concept names include
Parent,Sister,Student. - Concept names can be combined using concept constructors to form more complex concepts, allowing for more detailed descriptions of categories.
- Examples of concept names include
-
Role Names are interpreted as binary relations between objects. They describe relationships or attributes of concepts.
- Examples of role names include
employedBy,motherOf,teaches. - Role names are often used in conjunction with concept names to define how concepts are related to each other.
- Examples of role names include
-
Individual Names refer to specific objects or individuals in the described world. They are the concrete elements that belong to the categories described by concept names and are related to each other through role names.
- Examples of individual names include
Mary,Alice,John. - Individual names are used to make statements about specific instances of concepts and their relationships to other individuals.
- Examples of individual names include
In summary, concept names serve to define categories, role names describe relationships between these categories, and individual names identify specific elements of these categories. These three elements form the vocabulary for constructing knowledge bases in Description Logics.
What does the syntax of the basic description language ALC include?
Explain the difference between the Terminological Box (TBox) and Assertion Box (ABox) in a DL knowledge base.
How is general concept inclusion (GCI) defined in description logics?
What is meant by concept equivalence in description logics?
How can fuzzy logic address the concept of vagueness in comparison to classical logics?
What is the Heap Paradox, and how does it illustrate vagueness?
Describe how fuzzy set theory incorporates a modified membership relation.
What is a membership function in the context of fuzzy sets, and how does it differ from a characteristic function?
Define t-norms and s-norms in fuzzy logic. What role do they play in conjunction and disjunction?
A t-norm and an s-norm are generalizations of the logical operations conjunction (AND) and disjunction (OR) in fuzzy logic. They are used to define the semantics for fuzzy logic operators.
T-Norms:
- A t-norm is a binary operation that generalizes the conjunction (AND operation) in fuzzy logic.
- A t-norm, usually written as
t(x, y), assigns a new degree of membership to each pair of membership degreesxandy, representing the degree of conjunction of these grades. - T-norms must satisfy the following conditions:
- Neutral Element: There is a neutral element 1, such that
t(x, 1) = xfor all x in the interval. - Commutativity:
t(x, y) = t(y, x)for all x, y. - Associativity:
t(t(x, y), z) = t(x, t(y, z))for all x, y, z. - Monotonicity: If
x ≤ x'andy ≤ y', thent(x, y) ≤ t(x', y').
- Neutral Element: There is a neutral element 1, such that
- Examples of t-norms include minimum
min(x, y), algebraic productx * y, orquot(x,y) = (x*y) / (x + y - xy).
S-Norms:
- An s-norm is a binary operation that generalizes the disjunction (OR operation) in fuzzy logic.
- An s-norm, usually written as
s(x, y), assigns a new degree of membership to each pair of membership degreesxandy, representing the degree of disjunction of these grades. - S-norms must satisfy the following conditions:
- Neutral Element: There is a neutral element 0, such that
s(x, 0) = xfor all x in the interval. - Commutativity:
s(x, y) = s(y, x)for all x, y. - Associativity:
s(s(x, y), z) = s(x, s(y, z))for all x, y, z. - Monotonicity: If
x ≤ x'andy ≤ y', thens(x, y) ≤ s(x', y').
- Neutral Element: There is a neutral element 0, such that
- Examples of s-norms include the maximum
max(x, y), algebraic sumx + y - (x * y), orquos(x,y) = (x + y – 2xy) / (1.0 – xy).
In summary:
- T-norms are generalizations of logical conjunction (AND) and indicate the minimal degree of membership.
- S-norms are generalizations of logical disjunction (OR) and indicate the maximal degree of membership.
- T-norms use a neutral element of 1, while s-norms use a neutral element of 0.
If you have any further questions or need more assistance, feel free to ask!
What are the main characteristics of probability measures according to Kolmogorov’s axioms?
How are events defined in a probability space, and what is the relationship between events and possible worlds?
Explain the concept of conditional probabilities and their significance in probabilistic logic.
How can probabilistic knowledge bases be used to reason about uncertain information?
In what ways do fuzzy logic and probabilistic logic differ in handling truth values and membership?
What are some properties that remain true within fuzzy set operations compared to classical set operations?
How is probabilistic reasoning more complex than reasoning in fuzzy logic?
Referencing the course materials, what is recommended for further reading on AI methods involving vagueness and uncertainty?
Feel free to use these revised questions for your study!
Archive — NotebookLM Q&A dumps
Raw Q&A material generated via NotebookLM (covers all topics).
The organized version with proper exam-trap markings + cross-links is in Questions for Methods of AI (104 basic + 20 complex + 6 MC sets + 35 deep 2026 questions).
Kept below for full-text search and as a reference snapshot.
general questions
Search Algorithms and Problem Solving
-
What is the difference between classical and local search?
Classical search is not interested in the internal representation of states, while local search is not interested in the sequence of actions.- Local search is better suited when only the solution matters and not the solution path, such as in optimization and constraint-satisfaction problems.
-
Name some local search algorithms.
- Local search algorithms include hill climbing, simulated annealing, local beam search, and genetic algorithms.
What is Local beam search?
- multiple climbers
- or complex spaces
What is the Breadth first search algorithm?
- layer by layer
-
What is the main idea of hill climbing?
- Hill climbing is a discrete version of gradient ascent, where one starts from a random point and follows the direction of ascent.
- avoid local minima: it doesn’t escape them
- stochastic hill climbing
- random restart
-
How do genetic algorithms relate to local search?
- Genetic algorithms extend the analogy of natural selection, where neighbors (offspring) of states (organisms) populate the next generation. Survival probability depends on the value (fitness).
Constraint Satisfaction Problems (CSP)
-
What are constraint satisfaction problems (CSP)?
- A CSP consists of variables, each with an associated domain, and a set of constraints that limit the possible values for the variables.
-
Provide examples of CSPs.
- Examples of CSPs include frequency assignment for radio stations and scheduling.
-
How are constraints represented?
- Constraints can be represented explicitly (by storing all n-tuples) or implicitly (by implementing a function that takes n-tuples as arguments and returns true or false).
-
What is the naive method for solving CSPs?
- The naive method involves enumerating all possible variable assignments and checking each for consistency.
-
What is backtracking search?
- a method used by other search algorithms
- Backtracking search assigns values to variables one by one and changes the last variable assignment upon constraint violations.
-
Node Consistency:
- How can one achieve node consistency in a CSP?
- Is a CSP with non-empty domains that is node-consistent also globally consistent?
- How does node consistency affect the size of the domains and how can it be used for preprocessing?
- Can node consistency be used to determine if a CSP is inconsistent?
-
Arc Consistency:
- How do you check if a node in a CSP is arc-consistent with another node?
- Is arc consistency a commutative property?
- What does it mean when a CSP is arc-consistent?
- How does the AC-1 algorithm work to establish arc consistency?
- Why is arc consistency not sufficient to guarantee the global consistency of a CSP?
- Can arc consistency be used to discover inconsistency?
-
Path Consistency and k-Consistency:
- What does path consistency mean and how does it differ from arc consistency?
- What is k-consistency and strong k-consistency?
- What is the relationship between path consistency and 3-consistency?
- Why is path consistency not sufficient to guarantee the global consistency of a CSP?
-
General Consistency Questions:
- What is the difference between local and global consistency in relation to CSPs?
- How can consistency concepts (node, arc, path consistency) be used to simplify CSPs?
- What are the advantages and disadvantages of preprocessing CSPs with consistency techniques compared to solving them directly?
- Is there a hierarchy among node, arc, and path consistency?
-
CSPs:
- How can a CSP be formally defined?
- What are variables, domains, and constraints in a CSP?
- What is the difference between a consistent and an inconsistent CSP?
- What is a solution to a CSP?
- How can a CSP be formulated as a search problem?
- How can n-ary constraints be converted into binary constraints?
- What types of constraints exist?
-
Local Search and CSPs:
- How can a local search problem be formulated for a general CSP?
- What are the state space, neighborhood, and objective function in local search for CSPs?
- What does it mean when local search finds a globally optimal or locally optimal solution?
- How does local search compare to backtracking search in finding solutions to CSPs?
Planning
-
What is the difference between classical and probabilistic planning?
- Classical planning seeks a sequence of actions to transform a given state into a goal state, where actions “guarantee” reaching specific states.
- Probabilistic planning deals with uncertainty and long-term consequences.
-
What are the main issues in planning?
- The main issues are the frame problem, the qualification problem, and the ramification problem.
-
What is the role of PDDL in planning?
- PDDL (Planning Domain Definition Language) extends STRIPS and is a declarative language for knowledge representation.
Knowledge Representation
-
What is knowledge representation?
- Knowledge representation (KR) is a field of AI dedicated to the formal and structured representation of information to enable automatic reasoning.
-
What is an ontology?
- An ontology is an explicit specification of a conceptualization. It consists formally of a set of concepts, a partial ordering relation on the concepts, a set of relations, and a function assigning an arity to each relation.
-
What is the difference between domain-specific and general ontologies?
