Lernzettel: Machine Learning I & II
Methods of AI — SoSe 2026 · 1-page exam sheet
For more depth: Machine Learning I & II (full reference with all algorithms, worked examples, pseudocode) · quiz_ml_30-04-26 (broad ML) · quiz_decision-trees_18-05-26 (DT/IG focused)
Core Ideas
- Mitchell: a program learns from experience E w.r.t. task T and performance measure P if P improves with E.
- Three paradigms: supervised (labels) · unsupervised (structure) · reinforcement (rewards).
- Inductive bias = prior assumptions that make generalisation possible. Without bias, no generalisation.
- Overfitting = fits training noise, fails on new data. Occam’s razor: prefer simpler models.
Mini-glossary
| Term | Meaning |
|---|---|
| Task / Performance / Experience (T, P, E) | Mitchell’s triple defining a learning problem |
| Inductive bias | minimal assumptions B such that the prediction follows deductively from D ∪ B |
| Statistical bias | systematic error from oversimplifying — DIFFERENT from inductive bias |
| Variance | error from sensitivity to training-data fluctuations |
| Entropy E(S) | impurity measure: 0 = pure, max (log₂ k) = uniform |
| Information Gain | expected entropy reduction from splitting on attribute A |
| ID3 | greedy top-down tree builder; picks max-IG attribute at each node |
| Bagging | train m models on bootstrap samples; vote/average → reduces variance |
| Random Forest | Bagging + per-split random feature subsampling |
| OOB error | free generalisation estimate using ≈ 37 % of rows not in each bootstrap |
| k-means | assign-to-nearest-centroid ⇄ recompute centroid; only finds local optimum |
| Hierarchical clustering | dendrogram from agglomerative merges; linkage = single/complete/avg/centroid |
| Cosine similarity | (x·y)/(‖x‖‖y‖); angle-only, length-invariant; standard for TF-IDF text |
| TF-IDF | tf · log(|D| / df) — downweights common terms |
| L2 / Ridge / weight decay | penalty λΣwᵢ² — shrinks all weights, none to exactly 0 |
| L1 / Lasso | penalty λΣ|wᵢ| — drives weights to exactly 0 → sparse, feature selection |
| λ (reg. strength) | hyperparameter; 0 = no penalty (overfit), ∞ = all weights 0 (underfit) |
⭐ Full glossary → Glossary — important ML vocabulary
Formulas
Entropy: E(S) = − Σ_i p_i · log₂(p_i)
Information Gain: Gain(S, A) = E(S) − Σ_v (|S_v|/|S|) · E(S_v)
Cosine sim: cos(x, y) = (x · y) / (‖x‖ · ‖y‖)
k-means cost: J = Σ_j Σ_{x∈C_j} ‖x − μ_j‖²
Bootstrap OOB: (1 − 1/n)ⁿ → 1/e ≈ 0.368
Bias-variance decomposition ⚠️ external / textbook — not in slides
E[(y − f̂(x))²] = Bias²(f̂) + Variance(f̂) + σ²
└─────┘ └────────┘ └─┘
under- over- irreducible
fitting fitting noise
Slides discuss the tradeoff qualitatively (complexity ↑ → bias ↓, variance ↑); only this formula is external.
Regularization — L1 vs L2 (added 31/05/26)
Idea: add a penalty on the size of the weights to the loss, so the optimiser can’t fit training noise with huge coefficients. You deliberately add a little bias to buy a large drop in variance (it sits on the right side of the bias-variance decomposition above).
Regularised loss: L_reg(w) = L_data(w) + λ · R(w)
L2 (Ridge): R(w) = Σ_i w_i² (= ‖w‖₂²)
L1 (Lasso): R(w) = Σ_i |w_i| (= ‖w‖₁)
- λ (lambda) = regularisation strength. λ = 0 → no penalty (back to plain fit, may overfit). λ → ∞ → all weights forced to 0 (underfit). It’s a hyperparameter → tune via validation / cross-validation.
- In neural nets, L2 = weight decay (see DL sheet, formula
L_wd = L + λ Σ‖w‖²). The SVM’s C is the inverse idea: large C → little regularisation (narrow margin), small C → more regularisation.
