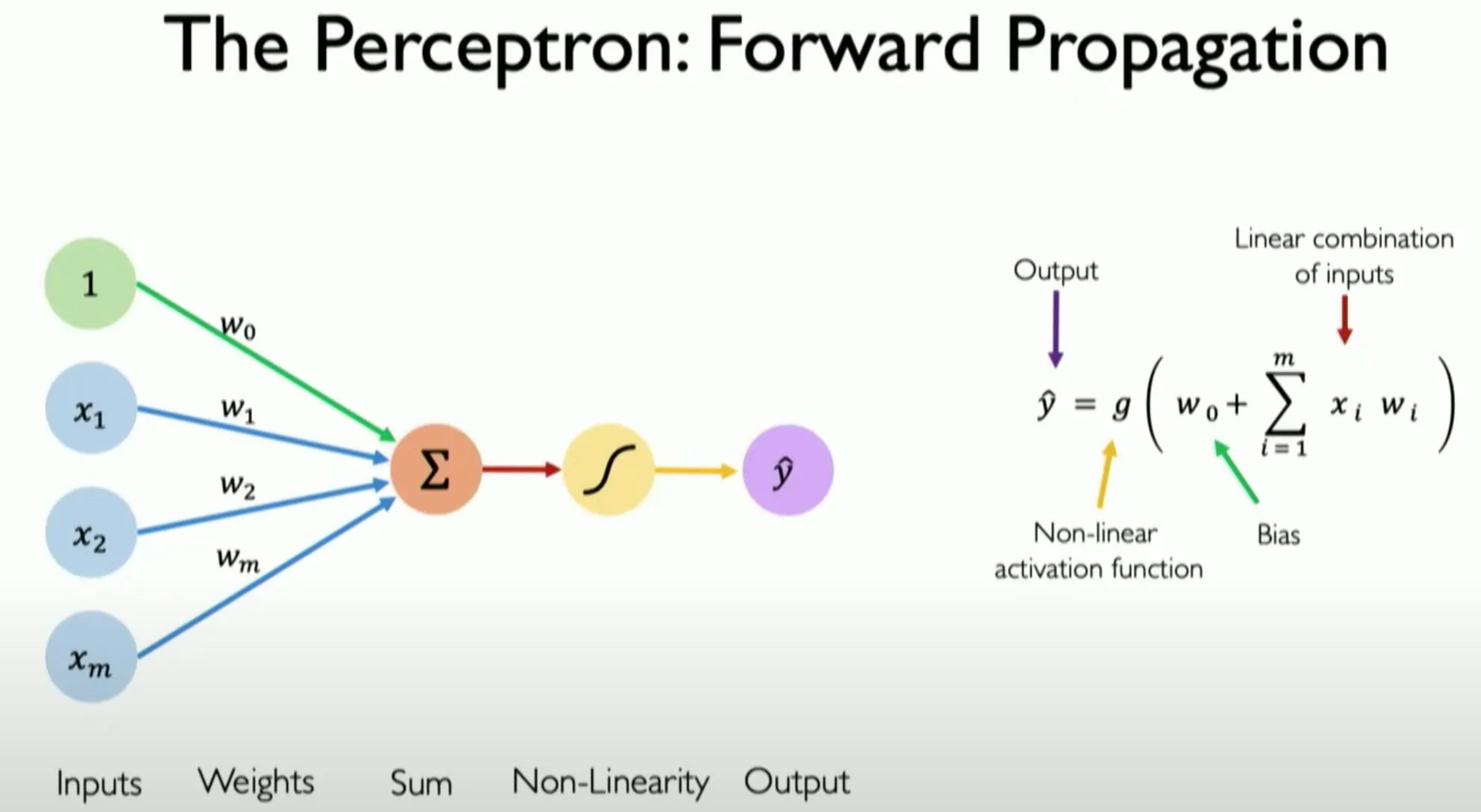
The perceptron is a simple neural network that serves as a foundational model in neuroinformatics. It is an abstraction of the functioning of a biological neuron.
It is a model for supervised learning and serves as a building block for more complex neural networks like the multilayer perceptron (MLP).