- Domain-specific ontologies pertain to a specific part of the world, while general ontologies should be applicable in any domain.
-
List some methods for creating ontologies.
- Ontologies can be created by trained ontologists, through import from databases, open information extraction from text documents, or by amateurs.
-
What is the Region Connection Calculus (RCC)?
- The RCC is a calculus based on the concept of a region and models relationships between regions, such as “in”, “out”, and “adjacent”.
-
What are the 7 basic logical relationships of time intervals according to Allen?
- The 7 basic logical relationships are STARTS/IS-STARTED-BY, FINISHES/IS-FINISHED-BY, DURING/CONTAINS, BEFORE/AFTER, and OVERLAP/IS-OVERLAPPED-BY.
-
What are Description Logics (DLs)?
- Description Logics are a family of KR languages developed to describe properties of categories/classes.
-
What is the difference between T-Box and A-Box in DL?
- The T-Box (terminology box) contains the logical representation of conceptual knowledge, while the A-Box (assertions box) contains the logical representation of facts about individuals.
Vagueness and Uncertainty
-
What is the difference between fuzzy logic and probabilistic logic?
- Fuzzy logic deals with partial truth (vagueness), while probabilistic logic addresses uncertainty.
-
What is a fuzzy set?
- A fuzzy set is defined by a set and a membership function that indicates the degree to which an element belongs to a set.
-
What are the Kolmogorov axioms of probability?
- The Kolmogorov axioms are: non-negativity, normalization, and finite additivity.
-
What is the difference between the “complement” operation in probabilistic logic and fuzzy logic?
- In probabilistic logic, the probability of the complement of an event is defined as P(Ω ∖ A) = 1 − P(A), while the “complement” operation in fuzzy logic is defined as μAc(x) = 1 − μA(x).
-
How are disjunction and conjunction defined in probabilistic logic and fuzzy logic?
- In probabilistic logic, the conjunction is defined as P(A ∩ B) = P(A) ⋅ P(B) if A and B are independent, and the disjunction is defined as P(A ∪ B) = P(A) + P(B) − P(A ∩ B). In fuzzy logic, these are represented by t-norms (conjunction) and s-norms (disjunction), e.g., (x, y) = x ⋅ y (for a t-norm) and (x, y) = x + y − (x ⋅ y) (for an s-norm).
Machine Learning
-
Why is machine learning important?
- Machine learning is important due to the growing flood of data, increased computing power, and challenges in explicit knowledge representation.
-
What types of learning experiences exist?
- There are direct or indirect learning experiences, with or without a teacher, and the training experience must be representative of the performance goal.
-
What is overfitting?
- Overfitting means a model has become too specialized to the training data and can no longer generalize to independent test data.
-
How can overfitting be avoided?
- Overfitting can be avoided by using less complex models, regularization, removing/disabling model parts, restricting parameter values, adding noise, or more training data.
-
What are precision and coverage?
- Precision measures the degree of correctness of a model, while coverage measures the degree of completeness.
-
What is the difference between supervised and unsupervised learning?
- In supervised learning, examples are provided with a target output, whereas in unsupervised learning, the model must find patterns without explicit outputs.
-
What are feature spaces?
- Feature spaces are vector spaces into which data is embedded to exploit the topology of the space. The dimensions can have an interpretation and are called features.
-
What are decision trees?
- Decision trees implicitly define logical statements (conjunctions of implications).
-
What is the advantage of random forests over individual decision trees?
- Random forests avoid overfitting and are more robust to irrelevant features.
-
What are support vector machines (SVM)?
- SVMs (Support Vector Machines) map an input space into a higher-dimensional space to enable separation with linear functions.
-
What is a kernel in SVMs?
- A kernel is a similarity function that allows the decision boundary to be computed without computing the entire function but only over the support vectors.
-
How does the training process work in a perceptron?
- The perceptron is iteratively trained with a labeled dataset, with the learning rule derived from minimizing the mean squared error. → Perceptron
-
What is the issue with a perceptron when tackling an XOR problem?
- A perceptron cannot solve the XOR problem without very problem-specific adjustments.
Neural Networks
-
What is a Deep Neural Network?
- A Deep Neural Network has more than two layers.
-
What are Residual Connections in neural networks?
- Residual Connections compute the residuals (changes to previous layers) while directly forwarding the main signal.
-
What is an Autoencoder?
- An Autoencoder consists of an encoder and a decoder, with the goal of minimizing the reconstruction error.
-
What is a Variational Autoencoder (VAE)?
- A VAE extends the training objective of the autoencoder by adding a learning constraint that minimizes the Kullback-Leibler divergence between the code distribution and a prior.
-
What are Transformer architectures?
- Transformer architectures are a specific deep learning architecture with (multi-head) attention mechanisms.
-
What is the concept of “Foundation Models”?
- Foundation Models are pre-trained on large datasets and are regarded as general-purpose technologies.
-
What are Positional Embeddings in the context of Transformer architectures?
- Positional Embeddings allow Transformer models to account for the position of individual elements in an input sequence. They also help parallelize the training of large amounts of data.
-
What is the goal of an “Attention” mechanism in Transformer models?
- Attention mechanisms enable the recognition of long-range dependencies and the implementation of an effective memory system.
What is STRIPS?
STRIPS (Stanford Research Institute Problem Solver) is a state-based planning algorithm used in artificial intelligence to solve problems where the goal is to find a sequence of actions that transforms a given initial state into a desired goal state. STRIPS employs a closed-world assumption and represents states as sets of atoms.
Here are some key aspects of STRIPS:
-
State Representation: States are represented by sets of atoms (ground literals). A closed-world assumption is used, meaning that any atoms not explicitly listed in the state are considered false.
-
Operators: STRIPS operators describe actions and their effects on the world. Each operator consists of:
- Name: An identifying name for the action.
- Variables: Placeholders for objects in the domain.
- PRE (Preconditions): A list of atoms that must be true in the current state for the operator to be applicable.
- ADD (Positive Effects): A list of atoms to be added to the state when the operator is applied.
- DEL (Negative Effects): A list of atoms to be removed from the state when the operator is applied.
-
Operator Application: An operator can be applied to a state if the preconditions are met. Applying an operator results in a new state by removing atoms in the DEL list and adding atoms in the ADD list.
-
Planning as Search: Planning with STRIPS is viewed as classical search in the state space. The search space consists of states, and transitions between states are generated by the application of operators.
-
Frame Problem: STRIPS “solves” the frame problem by assuming that everything not explicitly changed by the ADD or DEL lists remains unchanged. This eliminates the need to define additional frame axioms.
STRIPS is a significant precursor to modern planning approaches and has influenced the development of the Planning Domain Definition Language (PDDL). PDDL extends STRIPS with numeric fluents, derived predicates, and other features. However, STRIPS is limited to deterministic and static environments.
In summary, STRIPS is a fundamental state-based planning algorithm that uses states and operators with preconditions and effects to find plans that transform a given initial state into a goal state. The algorithm makes the closed-world assumption and addresses the frame problem by assuming that anything not explicitly changed remains unchanged.
Calculating questions
Certainly, here are some exercises based on the calculations discussed in the lectures to deepen your understanding:
Exercise 1: Local Search and the N-Queens Problem
Consider the N-Queens problem, where the objective is to place N queens on a chessboard such that no queen can attack another.
- Initial Situation: Assume you have a 4x4 chessboard and the queens are placed in a random configuration.
- Tasks:
- Calculate the number of pairs of queens that can directly or indirectly attack each other for a given random configuration.
- Suppose you are using a hill-climbing algorithm. What would be a neighbor state, and how would you choose it?
- Evaluate whether a found local optimal state is also a solution to the problem.
- Explain the role of an objective function in this context.
Exercise 2: Simulated Annealing
Assume you are applying simulated annealing to solve an optimization problem.
- Initial Situation: You have a current state with a value and you randomly select a neighbor state. The value of the neighbor state is
ΔE = -3less than the current state. - Tasks:
- Calculate the probability of accepting the neighbor state when the temperature
T=1. - Calculate the probability when the temperature is reduced to
T=0.1. - How does the temperature influence the acceptance of worse neighbor states?
- Compare the behavior of simulated annealing at high and low temperatures in terms of exploration and intensification.
- Calculate the probability of accepting the neighbor state when the temperature
Exercise 3: Constraint-Satisfaction Problems (CSPs)
Consider a frequency assignment problem with the following variables and domains:
-
Variables: A, B, C, D
-
Domains: D(A) = {f1, f2}, D(B) = {f1, f3}, D(C) = {f2, f3}, D(D) = {f1, f2, f3}
-
Constraint: A ≠ B, B ≠ C, C ≠ D.
-
Tasks:
- Is the CSP node-consistent? If not, how can it be made node-consistent?
- Is arc consistency satisfied for the edge (B, A)?
- Describe how a backtracking search would look for a solution.
- Explain how a local search method could be applied, with an appropriate objective function.