The key difference — what each one does to the weights:
| L2 (Ridge / weight decay) | L1 (Lasso) | |
|---|---|---|
| Penalty | Σ wᵢ² | Σ |wᵢ| |
| Gradient of penalty | 2w — shrinks proportionally | sign(w) — constant ±1 pull |
| Effect on weights | shrinks all weights toward 0, never exactly 0 | drives many weights exactly to 0 → sparse |
| Solution | unique, smooth | does implicit feature selection |
| Use when | many small effects, correlated features | you want a sparse, interpretable model |
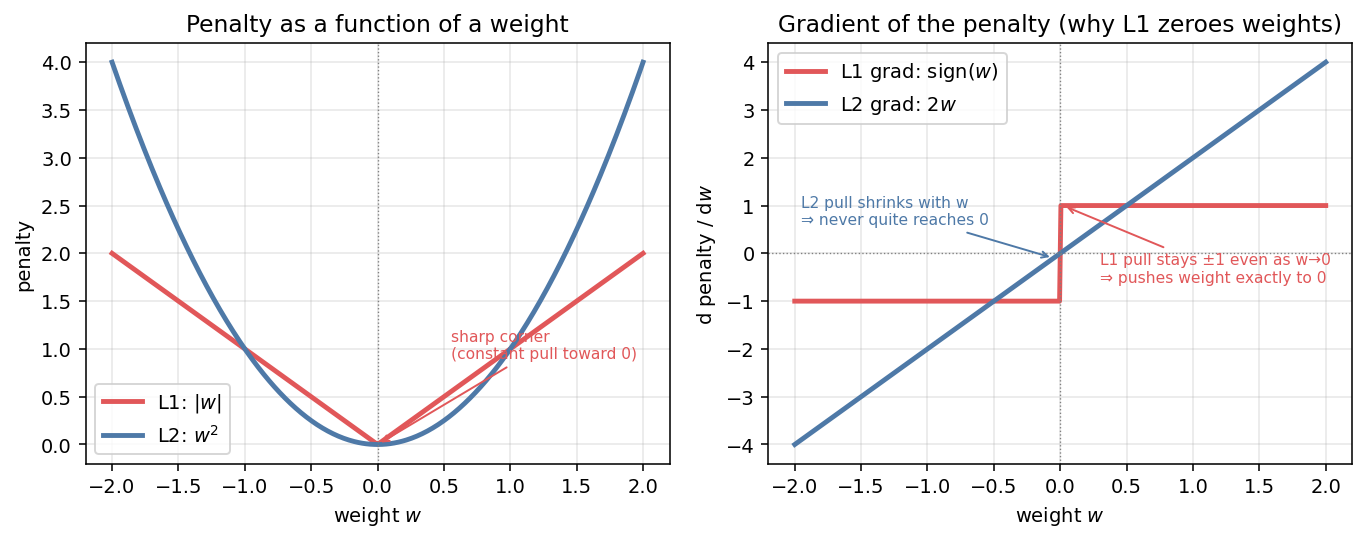
Why L1 zeroes weights but L2 doesn't (the gradient story — right panel above)
The penalty’s gradient is the “pull” toward zero. L2’s pull is
2w: as a weight gets small, the pull also gets small, so it asymptotes toward 0 but never arrives. L1’s pull issign(w) = ±1: it stays at full strength even as w → 0, so it shoves the weight clean through to exactly 0. That’s why L1 produces sparsity and L2 only shrinks.
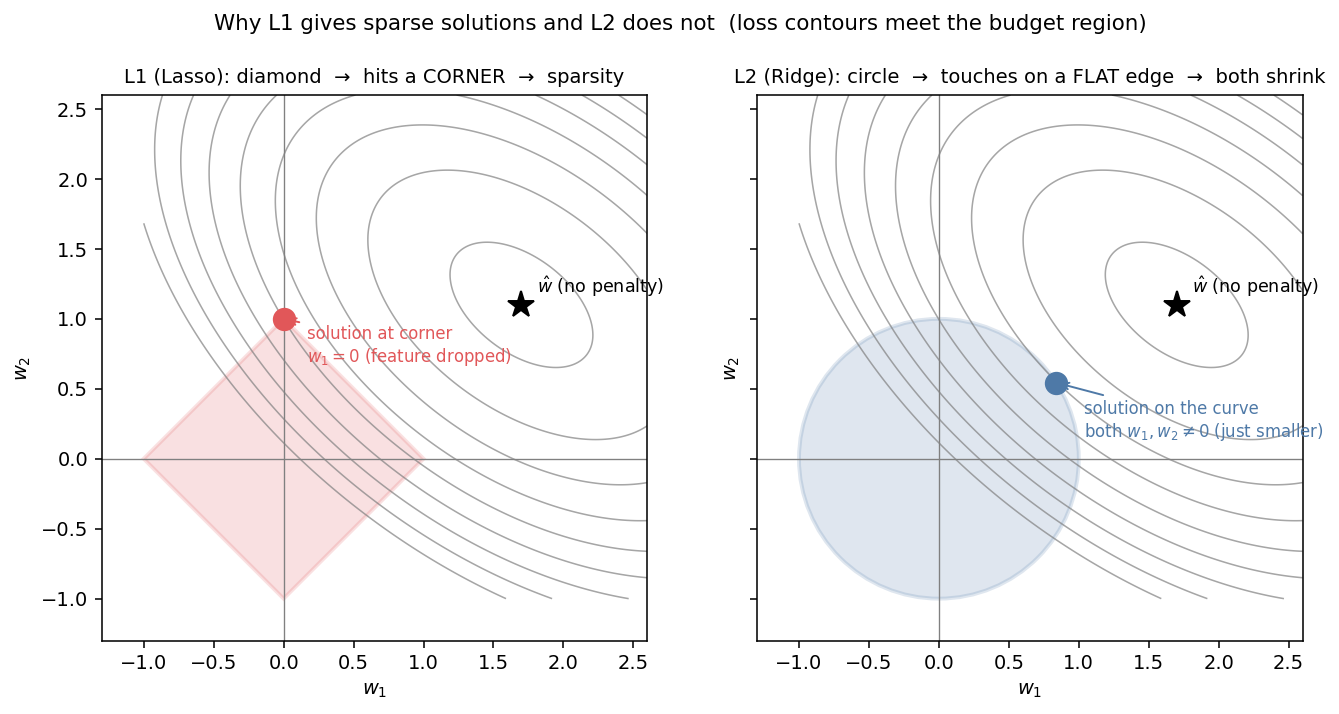
The geometric picture (the classic exam diagram — above)
Think “minimise loss subject to a budget on weight size.” The budget region is a diamond for L1 (‖w‖₁ ≤ t) and a circle for L2 (‖w‖₂ ≤ t). The elliptical loss contours grow outward from the unconstrained optimum until they first touch the budget region — that touch point is the solution.