A perceptron can process binary inputs and output a binary classification.
Structure of a Perceptron
A perceptron consists of the following components:
Input values: The perceptron receives multiple inputs, which can be represented as real numbers.
Weights: Each input is multiplied by a weight that determines the significance of each input for the calculation of the result. The weights correspond to synaptic connections in a biological neuron.
Weighted Sum: The weighted inputs are summed up. This sum is also referred to as “pre-activation.”
Activation Function: The weighted sum is passed through an activation function, which determines whether the neuron “fires.”
Threshold: The activation function compares the weighted sum with a threshold. If the sum exceeds this value, the perceptron outputs a 1; otherwise, it outputs a 0.
Output Value: The result of the activation function is the output value of the perceptron, representing a binary classification.
Mathematical Representation
The pre-activation (s) is calculated as follows:
s = w₀ + w₁x₁ + w₂x₂ + … + wₙxₙ, where wᵢ are the weights and xᵢ are the inputs.
To simplify notation, a constant component can be added to the input vector:
s = w⃗ ⋅ x⃗
The activation (output y) is calculated as follows:
y = Θ(s), where Θ is a threshold function.
y = 1, if s ≥ 0; otherwise y = 0.
Alternatively, a threshold T can be used: y = 1 if s > T, otherwise y = 0.
Operation and Training
The primary task of a perceptron is to classify inputs. It learns by adjusting its weights and bias.
Bias: The bias helps define the classification threshold and shifts the decision boundary.
Training Data: Perceptrons are trained with a labeled dataset, where each input is associated with a target value.
Training Process:
The perceptron first calculates its prediction.
The error between the prediction and the actual target value is computed.
The weights are adjusted to minimize the error.
This process is iteratively repeated until the perceptron’s predictions are sufficiently accurate.
Learning Rule: The weights are adjusted using the following rule:
w(t+1) = w(t) - Δw
Δw = ε * (t - y(x)) * x, where ε is the learning rate, t is the target value, and y(x) is the perceptron’s prediction.
There are two modes for training:
Batch Mode: Weights are updated after computing the error for all examples in the training dataset.
Stochastic Mode: Weights are updated after computing the error for a randomly selected example.
Training converges if the learning rate is sufficiently small and the task is solvable by a perceptron.
Decision Boundary
The decision boundary of a perceptron is a hyperplane in the input space.
The hyperplane divides the input space into two regions, each associated with a class.
Data on the “positive side” of the hyperplane receive y = 1, the others y = 0.
Linear Separability
A perceptron can only classify linearly separable data, meaning the classes can be separated by a single hyperplane.
The perceptron can implement logical operations such as AND, OR, NAND, and NOR.
The XOR problem cannot be solved by a simple perceptron because it is not linearly separable. To solve the XOR problem, either the input space must be transformed or a multilayer perceptron (MLP) must be used. This can be done through a nonlinear transformation of inputs or by adding another dimension.
Importance and Limitations
The perceptron is a fundamental concept in neural networks and serves as a basis for more complex models.
Although it is simple, it has limited capabilities, as it can only learn linear functions.
The simplicity of the perceptron leads to efficient learning algorithms, but they are not suited for nonlinear problems.
In summary:
The perceptron is a fundamental neural network that solves binary classification tasks by finding a linear decision boundary (hyperplane) in the input space. Its strengths lie in its simplicity and efficient learning algorithms, but it is limited to linearly separable problems and cannot solve nonlinear problems such as XOR without additional transformations or more complex architectures.