Exercise 4: Markov Decision Processes (MDPs)
Consider a grid world example with the following transition probabilities and rewards:
- Transition Probabilities: An action has a probability of 0.8 of going in the intended direction, and 0.1 each of going in one of the two perpendicular directions.
- Rewards: +1 for reaching the goal state, -1 for reaching a negative state, and -0.04 for all other transitions.
- Initial Situation: Starting state is (1, 1) with the action “up”.
- Tasks:
1. Calculate the probability of reaching the state (1, 2).
2. Calculate the probability of remaining in the state (1,1) if the action “left” is executed.
3. Assuming the discount rate γ=0.5, calculate the first 3 terms of the γ-discounted reward series for any policy.
4. Describe the differences between policy iteration and value iteration.
Exercise 5: Probabilistic Logic
You have the following information:
-
The probability of it being dry is 0.78 (P(dry) = 0.78).
-
The probability of it not being sunny is 0.5 (P(non-sunny) = 0.5).
-
The probability of it being dry or not sunny is not P(dry) + P(non-sunny).
-
The probability of it being humid is 0.22 (P(humid) = 0.22).
-
The probability of it being dry or humid is the sum of the probabilities of it being dry or humid.
-
Tasks:
- Calculate P(dry or humid).
- Why is P(dry or non-sunny) not equal to P(dry) + P(non-sunny)?
- Calculate P(not-dry).
- If P(A) = 0.6 and P(B|A) = 0.5, calculate P(A ∧ B).
These exercises are intended to help you better understand the concepts discussed in the lectures. Try to solve these tasks independently. If you have any questions, feel free to ask.
Answers
Certainly! Here are the answers to the exercises we discussed earlier:
Answers to Exercise 1: Local Search and the N-Queens Problem
- 1. Calculating Attacks: The number of pairs of queens that attack each other heavily depends on the specific random configuration. To calculate this, consider each queen individually and count the number of other queens located in the same row, column, or diagonal.
- 2. Neighbor State and Hill-Climbing: In the N-Queens problem, a neighbor state can be created by moving a single queen within its column to another square. In the hill-climbing algorithm, a neighbor state is selected by choosing the one that minimizes the number of attacks.
- 3. Local Optimum vs. Solution: A local optimum is not necessarily a solution to the problem. It’s possible to find a state where no neighboring move reduces the number of attacks, but attacks still exist. A solution to the N-Queens problem is a state where no queens attack each other.
- 4. Role of the Objective Function: The objective function (also known as the evaluation function) in the N-Queens problem is the number of pairs of queens attacking each other. The goal is to minimize this number, or equivalently, maximize the negative of this function. The objective function guides the search algorithm by indicating how good a state is compared to others.
Answers to Exercise 2: Simulated Annealing
- 1. Probability at T=1: The acceptance probability of a worse neighbor state in simulated annealing is calculated using the formula exp(ΔE / T). Here, ΔE = -3 and T = 1, so the probability is exp(-3 / 1) ≈ 0.0498 or about 4.98%.
- 2. Probability at T=0.1: At T=0.1, the probability is exp(-3 / 0.1) = exp(-30) ≈ 9.35 x 10^-14. The probability is extremely low, meaning worse neighbor states are practically not accepted at low temperatures.
- 3. Influence of Temperature: The temperature (T) in simulated annealing controls the probability of accepting worse neighbor states. High temperatures allow the algorithm to accept states with worse values, thereby enabling more exploratory search. Low temperatures result in almost exclusively accepting improving or equal-value states, which focuses the search on intensification in local areas.
- 4. Comparison of Exploration vs. Intensification:
- High Temperature: Leads to broader exploration of the search space because worse states are accepted with higher probability. This helps escape local optima.
- Low Temperature: Leads to stronger intensification of the search around the current state. The algorithm almost exclusively accepts improving or equal-value states, steering it towards a local optimum.
Answers to Exercise 3: Constraint-Satisfaction Problems (CSPs)
- 1. Node Consistency: A CSP is node-consistent if all values in the domain of every variable satisfy unary constraints. In this case, variable A has the domain {f1, f2}, B {f1, f3}, C {f2, f3}, and D {f1, f2, f3}. There are no unary constraints provided, so the CSP is node-consistent.
- 2. Arc Consistency: For the edge (B, A), for every value in B’s domain (f1, f3), there must exist a value in A’s domain that satisfies the constraint B ≠ A.
- For B = f1, A = f2 is allowed.
- For B = f3, A = f1 and A = f2 are allowed.
- The edge (B, A) is arc-consistent.
- 3. Backtracking Search: The backtracking search would iteratively assign values to variables and check the constraints. For example, it might start with A, choosing f1. Then B, selecting a value different from A, like f3. For C, f2, and then a value for D, etc. If a value does not meet any constraint, the search tree backtracks.
- 4. Local Search: A local search for CSPs would begin with a random assignment of values to variables. The objective function would be the number of satisfied constraints. In each step, you would move to a neighbor (another assignment) that improves the number of satisfied constraints until a local optimum is reached.
Answers to Exercise 4: Markov Decision Processes (MDPs)
- 1. Probability of reaching (1, 2): When the action “up” is taken from (1,1), there is a probability of 0.8 of reaching (1,2). There is a 0.1 probability of reaching (2,1) and 0.1 of remaining in (1,1).
- 2. Probability of staying in (1,1): When the action “left” is executed, there is a probability of 0.8 of reaching (0,1). There is a 0.1 probability of staying in (1,1) and 0.1 of reaching (1,2).
- 3. γ-discounted Reward Series: The first three terms of the γ-discounted reward series for γ = 0.5 are:
- r1
- γ * r2 = 0.5 * r2
- γ² * r3 = 0.25 * r3
Here r1, r2, and r3 are the rewards for the first, second, and third steps.
- 4. Differences between Policy Iteration and Value Iteration:
- Policy Iteration: Begins with a random policy and iteratively improves it through repeated policy evaluation and policy improvement. The policy is evaluated and adjusted repeatedly until convergence is achieved.
- Value Iteration: Begins with random value functions for each state and iteratively improves them until the value functions stabilize, i.e., the optimal value function converges. The optimal policy is then derived from the optimized value functions.
Answers to Exercise 5: Probabilistic Logic
- 1. P(dry or humid): Since “dry” and “humid” are mutually exclusive, P(dry or humid) = P(dry) + P(humid) = 0.78 + 0.22 = 1.
- 2. P(dry or non-sunny) ≠ P(dry) + P(non-sunny): The probabilities cannot be added because the events “dry” and “non-sunny” are not disjoint; it can be both dry and non-sunny simultaneously. To calculate P(dry or non-sunny), one must take into account the probability of being dry and non-sunny simultaneously, in this case: P(A ∪ B) = P(A) + P(B) − P(A ∩ B)
- 3. P(not-dry): Since P(dry) = 0.78, P(not-dry) = 1 - P(dry) = 1 - 0.78 = 0.22.
- 4. P(A ∧ B): With P(B|A) = P(A ∧ B) / P(A), it follows that P(A ∧ B) = P(B|A) * P(A) = 0.5 * 0.6 = 0.3.
I hope these detailed answers are helpful to you! If you have any further questions, feel free to ask.
more questions
Quiz (Short Answers)
What are the main components of a search problem and how are they related?
A search problem consists of states, actions, and possibly costs. A solution is a sequence of states starting from the initial state and leading to a goal state through actions. Transitions between states are defined by the transition relation.
Explain the difference between explicit and implicit representation of constraints in constraint-satisfaction problems.
In the explicit representation, all permissible n-tuples that satisfy a constraint are stored, whereas the implicit representation uses a function that returns true or false for given n-tuples. The explicit method stores all pairs that satisfy constraints, while the implicit method checks the validity of propositions.
What are node and arc consistency in constraint-satisfaction problems and how are they achieved?
Node consistency refers to whether the domain of each variable is consistent with its own constraints, achieved by removing inconsistent values. Arc consistency refers to the consistency between two variables, ensuring a matching value exists in the domain of the other variable; inconsistent values are removed here as well.
Describe the fundamental differences between deductive and state-based planning.
Deductive planning uses logical formulas to describe states and operators, viewing planning as theorem proving. State-based planning, by contrast, uses atomic sets that describe states and operators that directly impact these states.
What is the closed-world assumption in STRIPS planning, and how does it affect the representation of states?
The closed-world assumption states that all atoms in a state are considered true, while all others are false. This simplifies state representation in STRIPS to sets of atoms.
What is the main difference in evaluating a policy in Markov decision theory (MDP) with or without a discount factor? Evaluating a policy with a discount factor weights future rewards less to ensure convergence. Without a discount factor, all rewards are weighted equally, which can lead to infinite sums.
Briefly explain what can be captured with predicate logic that is not possible with propositional logic. Propositional logic only treats statements as whole entities. Predicate logic allows for examining the internal structure of statements using predicates, terms, and quantifiers, enabling representation of more complex relationships and quantifications.