- L1’s diamond has sharp corners on the axes → contours almost always touch at a corner → some coordinate = 0 → sparse.
- L2’s circle has no corners → the touch happens on a smooth edge → both coordinates shrink but stay nonzero.
Common Exam Traps ⚠️
- Inductive bias ≠ statistical bias. Same word, very different concepts. Read carefully.
- Random Forest ≠ Bagging. RF = Bagging + per-split feature subsampling → more decorrelated trees.
- ID3 is greedy & has no backtracking — needs pruning or ensembling to avoid overfitting.
- High-cardinality attributes (like
patient_ID) game vanilla IG → max gain but useless tree. Gain Ratio in C4.5 fixes it (external). - OOB error is free — no separate test set needed. ≈ 37 % of rows are OOB per tree.
- k-means finds local optima only — initialisation matters → run multiple times. k-means++ (external) gives smarter init.
- k-means assumes spherical, equal-size clusters — bad for elongated / variable-density data.
- Entropy = 0 ⇔ pure node; = log₂ k ⇔ uniform.
- Hierarchical merges are irreversible — a bad early merge poisons everything below.
- Cosine ignores magnitude — perfect for text length-invariance, wrong if magnitude matters.
- Supervised ≠ unsupervised ≠ RL — labels vs. structure vs. rewards.
- k-fold CV / LOO terminology is external textbook — slides talk about train/test splits but don’t name k-fold or LOO.
- L1 → sparse, L2 → small-but-nonzero. Don’t swap them. Mnemonic: Lasso Lops weights off (to 0). L2 only shrinks.
- Regularisation trades bias for variance — it raises bias slightly to cut variance. Saying “regularisation reduces bias” is backwards.
- SVM’s C is inverse strength — large C = less regularisation, not more. Easy to flip under pressure.
Quick Comparison Table
| Algorithm | Paradigm | Interpretable | Non-linear | Main risk |
|---|---|---|---|---|
| Decision Tree (ID3) | Supervised | ✅ fully | ✅ | Overfitting |
| Random Forest | Supervised | ⚠️ partial | ✅ | Many hyperparameters |
| k-means | Unsupervised | ✅ centroids | ❌ (Euclidean) | Local optima, k must be set |
| Hierarchical (HAC) | Unsupervised | ✅ dendrogram | depends on linkage | O(n²)+ cost, irreversible merges |
Full pros/cons + pseudocode for all 6 algorithms → ALGORITHMS (full reference) ⭐
Related Q&A & Notes
Quizzes
- quiz_ml_30-04-26 — 7 Qs (broad ML methodology + DT/RF)
- quiz_decision-trees_18-05-26 — 7 Qs (focused: entropy, IG, traps, ensembles)
Targeted exam questions in Questions for Methods of AI
- Q64–73 (basic: supervised/unsupervised/RL, decision trees, ID3, Random Forest, bias-variance) · Q92 (supervised vs. unsupervised vs. RL) · Q93 (Decision Tree vs. Random Forest) · Q103 (MSE loss) · Q126–129 (deep / exam-trap: bias-variance decomposition derivation, ID3 high-cardinality overfitting, why bagging reduces variance not bias, OOB error mechanism)
Atomic notes
- Machine Learning · Bias-Variance Tradeoff · Decision Trees and ID3 · Random Forest · Perceptron · Machine Learning for Cognitive Computational Neuroscience · Complementary Learning Systems
See also (sibling Lernzettel)
- lernzettel_svm_30-04-26 — ML III: SVMs & Perceptron
- lernzettel_neural-networks-deep-learning_30-04-26 — Neural Networks & Deep Learning
See also
Tags: methods-of-ai lernzettel ai-generated
Full reference: Machine Learning I & II
Quizzes: quiz_ml_30-04-26 · quiz_decision-trees_18-05-26
Superlink: Methods of AI Lecture
Questions hub: Questions for Methods of AI
Created: 30/04/26