Simulation: convergence vs. the XOR wall
🐍 Figure — Perceptron convergence on separable data vs. the XOR limit
import micropipawait micropip.install("numpy")await micropip.install("matplotlib")import matplotlib.pyplot as pltimport numpy as nprng = np.random.default_rng(7)# ---- Panel 1: linearly separable 2D data, perceptron boundary evolving ----n = 30class0 = rng.normal(loc=[1.5, 1.5], scale=0.55, size=(n, 2))class1 = rng.normal(loc=[4.0, 4.0], scale=0.55, size=(n, 2))X = np.vstack([class0, class1])y = np.array([0] * n + [1] * n)def train_perceptron(X, y, lr=0.1, epochs=8, record=None): w = np.zeros(X.shape[1]); b = 0.0 snapshots = {} for ep in range(1, epochs + 1): for xi, yi in zip(X, y): pred = 1 if np.dot(w, xi) + b > 0 else 0 err = yi - pred # perceptron learning rule w += lr * err * xi b += lr * err if record and ep in record: snapshots[ep] = (w.copy(), b) return w, b, snapshotsrecord_epochs = [1, 5, 10, 20]w, b, snaps = train_perceptron(X, y, epochs=20, record=record_epochs)preds = np.array([1 if np.dot(w, xi) + b > 0 else 0 for xi in X])acc = (preds == y).mean()fig, axes = plt.subplots(1, 2, figsize=(14, 6))ax = axes[0]ax.scatter(class0[:, 0], class0[:, 1], c="#3498db", s=45, edgecolor="black", lw=0.5, label="class 0", zorder=3)ax.scatter(class1[:, 0], class1[:, 1], c="#e74c3c", s=45, edgecolor="black", lw=0.5, label="class 1", zorder=3)xs = np.linspace(-0.5, 6, 100)def boundary(w, b, xs): return -(w[0] * xs + b) / w[1] # w0·x + w1·y + b = 0for i, ep in enumerate(record_epochs): ww, bb = snaps[ep] if abs(ww[1]) < 1e-9: continue if ep == record_epochs[-1]: ax.plot(xs, boundary(ww, bb, xs), "k-", lw=2.5, label=f"epoch {ep} (final)", zorder=2) else: ax.plot(xs, boundary(ww, bb, xs), "--", lw=1.3, alpha=0.35 + 0.12 * i, color="gray", label=f"epoch {ep}", zorder=1)ax.set_title(f"Linearly separable data — perceptron converges\n" f"final training accuracy = {acc:.0%}", fontsize=11)ax.set_xlabel("x₁"); ax.set_ylabel("x₂")ax.set_xlim(-0.5, 6); ax.set_ylim(-0.5, 6)ax.legend(loc="lower right", fontsize=8.5, framealpha=0.95)ax.grid(alpha=0.3)# ---- Panel 2: XOR — no single line separates it ----ax = axes[1]XOR = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])y_xor = np.array([0, 1, 1, 0])w2, b2, _ = train_perceptron(XOR.astype(float), y_xor, epochs=5000) # never convergesfor (x1, x2), lab in zip(XOR, y_xor): color = "#e74c3c" if lab == 1 else "#3498db" ax.scatter(x1, x2, c=color, s=320, edgecolor="black", lw=1.5, zorder=3) ax.annotate(f"{lab}", (x1, x2), color="white", ha="center", va="center", fontsize=12, fontweight="bold", zorder=4)xs2 = np.linspace(-0.5, 1.5, 50)for slope, intercept, c in [(-1, 1.5, "#888"), (-1, 0.5, "#aaa"), (1, -0.2, "#bbb")]: ax.plot(xs2, slope * xs2 + intercept, "--", color=c, lw=1.2, alpha=0.8)ax.scatter([], [], c="#e74c3c", s=80, edgecolor="black", label="class 1")ax.scatter([], [], c="#3498db", s=80, edgecolor="black", label="class 0")ax.set_title("XOR — NOT linearly separable\n" "no single straight line splits red from blue (Minsky–Papert 1969)", fontsize=11)ax.set_xlabel("x₁"); ax.set_ylabel("x₂")ax.set_xlim(-0.5, 1.5); ax.set_ylim(-0.5, 1.5)ax.legend(loc="center", fontsize=9, framealpha=0.95)ax.grid(alpha=0.3)plt.tight_layout(); plt.show()
What this shows. Left panel: a linearly separable 2D dataset where the perceptron learning rule Δw = ε·(t − y)·x is implemented from scratch and the decision boundary is recorded across epochs (faded dashed lines for early epochs, solid black for the final one). The boundary sweeps into place and reaches 100% training accuracy — this is the Perceptron Convergence Theorem (Novikoff 1962): on linearly separable data the rule is guaranteed to find a separating hyperplane in finite steps (unlike Support Vector Machines, it finds any such line, not the max-margin one). Right panel: the XOR dataset, whose 1-labels sit on opposite diagonal corners — no single straight line can separate them, so the same algorithm oscillates forever and tops out at 50% accuracy. This is the Minsky–Papert (1969) limitation that motivated hidden layers and Neural Networks & Deep Learning, where the boundary can bend. The fix is the same one used by Gradient Descent-trained MLPs.