Describe the RCC-8 calculus and give three examples of the eight possible relations between two regions. The RCC-8 calculus describes eight possible relations between two regions: Disconnected (DC), Externally Connected (EC), Partially Overlapping (PO), Equal (EQ), Proper Part (PP), Tangential Proper Part (TPP), TPP inverse (TPPI), Non-Tangential Proper Part (NTPP) and NTPP inverse (NTPPI). Three examples are: DC(x,y), EQ(x,y), and TPP(x,y).
What are TBox and ABox in description logics, and what is their purpose? The TBox (Terminological Box) contains definitions and relationships between concepts (schema), whereas the ABox (Assertion Box) contains facts about individuals and their relationships to concepts (data). The TBox models the domain and the ABox models the instances.
How are vague statements handled in fuzzy logic? Briefly describe the basic idea. In fuzzy logic, vague statements are represented by membership functions that assign each element a degree of membership in a set between 0 and 1. Unlike classical logic, where statements are either true or false, they can have a degree of truth in fuzzy logic.
Answer Key for the Quiz
A search problem consists of states, actions, and possibly costs. A solution is a sequence of states starting from the initial state and leading to a goal state through actions. Transitions between states are defined by the transition relation.
In the explicit representation, all permissible n-tuples that satisfy a constraint are stored, whereas the implicit representation uses a function that returns true or false for given n-tuples. The explicit method stores all pairs that satisfy constraints, while the implicit method checks the validity of propositions.
Node consistency refers to whether the domain of each variable is consistent with its own constraints, achieved by removing inconsistent values. Arc consistency refers to the consistency between two variables, ensuring a matching value exists in the domain of the other variable; inconsistent values are removed here as well.
Deductive planning uses logical formulas to describe states and operators, viewing planning as theorem proving. State-based planning, by contrast, uses atomic sets that describe states and operators that directly impact these states.
The closed-world assumption states that all atoms in a state are considered true, while all others are false. This simplifies state representation in STRIPS to sets of atoms.
Evaluating a policy with a discount factor weights future rewards less to ensure convergence. Without a discount factor, all rewards are weighted equally, which can lead to infinite sums.
Propositional logic only treats statements as whole entities. Predicate logic allows for examining the internal structure of statements using predicates, terms, and quantifiers, enabling representation of more complex relationships and quantifications.
The RCC-8 calculus describes eight possible relations between two regions: Disconnected (DC), Externally Connected (EC), Partially Overlapping (PO), Equal (EQ), Proper Part (PP), Tangential Proper Part (TPP), TPP inverse (TPPI), Non-Tangential Proper Part (NTPP), and NTPP inverse (NTPPI). Three examples are: DC(x,y), EQ(x,y), and TPP(x,y).
The TBox (Terminological Box) contains definitions and relationships between concepts (schema), whereas the ABox (Assertion Box) contains facts about individuals and their relationships to concepts (data). The TBox models the domain and the ABox models the instances.
In fuzzy logic, vague statements are represented by membership functions that assign each element a degree of membership in a set between 0 and 1. Unlike classical logic, where statements are either true or false, they can have a degree of truth in fuzzy logic.
Essay Questions
Compare and contrast the methods of deductive and state-based planning. Explain their respective strengths, weaknesses, and suitable application scenarios.
Explain the concept of arc consistency in constraint-satisfaction problems and discuss how algorithms can utilize this property to improve the search for solutions.
Discuss the importance of discount factors in Markov decision processes, and how the choice of a discount factor influences convergence and the resulting behavior of an agent.
Analyze the advantages and disadvantages of using fuzzy logic compared to probabilistic logic for modeling uncertainty and vagueness in real-world problems.
Discuss the importance of kernel functions in support vector machines and how selecting the right kernel affects classification capability.
Glossary of Key Terms
State: A description of a situation or configuration in a problem.
Action: An operation that can change a state.
Cost: A numerical value associated with an action or path.
Search Problem: A problem that can be solved by finding a path from an initial state to a goal state.
Transition Relation: A relationship that describes how actions change states.
Constraint-Satisfaction Problem (CSP): A problem where variables must be assigned values from given domains while fulfilling certain constraints.
Node Consistency: The consistency of a variable with its own constraints.
Arc Consistency: The consistency between the domains of two variables.
Deductive Planning: A planning method based on logical deduction.
State-Based Planning: A planning method that operates directly on states and their transitions.
STRIPS: A simple planning formalism within state-based planning.
Closed World Assumption: The assumption that all information not explicitly given is false.
Markov Decision Processes (MDP): A mathematical modeling framework for decision-making in stochastic environments.
Policy: An assignment of actions to states in an MDP.
Discount Factor: A factor in MDPs that weights future rewards less.
Propositional Logic: A logical system centering on entire statements.
Predicate Logic: A logical system that examines the internal structure of statements using predicates and quantifiers.
RCC-8 Calculus: A system for describing topological relationships between regions in space.
TBox: The terminological part of a knowledge base in description logic, defining concepts and their relations.
ABox: The assertional part of a knowledge base in description logic, containing facts about individuals and concepts.
Fuzzy Logic: A form of logic that quantifies degrees of truth between 0 and 1 instead of just true or false.
Membership Function: A function indicating the degree of membership of an element in a fuzzy set.
t-Norm: Generalization of conjunction in fuzzy logic.
s-Norm: Generalization of disjunction in fuzzy logic.
Probabilistic Logic: An extension of classical logic expressing uncertainties through probabilities.
Probability Space: The mathematical foundation for probability theory, consisting of a sample space and a probability distribution.
F1-Score: A measure of a classifier’s accuracy, combining precision and recall.
Precision: The proportion of correctly classified positive instances among all instances classified as positive.
Recall: The proportion of correctly classified positive instances among all actual positive instances.
Feature Space: A space where data points are represented by their features.
TF-IDF: A method of weighting terms in documents based on their frequency and relevance.
K-Means Clustering: An unsupervised learning method for partitioning data points into k clusters.
Hierarchical Clustering: A clustering method that builds a hierarchy of clusters from a dataset.
Entropy: A measure of the disorder or uncertainty of a dataset.
Information Gain: The measure of reduction in uncertainty after partitioning a dataset.
Support Vector Machine (SVM): A supervised learning model used for classification or regression of data.
Hyperplane: An n-1 dimensional subspace in an n-dimensional space for separating data.
Kernel Trick: A method that enables solving a pattern recognition problem with non-linearly separable data by projecting it into a higher-dimensional space.
Perceptron: A simple neural network model.
Multilayer Perceptron (MLP): A neural network with multiple layers.
Gradient Descent: A method for optimizing parameters using the gradient of the objective function.
Backpropagation: A method for computing the gradient for training a neural network’s parameters.
Learning Rate: A parameter in training neural networks that determines the step size during parameter optimization.
Archive — VIPS exercise chats
Raw ChatGPT transcripts walking through specific VIPS exercise problems (worked solutions).
Topics: VIPS 1 = Local Search · VIPS 2 = CSP · VIPS 3 = Vagueness.
Useful for: re-deriving the step-by-step reasoning behind specific exam-style questions. Not exam-summary material — for that, see the Lernzettel.
VIPS 1 — Local Search
Which of the following statements are true about Hill Climbing?
- Hill Climbing makes locally optimal choices in each step (optimal in neighborhood).
- Hill Climbing is guaranteed to find a global maximum.
- In each iteration, Hill Climbing has to look at the complete neighborhood of the current state.
- In each iteration, First Choice Hill Climbing has to look at the complete neighborhood of the current state.
ChatGPT said:
ChatGPT
Here’s an analysis of each statement about Hill Climbing:
-
Hill Climbing makes locally optimal choices in each step (optimal in neighborhood).
- True. Hill Climbing evaluates the neighbors of the current state and moves to a neighbor that has a higher value. This is a locally optimal choice within the neighborhood.
-
Hill Climbing is guaranteed to find a global maximum.
- False. Hill Climbing is not guaranteed to find a global maximum because it can get stuck in a local maximum. It only makes locally optimal choices, which may not lead to the global maximum.
-
In each iteration, Hill Climbing has to look at the complete neighborhood of the current state.
- True, for standard Hill Climbing, the algorithm typically evaluates all neighboring states to determine the best move in each step.
-
In each iteration, First Choice Hill Climbing has to look at the complete neighborhood of the current state.
- False. In First Choice Hill Climbing, the algorithm examines neighbors in a random order and moves to the first neighbor that improves the current state, without necessarily checking all neighbors.
In summary:
- True: Statements 1 and 3
- False: Statements 2 and 4
4o
You said:
As temperature decreases, simulated annealing becomes less likely to make random search. more likely to make random search.
ChatGPT said:
ChatGPT
As the temperature decreases in simulated annealing, it becomes:
- Less likely to make random search.
At high temperatures, simulated annealing allows more random moves, even those that worsen the current solution, to help escape local optima. As the temperature decreases, the algorithm becomes more selective, gradually accepting fewer moves that decrease the solution quality. This approach helps the algorithm to converge toward a solution, ideally close to the global optimum.
4o
You said:
Which of the following statements are true (assume a maximization problem)? Hill Climbing can make choices that decrease the objective function. Stochastic Hill Climbing can make choices that decrease the objective function. First Choice Hill Climbing can make choices that decrease the objective function. Simulated Annealing can make choices that decrease the objective function.
ChatGPT said:
ChatGPT
Here’s an evaluation of each statement for a maximization problem:
-
Hill Climbing can make choices that decrease the objective function.
- False. In standard Hill Climbing, the algorithm only moves to a neighbor if it has a higher (or at least equal) objective function value than the current state. It does not accept moves that decrease the objective function.
-
Stochastic Hill Climbing can make choices that decrease the objective function.
- False. Stochastic Hill Climbing selects a random neighbor and only moves to it if it improves the objective function. It does not accept a decrease in the objective function.
-
First Choice Hill Climbing can make choices that decrease the objective function.
- False. First Choice Hill Climbing examines neighbors randomly and moves to the first one that improves the objective function. It does not accept choices that decrease the objective function.
-
Simulated Annealing can make choices that decrease the objective function.
- True. Simulated Annealing allows moves that decrease the objective function, especially at higher temperatures. This enables it to escape local optima, although the likelihood of accepting such moves decreases as the temperature lowers.
In summary:
- True: Statement 4
- False: Statements 1, 2, and 3
Consider standard implementations of Parallel Hill-Climbing and Local Beam Search (both attempt to maximize the objective function). Assume that the current states are s1 and s2. s1 has neighbors t1 with f(t1)=6 t2 with f(t2)=5 t3 with f(t3)=4. s2 has neighbors r1 with f(r1)=3 r2 with f(r2)=2 r3 with f(r3)=1. Which of the following statements are true? Parallel Hill-Climbing will select t1 and t2 for the next iteration. Parallel Hill-Climbing will select t1 and r1 for the next iteration. Local Beam Search will select t1 and t2 for the next iteration. Local Beam Search will select t1 and r1 for the next iteration.
ChatGPT said:
ChatGPT
Let’s analyze both Parallel Hill-Climbing and Local Beam Search and see which statements are true:
-
Parallel Hill-Climbing: In Parallel Hill-Climbing, each starting state independently attempts to climb the hill by selecting its best neighboring state to move toward a local maximum. Since we have two states s1s1 and s2s2, each will select the best neighbor from its own set.
- For s1s1: The best neighbor is t1t1 with f(t1)=6f(t1)=6.
- For s2s2: The best neighbor is r1r1 with f(r1)=3f(r1)=3.
So, Parallel Hill-Climbing will select t1t1 and r1r1 for the next iteration.
-
Local Beam Search: In Local Beam Search, all states share information across beams and converge toward the most promising states among all the neighbors. Here, we look at all the neighbors of both s1s1 and s2s2, and we would select the top kk (in this case, 2) neighbors with the highest ff-values.
- Across all neighbors: t1t1 (with f(t1)=6f(t1)=6) and t2t2 (with f(t2)=5f(t2)=5) have the highest values.
So, Local Beam Search will select t1t1 and t2t2 for the next iteration.
Conclusion:
-
True Statements:
- Parallel Hill-Climbing will select t1t1 and r1r1 for the next iteration.
- Local Beam Search will select t1t1 and t2t2 for the next iteration.
-
False Statements:
- Parallel Hill-Climbing will select t1t1 and t2t2 for the next iteration. (False because Parallel Hill-Climbing doesn’t consider neighbors from different states for the same selection process.)
- Local Beam Search will select t1t1 and r1r1 for the next iteration. (False because Local Beam Search selects the globally top neighbors across all states.)
4o
You said:
Why are mutations introduced into genetic algorithms? Mutations make the search space smaller. Mutations speed up the search process. Mutations help to explore the search space. Mutations help to optimize an already near-optimal result.
ChatGPT said:
ChatGPT
In genetic algorithms, mutations are introduced to help maintain genetic diversity within the population and avoid premature convergence. Here’s how each option holds up:
-
“Mutations make the search space smaller.”
- This is incorrect. Mutations do not make the search space smaller; rather, they add variability, allowing the algorithm to explore new areas of the search space.
-
“Mutations speed up the search process.”
- Not necessarily. Mutations do not directly speed up the search process. While they can help avoid getting stuck in local optima, they can also introduce random changes that might slow convergence in the short term.
-
“Mutations help to explore the search space.”
- Correct. Mutations introduce random changes, allowing the algorithm to explore parts of the search space that might not be reached through crossover alone. This exploration can help prevent the algorithm from getting stuck in local optima and encourage broader sampling of possible solutions.
-
“Mutations help to optimize an already near-optimal result.”
- While mutations can sometimes make improvements to a near-optimal result, this is not their primary purpose. They are mainly intended to maintain diversity and exploration, not specifically to fine-tune an almost-optimal solution.
Conclusion
The correct answer is: “Mutations help to explore the search space.”
4o
You said:
In the simulated annealing exercise provided in the lecture (The Local Optima revisited). Consider the first case moving queen 2 to row 1 The total number of attacks is 0.5 -1 -2 2 3 ΔE value is equal to at T=10, the probability is 0.81 at T=1, the probability is 0.13
ChatGPT said:
ChatGPT
To analyze this simulated annealing problem, let’s break down each part:
-
Total Number of Attacks:
Since we don’t have the exact initial board configuration or details about the change in the number of attacks after moving queen 2 to row 1, I’ll outline the reasoning generally:- Simulated annealing aims to reduce the number of attacks, so the calculation would involve comparing the initial attack count with the new count after moving the queen.
- Let’s assume:
- Moving queen 2 to row 1 results in a change in the number of attacks (ΔE).
- This change can be positive or negative based on whether it increases or decreases the number of attacking pairs.
Without specific information, it’s challenging to determine the exact number of attacks from this move.
-
ΔE Value:
The ΔE represents the change in the objective function (number of attacks) after the move. If moving the queen decreases the number of attacks by 1, for instance, then:- ΔE would be −1−1.
- If it increases the attacks by 2, then ΔE=+2ΔE=+2.
-
Probability Calculations at Different Temperatures (T):
The probability of accepting a worse state in simulated annealing is given by the formula:P=e−ΔE/TP=e−ΔE/T
Let’s calculate the probabilities using the provided information:
- At T=10T=10: Probability P=0.81P=0.81.
- At T=1T=1: Probability P=0.13P=0.13.
Given these probabilities, the ΔE value can be calculated as follows.
Calculating ΔE
Using the equation for probability:
-
For T=10T=10:
0.81=e−ΔE/100.81=e−ΔE/10
Solving for ΔE:
ΔE=−10⋅ln(0.81)ΔE=−10⋅ln(0.81)
-
For T=1T=1:
0.13=e−ΔE/10.13=e−ΔE/1
Solving for ΔE:
ΔE=−ln(0.13)ΔE=−ln(0.13)
I can calculate these values for a more precise answer.
The calculated values for ΔEΔE are:
- At T=10T=10: ΔE≈2.11ΔE≈2.11
- At T=1T=1: ΔE≈2.04ΔE≈2.04
This suggests that the change in the number of attacks (ΔE) when moving queen 2 to row 1 is approximately 2.
Summary:
- The total number of attacks change from the move is +2+2.
- ΔE value is approximately 22.
- At T=10T=10, the probability of accepting this move is 0.810.81.
- At T=1T=1, the probability of accepting this move is 0.130.13.
4o
You said:
why is delta e approximately 2?
ChatGPT said:
ChatGPT
In simulated annealing, the ΔEΔE value represents the change in the objective function — in this case, the change in the number of attacking pairs when we move a queen. Here’s the reasoning behind why ΔEΔE is approximately 2:
-
Probability Calculation with ΔEΔE:
The probability of accepting a move with energy change ΔEΔE at temperature TT is given by:P=e−ΔE/TP=e−ΔE/T
-
Given Probabilities at Different Temperatures:
- We’re provided with probabilities for two cases:
- At T=10T=10, the probability is 0.81.
- At T=1T=1, the probability is 0.13.
- We’re provided with probabilities for two cases:
-
Solving for ΔEΔE:
Using the formula, we can isolate ΔEΔE by rearranging it as follows:ΔE=−T⋅ln(P)ΔE=−T⋅ln(P)
Plugging in these values:
- At T=10T=10:ΔE=−10⋅ln(0.81)≈2.11ΔE=−10⋅ln(0.81)≈2.11
- At T=1T=1:ΔE=−1⋅ln(0.13)≈2.04ΔE=−1⋅ln(0.13)≈2.04
Both calculations yield values close to 2, suggesting that ΔEΔE — the change in the number of attacks — is approximately 2. This means that moving queen 2 to row 1 likely increases the number of attacking pairs by 2.
4o
You said:
what exactly does the temaperature diffeerence?
ChatGPT said:
ChatGPT
In simulated annealing, the temperature TT plays a crucial role in determining the probability of accepting moves that may worsen the solution, which helps the algorithm avoid getting stuck in local optima. Here’s how temperature affects the process:
-
High Temperature (e.g., T=10T=10):
- At high temperatures, the probability of accepting a worse move (where ΔE>0ΔE>0) is relatively high.