Demo: AND learns, XOR fails
The famous Minsky-Papert (1969) result, in 25 lines. Same perceptron — same training loop — only the labels differ.
🐍 Code anzeigen / ausblenden
import numpy as npdef perceptron_train(X, y, lr=0.1, epochs=20): w = np.zeros(X.shape[1]); b = 0.0 for _ in range(epochs): for xi, yi in zip(X, y): pred = 1 if np.dot(w, xi) + b > 0 else 0 error = yi - pred # perceptron learning rule w += lr * error * xi b += lr * error return w, bdef predict(w, b, X): return [1 if np.dot(w, x) + b > 0 else 0 for x in X]X = np.array([[0,0], [0,1], [1,0], [1,1]])# AND — linearly separable → perceptron convergesy_and = np.array([0, 0, 0, 1])w, b = perceptron_train(X, y_and)print("AND target:", y_and.tolist(), "→ learned:", predict(w, b, X))# AND target: [0, 0, 0, 1] → learned: [0, 0, 0, 1] ✓# XOR — NOT linearly separable → never converges, no matter how many epochsy_xor = np.array([0, 1, 1, 0])w, b = perceptron_train(X, y_xor, epochs=10_000)print("XOR target:", y_xor.tolist(), "→ learned:", predict(w, b, X))# XOR target: [0, 1, 1, 0] → learned: [1, 1, 0, 0] ✗ (always at least one wrong)
Why XOR fails — no math needed: plot the four points on a 2D grid. AND’s 1-label sits alone in the top-right corner — one straight line separates it from the others. XOR’s 1-labels sit on opposite diagonal corners — no single straight line can separate them. The perceptron is a single straight line; an MLP adds a hidden layer that bends the boundary.
Where Perceptrons are still used today
The single-layer perceptron itself is rarely deployed standalone (Minsky-Papert 1969 killed the hype for 17 years). But the concept and the learning rule are everywhere.
As a building block in MLPs / Deep Networks — every neuron in a modern transformer is essentially a perceptron with a fancier activation function. GPT-4 is, in a sense, billions of perceptrons stacked and trained together.
Linear classifiers in NLP baselines — logistic regression (a perceptron with sigmoid output) is still the default baseline for text classification before reaching for a transformer.
Online learning systems — Perceptron-style updates (predict, get true label, adjust weights) are used in ad-click prediction (Google, Facebook) and spam filtering where the data stream is endless.
Feature-engineered linear models — Vowpal Wabbit (open-source) is essentially a fast perceptron, used by major ad tech companies for billion-event/day pipelines.
Theoretical baseline — the Perceptron Convergence Theorem (Novikoff 1962) is the first thing anyone proves in learning theory. Foundational for understanding margin, VC dimension, and learnability.
Where Perceptrons were replaced — and by what
Application
Was Perceptron, now …
Why
Non-linearly separable problems (XOR)
MLPs (Multi-Layer Perceptron)
A single hidden layer is a universal approximator (Hornik 1989); the XOR problem dissolves
Image classification
CNNs → Vision Transformers (ViT)
Spatial structure of images demands convolutions / attention, not flat perceptrons
Text classification
Transformers (BERT, GPT)
Context and word order matter; bag-of-words + perceptron loses to attention
Most modern AI
Deep neural networks trained with backprop
Single-layer linear methods can’t represent the hierarchical features deep nets discover
Margin-maximizing classification
Support Vector Machines (SVM)
SVMs maximize the margin between classes; perceptron just finds any separating hyperplane (Rosenblatt 1958)
Where perceptrons still stand: as the conceptual building block of every neural network, as the first explanation in any ML course, and in pure online learning settings where computational simplicity matters more than accuracy.