- This means the algorithm is more willing to accept moves that increase the objective function (i.e., moves that might temporarily worsen the solution), allowing it to explore the search space broadly.
- This broader exploration prevents the algorithm from getting trapped early in local minima, encouraging it to jump out and explore other areas of the search space.
-
Low Temperature (e.g., T=1T=1):
- At low temperatures, the probability of accepting worse moves decreases. The algorithm becomes more “conservative,” mostly accepting moves that improve or minimally worsen the solution.
- As TT approaches zero, the probability of accepting any move that increases the objective function (worsens the solution) approaches zero.
- This allows the algorithm to “settle” around a minimum, refining the solution rather than jumping to more exploratory moves.
Effect of Temperature on Probability (Acceptance of Worse Moves)
The acceptance probability PP of a worse move (when ΔE>0ΔE>0) is given by:
P=e−ΔE/TP=e−ΔE/T
- At high TT: The term ΔE/TΔE/T is small, so e−ΔE/Te−ΔE/T is closer to 1, meaning higher acceptance probability.
- At low TT: ΔE/TΔE/T becomes larger, making e−ΔE/Te−ΔE/T closer to 0, resulting in a lower acceptance probability.
Summary
The temperature difference controls the exploration vs. exploitation balance:
- High temperature favors exploration, allowing the algorithm to escape local optima.
- Low temperature favors exploitation, encouraging convergence toward a (hopefully global) minimum.
In practice, simulated annealing starts with a high temperature that gradually cools down, allowing broad exploration initially and focused optimization as it nears a solution.
4o
You said:
why is delta e minus 1 ?
ChatGPT said:
ChatGPT
In simulated annealing, ΔEΔE represents the change in the objective function when making a move. For an optimization problem where the goal is to minimize, ΔEΔE is calculated as:
ΔE=New Energy (after move)−Current EnergyΔE=New Energy (after move)−Current Energy
In this case, ΔEΔE being -1 would mean that the move decreases the objective function (i.e., reduces the number of attacks by 1). This is a favorable move because it reduces the problem’s “energy” (or improves the solution).
Here’s how we interpret ΔE=−1ΔE=−1 specifically in the context of simulated annealing:
- When ΔE<0ΔE<0: The move improves the solution, so it is always accepted because it brings the solution closer to the minimum.
- When ΔE>0ΔE>0: The move worsens the solution, but it can still be accepted with a probability P=e−ΔE/TP=e−ΔE/T, which depends on the temperature TT.
So, if ΔE=−1ΔE=−1, it suggests:
- The move reduces the number of attacks by 1.
- This is a favorable move, and it will be accepted outright without needing a probabilistic check.
VIPS 2 — CSP
Based on your understanding of the related definitions answer the following
- First-Fail Variable Selection Heuristic selects value that rules out fewest choices for neighbours
- Local search for CSP starts with partial assignment
- An example of implicit representation of constraints: Assignment (X1=v1, X2=v2) satisfies P iff P(v1,v2) = true
- Complete variable assignment assigns to each variable a value that does not violate any constraints of CSP
- In a CSP, different variables can have different domains
- In local search for CSP, a state is any variable assignment
ChatGPT said:
ChatGPT
Here are the answers based on standard definitions in constraint satisfaction problems (CSP):
-
First-Fail Variable Selection Heuristic selects value that rules out fewest choices for neighbors
False
The first-fail heuristic generally selects the variable that is most constrained (has the fewest legal values remaining), aiming to fail early if possible. -
Local search for CSP starts with partial assignment
False
Local search in CSP typically starts with a complete, though possibly inconsistent, assignment and iteratively makes modifications to reduce constraint violations. -
An example of implicit representation of constraints: Assignment (X1=v1, X2=v2) satisfies P iff P(v1,v2) = true
True
This is an implicit constraint representation where the constraint satisfaction is evaluated through a predicate (function) rather than explicitly listing allowed pairs. -
Complete variable assignment assigns to each variable a value that does not violate any constraints of CSP
False -
In a CSP, different variables can have different domains
True
CSPs allow variables to have different domains, as each variable’s domain is independently defined. -
In local search for CSP, a state is any variable assignment
True
In local search, a state is defined by an assignment to the variables, even if it may not satisfy all constraints initially.
4o
You said:
explain each point with more words. i dont get it
ChatGPT said:
ChatGPT
Let’s go through each point in more detail to clarify:
-
First-Fail Variable Selection Heuristic selects the value that rules out the fewest choices for neighbors
Answer: False- The “First-Fail” heuristic is a method in constraint satisfaction problems (CSPs) that selects the variable with the fewest possible legal values remaining. This approach aims to identify constraints early on. By choosing the most constrained variable, the algorithm tries to detect failures quickly if there are inconsistencies in the variable’s potential values, thus saving time by avoiding exploring paths that will ultimately fail.
- In this statement, it says that the First-Fail heuristic selects values that rule out the fewest choices for neighbors, which is incorrect. Instead, First-Fail focuses on finding the variable most likely to fail and doesn’t prioritize minimizing the impact on neighboring variables.
-
Local search for CSP starts with a partial assignment
Answer: False- In local search for CSPs, the algorithm typically begins with a complete assignment, meaning that every variable has been assigned a value, though this assignment may not satisfy all constraints. The algorithm then iteratively adjusts this assignment, seeking to minimize the number of constraint violations (conflicts) until it finds an assignment that satisfies all constraints.
- A partial assignment, where only some variables are assigned, is not usually the starting point in local search. Starting with a complete assignment allows the search to focus on adjusting specific variables rather than expanding the assignment further.
-
An example of implicit representation of constraints: Assignment (X1=v1, X2=v2) satisfies P if and only if P(v1, v2) = true
Answer: True- In constraint satisfaction, constraints can be represented in two main ways: explicitly (listing all allowed combinations) and implicitly (using a function or rule to evaluate whether a combination satisfies the constraint). This statement describes an implicit representation.
- Here, the constraint is implicitly defined by a predicate PP. For example, if P(v1,v2)P(v1,v2) evaluates to true, the assignment X1=v1X1=v1 and X2=v2X2=v2 is considered valid. Rather than listing all valid assignments, we check if each assignment satisfies PP, making it implicit.
-
Complete variable assignment assigns to each variable a value that does not violate any constraints of CSP
Answer: True- A complete variable assignment in CSP means that every variable in the problem has been assigned a value, and none of these values conflict with the problem’s constraints. For example, in a Sudoku puzzle, a complete assignment means all cells are filled, and the numbers follow Sudoku rules.
- In this context, a complete assignment is valid only if no constraints are violated—meaning all conditions are satisfied by the assignment. If a complete assignment violates even a single constraint, it’s not a solution to the CSP.
-
In a CSP, different variables can have different domains
Answer: True- In CSPs, each variable can have its own domain, which is the set of values it can take. For example, in a scheduling CSP, one variable might represent time slots, while another could represent locations. These variables would naturally have different domains.
- This flexibility allows CSPs to model a variety of real-world problems where each variable may operate within a unique set of possibilities.
-
In local search for CSP, a state is any variable assignment
Answer: True- In local search for CSP, the term “state” refers to any assignment of values to variables, even if some constraints are violated. Local search methods, like hill climbing or simulated annealing, modify this assignment iteratively to reduce the number of violations.
- Unlike backtracking, which builds solutions incrementally, local search operates on full states and tries to “repair” them, moving toward a solution by adjusting values until all constraints are satisfied.
I hope this gives more context! Each point refers to standard definitions and methods in CSP, which are common in AI and optimization fields. Let me know if any part is still unclear.
4o
You said:
What are good reasons to apply local consistency concepts like Node Consistency and Arc Consistency?
- If a CSP is node, arc and path consistent, it is consistent.
- They simplify the CSP by decreasing the domain of variables.
- They simplify the CSP by decreasing the number of variables.
- If the domain of a variable becomes empty while establishing local consistency, we know that the CSP is inconsistent.
- If the domain of all variables remains unchanged while establishing local consistency, we know that the CSP is consistent.
ChatGPT said:
ChatGPT
Let’s go through each question to understand the reasons behind applying local consistency concepts in CSPs and answer the statements accordingly.
Reasons to Apply Local Consistency Concepts in CSPs
Local consistency concepts, such as Node Consistency, Arc Consistency, and Path Consistency, are used to simplify a CSP by filtering out values from variable domains that cannot be part of any valid solution. Here’s why applying these concepts is beneficial:
- Pruning Search Space: By enforcing local consistency, we reduce the possible values (domains) that each variable can take, making the CSP simpler and smaller. This decreases the number of possibilities the algorithm needs to consider, leading to a faster solution.
- Early Detection of Inconsistencies: Local consistency can reveal inconsistencies before a full solution is attempted. For example, if enforcing Arc Consistency results in an empty domain for any variable, we know the CSP is unsolvable without further search.
- Guiding Search Algorithms: Reduced domains from local consistency make search algorithms (like backtracking) more efficient by limiting their choices, often reducing the need for backtracking.
- Cost-Efficiency: Local consistency techniques are relatively inexpensive compared to full consistency checks and provide significant reductions in complexity, which makes them highly valuable for large CSPs where full consistency checks are computationally expensive.
Evaluating the Statements
Now, let’s evaluate each statement with this understanding:
-
If a CSP is node, arc, and path consistent, it is consistent.
Answer: No- Local consistency (node, arc, path) does not guarantee global consistency (full solution). Even if a CSP is node, arc, and path consistent, there may still be assignments that violate some constraints across larger variable groups. Higher-order consistency checks, like k-consistency, are required to ensure full consistency, especially in complex CSPs.
-
They simplify the CSP by decreasing the domain of variables.
Answer: Yes- One of the primary benefits of applying local consistency is reducing the size of each variable’s domain by removing values that cannot satisfy constraints. This pruning reduces the complexity of the problem and the number of values each variable must consider during search.
-
They simplify the CSP by decreasing the number of variables.
Answer: No- Local consistency techniques focus on reducing the domains of variables, not the number of variables. The number of variables remains unchanged; rather, the possible values for each variable are reduced, which simplifies the CSP without removing variables from the problem.
-
If the domain of a variable becomes empty while establishing local consistency, we know that the CSP is inconsistent.
Answer: Yes- When a variable’s domain is reduced to an empty set during local consistency (e.g., Arc Consistency), it indicates there is no value that satisfies the constraints for that variable. This immediately shows the CSP is unsolvable, as at least one constraint cannot be satisfied with the available values.
-
If the domain of all variables remains unchanged while establishing local consistency, we know that the CSP is consistent.
Answer: No- Even if the domains remain unchanged during local consistency, this does not imply that the CSP is fully consistent or has a solution. Local consistency only provides limited guarantees (e.g., each individual constraint is satisfied for arc consistency), but it doesn’t ensure a complete solution for all constraints together. Full consistency requires global checks.
Summary of Answers:
- If a CSP is node, arc, and path consistent, it is consistent. — No
- They simplify the CSP by decreasing the domain of variables. — Yes
- They simplify the CSP by decreasing the number of variables. — No
- If the domain of a variable becomes empty while establishing local consistency, we know that the CSP is inconsistent. — Yes
- If the domain of all variables remains unchanged while establishing local consistency, we know that the CSP is consistent. — No
These answers reflect the purpose and limitations of local consistency in CSPs, balancing simplification and partial problem-solving without guaranteeing a full solution.
4o
You said:
Which of the following statements are true for the Local Search formulation of CSPs discussed in the course? Suppose that the CSP has n variables and m constraints. answer detailed When our local search algorithm finds a solution with value n, it found a consistent assignment and the CSP is consistent. When our local search algorithm finds a solution with value m, it found a consistent assignment and the CSP is consistent. When our local search algorithm finds a solution with value less than n, there is no consistent assignment and the CSP is inconsistent. When our local search algorithm finds a solution with value less than m, there is no consistent assignment and the CSP is inconsistent.
ChatGPT said:
ChatGPT
In the context of local search for CSPs, we need to carefully consider what “values” mean in this context. Typically, local search algorithms for CSPs are designed to minimize the number of constraint violations rather than directly maximize or minimize some target “value.” Let’s assume that here, the “value” represents the number of satisfied constraints or a measure related to constraints and assignments.
Evaluating Each Statement
-
When our local search algorithm finds a solution with value nn, it found a consistent assignment and the CSP is consistent.
Answer: False- In a CSP, consistency means that all constraints are satisfied. Here, nn refers to the number of variables, not constraints. The value nn does not indicate the total constraints satisfied; thus, finding a solution with a value equal to nn does not imply that all constraints have been satisfied. Therefore, this statement is false because a solution with nn satisfied assignments does not guarantee that all constraints are met.
-
When our local search algorithm finds a solution with value mm, it found a consistent assignment and the CSP is consistent.
Answer: True- In this context, mm represents the number of constraints. If a solution has a value of mm, it implies that all mm constraints are satisfied, resulting in a consistent assignment. This indicates that the algorithm has found a solution that satisfies all constraints, so the CSP is consistent, making this statement true.
-
When our local search algorithm finds a solution with value less than nn, there is no consistent assignment and the CSP is inconsistent.
Answer: False- Here, having a value less than nn does not necessarily mean that the CSP is inconsistent; it simply means that not all variables meet some condition (perhaps some assignments don’t fully meet the constraints). Since nnpertains to the number of variables, achieving a value less than nn could be common in intermediate states of the local search. This does not confirm the CSP is unsolvable, so this statement is false.
-
When our local search algorithm finds a solution with value less than mm, there is no consistent assignment and the CSP is inconsistent.
Answer: True- A solution with a value less than mm suggests that not all constraints are satisfied. In this case, if our local search cannot satisfy all mm constraints (and we get a value less than mm), we lack a fully consistent assignment. This indicates that the CSP is inconsistent in this solution since some constraints are still violated, making this statement true.
Summary of Answers:
- When our local search algorithm finds a solution with value nn, it found a consistent assignment and the CSP is consistent. — False
- When our local search algorithm finds a solution with value mm, it found a consistent assignment and the CSP is consistent. — True
- When our local search algorithm finds a solution with value less than nn, there is no consistent assignment and the CSP is inconsistent. — False
- When our local search algorithm finds a solution with value less than mm, there is no consistent assignment and the CSP is inconsistent. — True
These answers clarify that in local search for CSPs, reaching a solution that satisfies all mm constraints is the indication of a consistent assignment, while values below mm indicate remaining inconsistencies.
4o
You said:
In the context of Consistency Concepts, Backtracking Search and Local Search Backtracking search CSP can be either consistent or inconsistent the problem is j-consistent for all j ≤ k starts with empty assignment iff all pairs of nodes are arc consistent Globally optimal solution implies that CSP is consistent Node inconsistency implies that Locally optimal solution implies that CSP is inconsistent Consistency concepts delete useless elements from domains of variables
ChatGPT said:
ChatGPT
Let’s go through each concept in detail to better understand how they relate to Consistency, Backtracking Search, and Local Search in the context of CSPs. I’ll address each point individually.
1. Backtracking Search
Backtracking search is a depth-first search algorithm for CSPs that builds solutions incrementally by assigning values to variables. It performs a systematic search by backtracking whenever it encounters a constraint violation.
2. CSP can be either consistent or inconsistent
This statement is true. A CSP is consistent if there exists a solution where all variables are assigned values that satisfy all constraints. If no such solution exists, the CSP is inconsistent.
3. The problem is j-consistent for all j≤kj≤k
This is related to the concept of k-consistency in CSPs:
- A CSP is k-consistent if, for any set of kk variables, every consistent assignment to k−1k−1 of those variables can be extended to the kthkth variable.
- If a CSP is j-consistent for all j≤kj≤k, it means that the problem has some level of consistency up to kk-consistency, which can help in reducing the search space but does not guarantee a solution by itself.
4. Starts with empty assignment
This statement applies to Backtracking Search. Backtracking search begins with an empty assignment and incrementally assigns values to variables, backtracking when constraints are violated until a complete and consistent assignment is found (or determined impossible).
5. iff all pairs of nodes are arc consistent
This statement is related to Arc Consistency:
- Arc Consistency means that for every pair of connected nodes (variables) XX and YY, every value in the domain of XX has a corresponding value in the domain of YY that satisfies the binary constraint between them.
- If all pairs of nodes (variables) in a CSP are arc consistent, this does not imply a solution but ensures that no domain has values that automatically violate binary constraints, which can simplify the problem.
6. Globally optimal solution implies that CSP is consistent
This is true in the context of a CSP. If a globally optimal solution is found, it means that all constraints are satisfied, which makes the CSP consistent. In CSPs, a globally optimal solution is one that meets all constraints without conflicts.
7. Node inconsistency implies that
Node Inconsistency implies that at least one variable’s domain contains values that cannot satisfy unary constraintson that variable, making the CSP inconsistent. Node consistency is the simplest form of consistency and is necessary to ensure that each variable’s domain aligns with any unary constraints applied.
8. Locally optimal solution implies that
In the context of Local Search, a locally optimal solution does not necessarily imply global consistency. Local search techniques may converge on a solution that minimizes constraint violations but still violates some constraints. Therefore, a locally optimal solution does not guarantee that the CSP is consistent; it may simply be the best solution found within a neighborhood.
9. CSP is inconsistent
If a CSP is determined to be inconsistent, it means no complete assignment exists that can satisfy all constraints. This can happen if any consistency concept (like Node, Arc, or Path Consistency) reveals an empty domain during the process of making the CSP locally consistent.
10. Consistency concepts delete useless elements from domains of variables
This statement is true. Consistency concepts such as Node Consistency, Arc Consistency, and Path Consistency work by pruning the domains of variables, removing values that cannot possibly satisfy the constraints. This process simplifies the CSP by narrowing down each variable’s domain, potentially making it easier to find a consistent solution or detect inconsistencies early on.
Summary:
Based on these explanations:
- Backtracking search starts with an empty assignment and continues until it finds a consistent assignment or determines the CSP is inconsistent.
- Consistency concepts help by reducing domains, thereby simplifying the search.
- Globally optimal solutions imply consistency, but locally optimal solutions may not guarantee global consistency.
- If node inconsistency is detected, the CSP is inconsistent.
VIPS 3 — Vagueness (video resources)
https://www.youtube.com/watch?v=YPJ6yMMNx-s
https://www.youtube.com/watch?v=qLIYJ2NiGq0
Archive — Vagueness deep-dive (claim analysis)
Detailed analysis of specific vagueness claims (predicate extensions, fuzzy logic vs. probability).
Organized version: lernzettel_vagueness-uncertainty_30-04-26 + exam-trap questions Q123-Q125 in Questions for Methods of AI.
Vagueness and Uncertainty
Analysis of the Claims about Vagueness
1. A predicate has a vague extension if it is true only with some probability.
Answer: No
Explanation:
This claim confuses vagueness with probabilistic uncertainty. Vagueness deals with imprecise boundaries of concepts (e.g., “tall” or “heap”), whereas probability measures uncertainty due to incomplete knowledge. A vague predicate has truth values that are fuzzy (ranging continuously in ([0, 1])), not tied to probabilistic likelihoods.
2. Vagueness refers to imprecise concept boundaries.
Answer: Yes
Explanation:
This is a correct statement. Vagueness occurs when there are unclear or imprecise boundaries for a concept. For instance, the term “bald” has no sharp cutoff point for when someone is considered bald. Vagueness typically arises in natural language and deals with concepts that cannot be strictly delineated.
3. Vagueness concerns the problem that a true (proved) statement ( p ) cannot become false by evidence for its opposite ( \neg p ).
Answer: No
Explanation:
This claim does not describe vagueness but rather describes a principle of classical logic, where statements are either true or false and cannot change their truth value. Vagueness instead concerns situations where the truth value is indeterminate, fuzzy, or spans a continuum, and not strictly binary.
4. Fuzzy logic is a method for representing vagueness.
Answer: Yes
Explanation:
Fuzzy logic is explicitly designed to model vagueness by allowing truth values to range continuously between 0 and 1. This provides a formal system for handling imprecise or vague concepts, such as “slightly tall” or “mostly empty.” It is widely used in applications requiring flexible reasoning, like control systems and decision-making under vagueness.
Summary Table
| Claim | Answer | Explanation |
|---|---|---|
| A predicate has a vague extension if it is true only with some probability. | No | Confuses vagueness with probabilistic uncertainty. Vagueness concerns imprecise boundaries, not probabilistic truth values. |
| Vagueness refers to imprecise concept boundaries. | Yes | This is the core definition of vagueness. |
| Vagueness concerns the problem that ( p ) cannot become false by evidence for ( \neg p ). | No | Describes classical logic, not vagueness. Vagueness allows indeterminate truth values between 0 and 1. |
| Fuzzy logic is a method for representing vagueness. | Yes | Fuzzy logic models vagueness using a continuum of truth values. |
VL10 — Support Vector Machines (sparse notes)
Sparse personal notes — for the full treatment see lernzettel_svm_30-04-26 or Support Vector Machines.
- Feature Spaces — embed inputs into a vector space where linear separation becomes possible
- tf (term frequency) — feature representation for text data
- ID3 — algorithm that builds the shortest decision tree (greedy on information gain)
Questions
Hub: Questions for Methods of AI — 104 basic + complex Q&A, 6 NotebookLM MC sets, and 35 deep / exam-trap questions (2026 expansion) covering all topics. Includes navigation block to every Lernzettel, Quiz, and atomic note.
Study Sessions
-
pruefung_paper-transformers-search_25-05-26 — 🎯 Prüfungs-Dossier (komplett): Paper “Transformers Struggle to Learn to Search” — 7-Punkte-Verständnis-Checkliste + Anatomie (§1–§7) + 5-Min-Vortragsskript + Kritik + Einordnung. Mündl. Prüfung 01.06.
-
quiz_paper-transformers-search_28-05-26 — 🔴 Hard-Quiz zum Paper (15 harte Fragen + mündlicher Prüfungsblock OE1–OE10 in Kühnbergers Stil)
-
reviews_paper-transformers-search_28-05-26 — 📝 ICLR-2025-Peer-Reviews zum Paper zusammengefasst & zitiert (Accept/Poster, 8/8/6/5; Kritikpunkte + Rebuttals fürs Diskussionsgespräch)
-
references_paper-transformers-search_28-05-26 — 📚 Wichtigste Referenz-Paper (priorisierte Leseliste); #1 Merrill & Sabharwal (CoT-Expressivity → P) voll ausgearbeitet
-
Quiz Exam Schwerpunkte — ⭐ Oral-exam focus drill (Local Search · CSP · ML, 39 Qs, marked 🟢 Moderate / 🔴 Hard, RF/SVM focus) — English; Q1–15 fact-checked 27/05/26, Q16–39 added 28/05/26
-
quiz_local-search_2026-04-30 — Local Search quiz
-
lernzettel_local-search_30-04-26 — Lernzettel: Local Search
-
lernzettel_csp_30-04-26 — Lernzettel: Constraint Satisfaction
-
lernzettel_planning-i_30-04-26 — Lernzettel: Planning I (Classical)
-
lernzettel_planning-ii_30-04-26 — Lernzettel: Planning II (MDP)
-
lernzettel_knowledge-representation_30-04-26 — Lernzettel: Knowledge Representation I & II
-
lernzettel_vagueness-uncertainty_30-04-26 — Lernzettel: Vagueness & Uncertainty
-
lernzettel_ml-i-ii_30-04-26 — Lernzettel: Machine Learning I & II
-
lernzettel_svm_30-04-26 — Lernzettel: SVMs & Perceptron
-
lernzettel_neural-networks-deep-learning_30-04-26 — Lernzettel: Neural Networks & Deep Learning
-
quiz_local-search_30-04-26 — Quiz: Local Search (8 Qs)
-
quiz_csp_30-04-26 — Quiz: Constraint Satisfaction (7 Qs)
-
quiz_planning_30-04-26 — Quiz: Planning I & II (8 Qs)
-
quiz_knowledge-representation_30-04-26 — Quiz: Knowledge Representation (7 Qs)
-
quiz_vagueness-uncertainty_30-04-26 — Quiz: Vagueness & Uncertainty (7 Qs)
-
quiz_ml_30-04-26 — Quiz: Machine Learning I & II (7 Qs)
-
quiz_decision-trees_18-05-26 — Quiz: Decision Trees + ID3 (7 Qs)
-
quiz_svm_30-04-26 — Quiz: SVMs & Perceptron (7 Qs)
-
quiz_neural-networks_30-04-26 — Quiz: Neural Networks & Deep Learning (8 Qs)
-
quiz_mega-all-topics_23-05-26 — Mega-Quiz: All Topics (100 Qs, mixed difficulty 🟢🟡🔴) — exam-prep full course recall
-
📕 Methods-of-AI-Study-Companion.pdf — Komplettes Lern-Buch (241 S., Kindle-tauglich): alle 13 VL als Fließtext + Formeln + 27 Figures + 127-Fragen-Quiz mit Answer-Key + Paper-Kapitel (mit Local-Search-Bezug). Erstellt 24-05-26, erweitert 26-05-26. ai-generated
🖨️ Exam Cheat Sheets (printable, 1 Seite je Thema)
Fokus-Themen für die mündliche Prüfung — English, mit den wichtigsten Figures. PDFs liegen im Ordner Methods of AI/ und auf dem Desktop. ai-generated
- 🖨️ Cheatsheet_Local-Search.pdf — Local Search: HC-Varianten, Simulated Annealing, Beam vs. parallel HC, Genetic Algorithms, Exam-Traps
- 🖨️ Cheatsheet_CSP.pdf — Constraint Satisfaction: Node/Arc-Consistency, AC-3 (), MRV/Degree/LCV, RCC-8, Min-Conflicts
- 🖨️ Cheatsheet_Machine-Learning.pdf — Machine Learning: Bias-Variance, Decision Trees/Entropy, Bagging & Random Forest, SVM/Soft-Margin/Kernel/RBF
- 🖨️ Cheatsheet_Paper-Transformers-Search.pdf — Paper „Transformers Struggle to Learn to Search”: Path-Merging, Ergebnisse, Kritik, Bezug zu (Local) Search
- lernzettel_classical-search_31-05-26 — Classical Search Background (BFS, DFS, A*) — kommt in der Vorlesung nur am Rand vor; Hintergrundwissen für Q14 (Path-Merging vs. BFS/DFS/A*)
see also
Course-level MOCs
Sibling course notes
Meta
Tags: methods-of-ai moc course-index
Created: 14-11-24 10:49 · Restructured: 18-05-26